 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaliGemma: A versatile 3B VLM for transfer
Jul 10, 2024



PaliGemma is an open Vision-Language Model (VLM) that is based on the SigLIP-So400m vision encoder and the Gemma-2B language model. It is trained to be a versatile and broadly knowledgeable base model that is effective to transfer. It achieves strong performance on a wide variety of open-world tasks. We evaluate PaliGemma on almost 40 diverse tasks including standard VLM benchmarks, but also more specialized tasks such as remote-sensing and segmentation.
Improving fine-grained understanding in image-text pre-training
Jan 18, 2024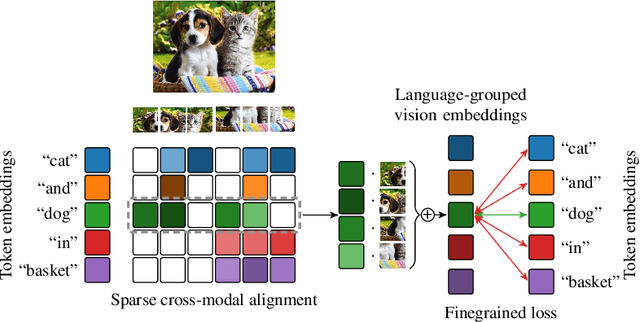
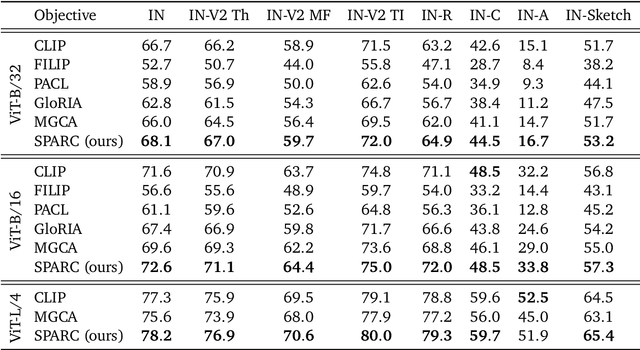
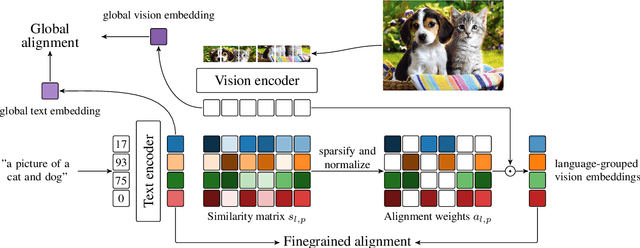
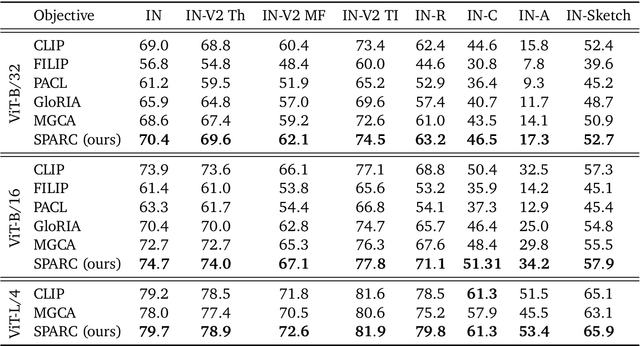
We introduce SPARse Fine-grained Contrastive Alignment (SPARC), a simple method for pretraining more fine-grained multimodal representations from image-text pairs. Given that multiple image patches often correspond to single words, we propose to learn a grouping of image patches for every token in the caption. To achieve this, we use a sparse similarity metric between image patches and language tokens and compute for each token a language-grouped vision embedding as the weighted average of patches. The token and language-grouped vision embeddings are then contrasted through a fine-grained sequence-wise loss that only depends on individual samples and does not require other batch samples as negatives. This enables more detailed information to be learned in a computationally inexpensive manner. SPARC combines this fine-grained loss with a contrastive loss between global image and text embeddings to learn representations that simultaneously encode global and local information. We thoroughly evaluate our proposed method and show improved performance over competing approaches both on image-level tasks relying on coarse-grained information, e.g. classification, as well as region-level tasks relying on fine-grained information, e.g. retrieval, object detection, and segmentation. Moreover, SPARC improves model faithfulness and captioning in foundational vision-language models.
