 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Mar 12, 2024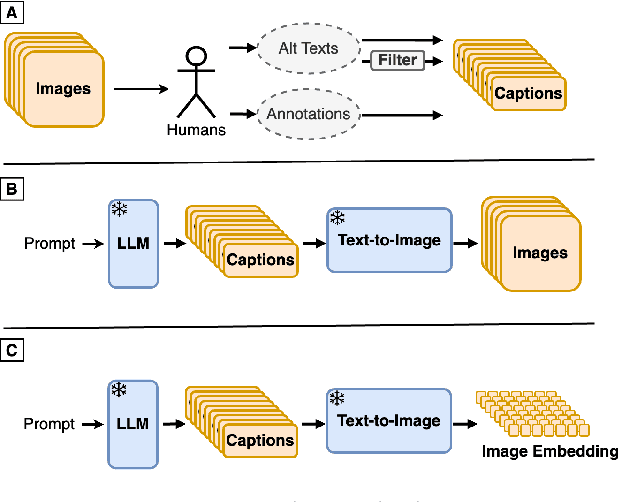
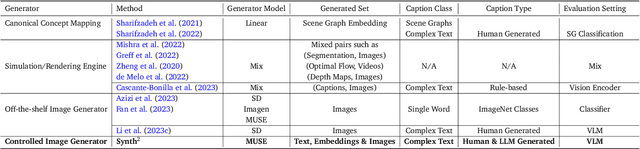


The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). We propose a novel approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs pretraining a text-to-image model to synthesize image embeddings starting from captions generated by an LLM. These synthetic pairs are then used to train a VLM. Extensive experiments demonstrate that the VLM trained with synthetic data exhibits comparable performance on image captioning, while requiring a fraction of the data used by models trained solely on human-annotated data. In particular, we outperform the baseline by 17% through augmentation with a synthetic dataset. Furthermore, we show that synthesizing in the image embedding space is 25% faster than in the pixel space. This research introduces a promising technique for generating large-scale, customizable image datasets, leading to enhanced VLM performance and wider applicability across various domains, all with improved data efficiency and resource utilization.
Neural Algorithmic Reasoning with Causal Regularisation
Feb 20, 2023



Recent work on neural algorithmic reasoning has investigated the reasoning capabilities of neural networks, effectively demonstrating they can learn to execute classical algorithms on unseen data coming from the train distribution. However, the performance of existing neural reasoners significantly degrades on out-of-distribution (OOD) test data, where inputs have larger sizes. In this work, we make an important observation: there are many \emph{different} inputs for which an algorithm will perform certain intermediate computations \emph{identically}. This insight allows us to develop data augmentation procedures that, given an algorithm's intermediate trajectory, produce inputs for which the target algorithm would have \emph{exactly} the same next trajectory step. Then, we employ a causal framework to design a corresponding self-supervised objective, and we prove that it improves the OOD generalisation capabilities of the reasoner. We evaluate our method on the CLRS algorithmic reasoning benchmark, where we show up to 3$\times$ improvements on the OOD test data.
SemPPL: Predicting pseudo-labels for better contrastive representations
Jan 