SemPPL: Predicting pseudo-labels for better contrastive representations
Jan 12, 2023Learning from large amounts of unsupervised data and a small amount of supervision is an important open problem in computer vision. We propose a new semi-supervised learning method, Semantic Positives via Pseudo-Labels (SemPPL), that combines labelled and unlabelled data to learn informative representations. Our method extends self-supervised contrastive learning -- where representations are shaped by distinguishing whether two samples represent the same underlying datum (positives) or not (negatives) -- with a novel approach to selecting positives. To enrich the set of positives, we leverage the few existing ground-truth labels to predict the missing ones through a $k$-nearest neighbours classifier by using the learned embeddings of the labelled data. We thus extend the set of positives with datapoints having the same pseudo-label and call these semantic positives. We jointly learn the representation and predict bootstrapped pseudo-labels. This creates a reinforcing cycle. Strong initial representations enable better pseudo-label predictions which then improve the selection of semantic positives and lead to even better representations. SemPPL outperforms competing semi-supervised methods setting new state-of-the-art performance of $68.5\%$ and $76\%$ top-$1$ accuracy when using a ResNet-$50$ and training on $1\%$ and $10\%$ of labels on ImageNet, respectively. Furthermore, when using selective kernels, SemPPL significantly outperforms previous state-of-the-art achieving $72.3\%$ and $78.3\%$ top-$1$ accuracy on ImageNet with $1\%$ and $10\%$ labels, respectively, which improves absolute $+7.8\%$ and $+6.2\%$ over previous work. SemPPL also exhibits state-of-the-art performance over larger ResNet models as well as strong robustness, out-of-distribution and transfer performance.
A Generalist Neural Algorithmic Learner
Sep 22, 2022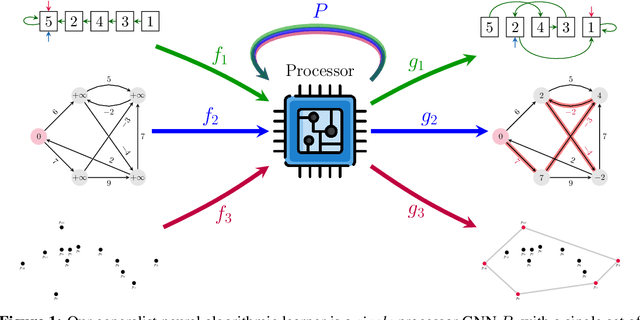
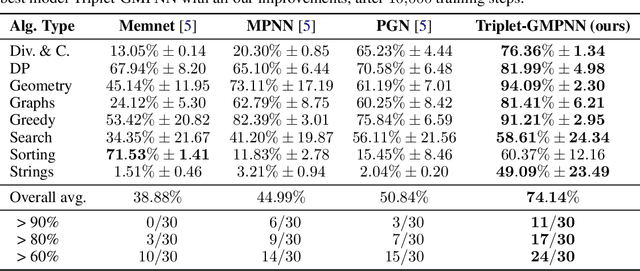
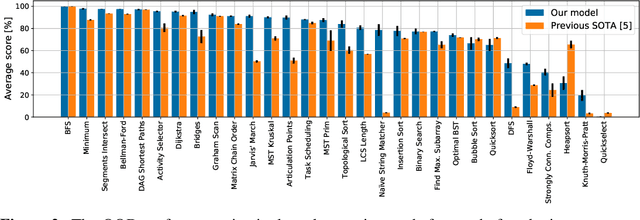
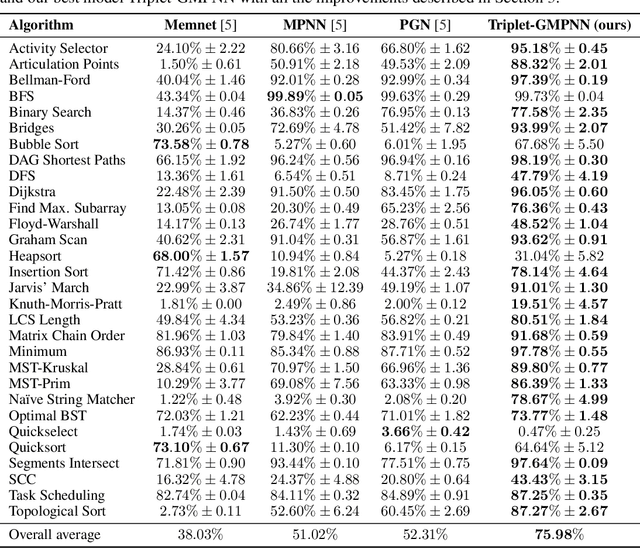
The cornerstone of neural algorithmic reasoning is the ability to solve algorithmic tasks, especially in a way that generalises out of distribution. While recent years have seen a surge in methodological improvements in this area, they mostly focused on building specialist models. Specialist models are capable of learning to neurally execute either only one algorithm or a collection of algorithms with identical control-flow backbone. Here, instead, we focus on constructing a generalist neural algorithmic learner -- a single graph neural network processor capable of learning to execute a wide range of algorithms, such as sorting, searching, dynamic programming, path-finding and geometry. We leverage the CLRS benchmark to empirically show that, much like recent successes in the domain of perception, generalist algorithmic learners can be built by "incorporating" knowledge. That is, it is possible to effectively learn algorithms in a multi-task manner, so long as we can learn to execute them well in a single-task regime. Motivated by this, we present a series of improvements to the input representation, training regime and processor architecture over CLRS, improving average single-task performance by over 20% from prior art. We then conduct a thorough ablation of multi-task learners leveraging these improvements. Our results demonstrate a generalist learner that effectively incorporates knowledge captured by specialist models.
Reasoning-Modulated Representations
Jul 19, 2021
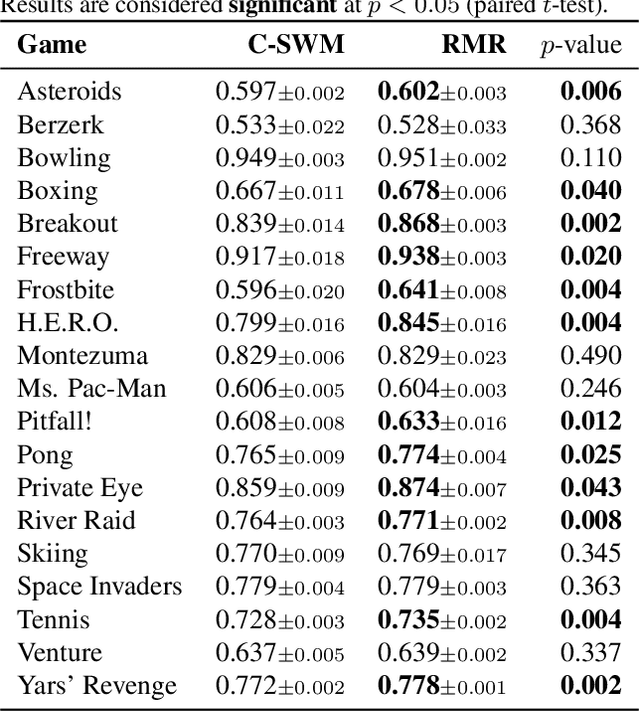


Neural networks leverage robust internal representations in order to generalise. Learning them is difficult, and often requires a large training set that covers the data distribution densely. We study a common setting where our task is not purely opaque. Indeed, very often we may have access to information about the underlying system (e.g. that observations must obey certain laws of physics) that any "tabula rasa" neural network would need to re-learn from scratch, penalising data efficiency. We incorporate this information into a pre-trained reasoning module, and investigate its role in shaping the discovered representations in diverse self-supervised learning settings from pixels. Our approach paves the way for a new class of data-efficient representation learning.
Differentiable Reasoning on Large Knowledge Bases and Natural Language
Dec 17, 2019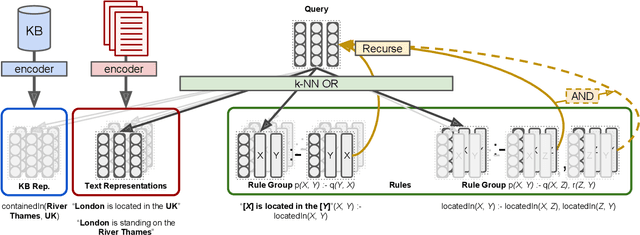



Reasoning with knowledge expressed in natural language and Knowledge Bases (KBs) is a major challenge for Artificial Intelligence, with applications in machine reading, dialogue, and question answering. General neural architectures that jointly learn representations and transformations of text are very data-inefficient, and it is hard to analyse their reasoning process. These issues are addressed by end-to-end differentiable reasoning systems such as Neural Theorem Provers (NTPs), although they can only be used with small-scale symbolic KBs. In this paper we first propose Greedy NTPs (GNTPs), an extension to NTPs addressing their complexity and scalability limitations, thus making them applicable to real-world datasets. This result is achieved by dynamically constructing the computation graph of NTPs and including only the most promising proof paths during inference, thus obtaining orders of magnitude more efficient models. Then, we propose a novel approach for jointly reasoning over KBs and textual mentions, by embedding logic facts and natural language sentences in a shared embedding space. We show that GNTPs perform on par with NTPs at a fraction of their cost while achieving competitive link prediction results on large datasets, providing explanations for predictions, and inducing interpretable models. Source code, datasets, and supplementary material are available online at https://github.com/uclnlp/gntp.
Jack the Reader - A Machine Reading Framework
Jun 20, 2018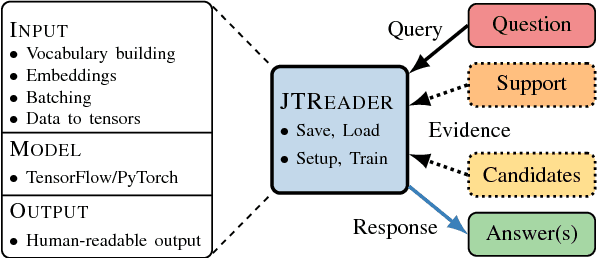
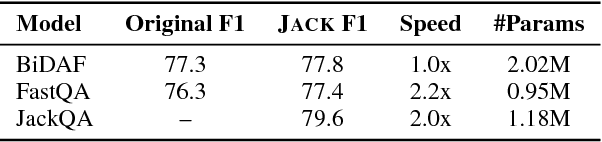

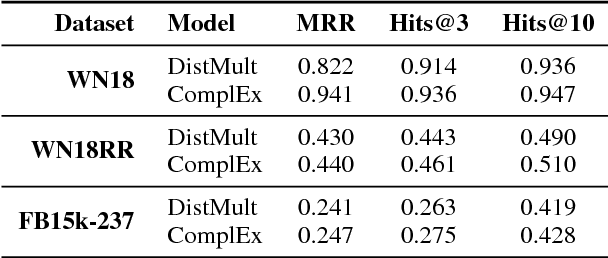
Many Machine Reading and Natural Language Understanding tasks require reading supporting text in order to answer questions. For example, in Question Answering, the supporting text can be newswire or Wikipedia articles; in Natural Language Inference, premises can be seen as the supporting text and hypotheses as questions. Providing a set of useful primitives operating in a single framework of related tasks would allow for expressive modelling, and easier model comparison and replication. To that end, we present Jack the Reader (Jack), a framework for Machine Reading that allows for quick model prototyping by component reuse, evaluation of new models on existing datasets as well as integrating new datasets and applying them on a growing set of implemented baseline models. Jack is currently supporting (but not limited to) three tasks: Question Answering, Natural Language Inference, and Link Prediction. It is developed with the aim of increasing research efficiency and code reuse.
Programming with a Differentiable Forth Interpreter
Jul 23, 2017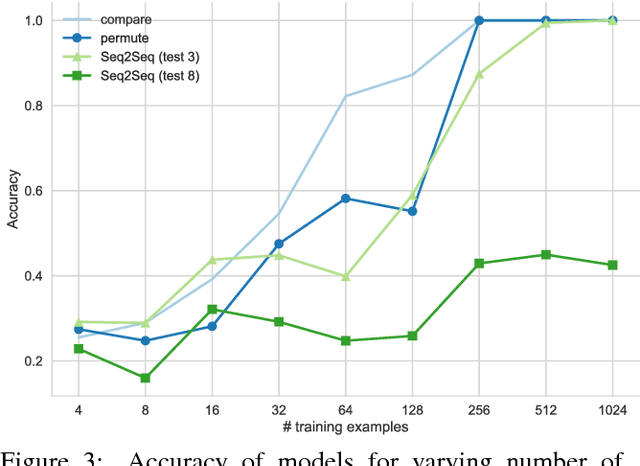
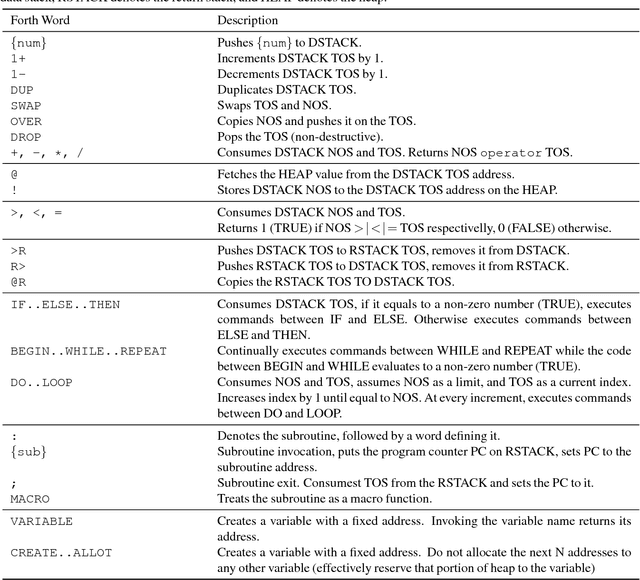
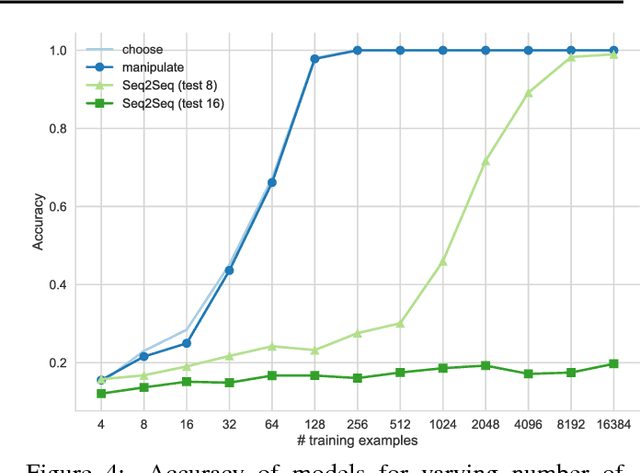
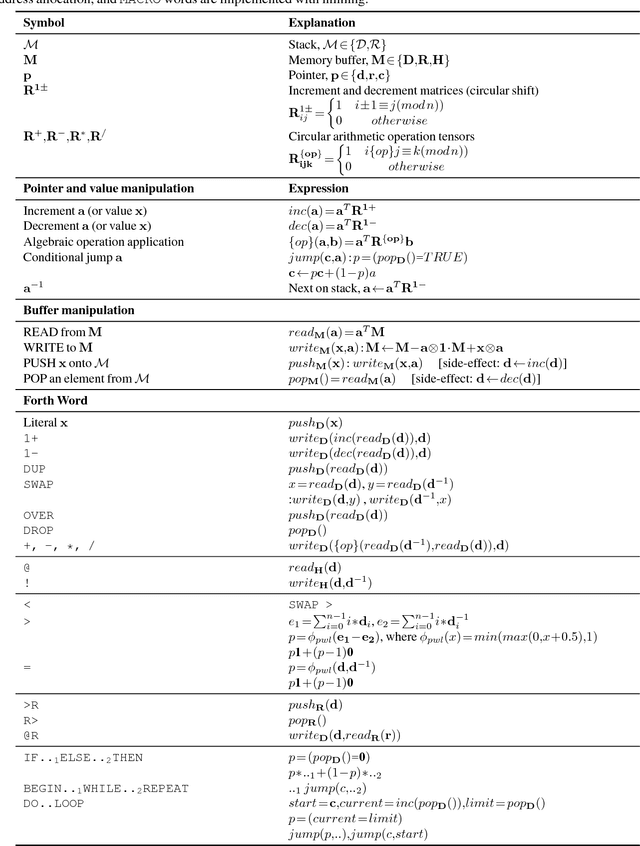
Given that in practice training data is scarce for all but a small set of problems, a core question is how to incorporate prior knowledge into a model. In this paper, we consider the case of prior procedural knowledge for neural networks, such as knowing how a program should traverse a sequence, but not what local actions should be performed at each step. To this end, we present an end-to-end differentiable interpreter for the programming language Forth which enables programmers to write program sketches with slots that can be filled with behaviour trained from program input-output data. We can optimise this behaviour directly through gradient descent techniques on user-specified objectives, and also integrate the program into any larger neural computation graph. We show empirically that our interpreter is able to effectively leverage different levels of prior program structure and learn complex behaviours such as sequence sorting and addition. When connected to outputs of an LSTM and trained jointly, our interpreter achieves state-of-the-art accuracy for end-to-end reasoning about quantities expressed in natural language stories.
emoji2vec: Learning Emoji Representations from their Description
Nov 20, 2016
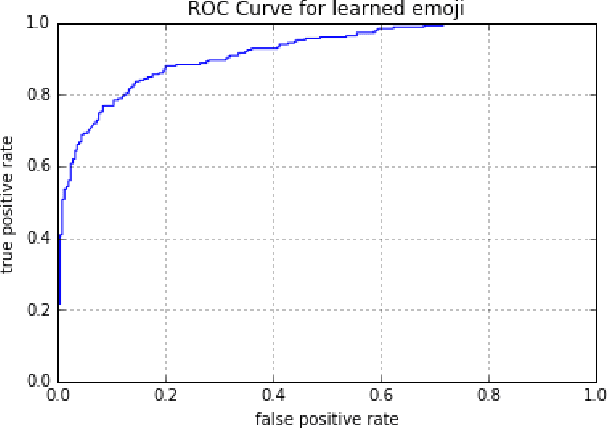

Many current natural language processing applications for social media rely on representation learning and utilize pre-trained word embeddings. There currently exist several publicly-available, pre-trained sets of word embeddings, but they contain few or no emoji representations even as emoji usage in social media has increased. In this paper we release emoji2vec, pre-trained embeddings for all Unicode emoji which are learned from their description in the Unicode emoji standard. The resulting emoji embeddings can be readily used in downstream social natural language processing applications alongside word2vec. We demonstrate, for the downstream task of sentiment analysis, that emoji embeddings learned from short descriptions outperforms a skip-gram model trained on a large collection of tweets, while avoiding the need for contexts in which emoji need to appear frequently in order to estimate a representation.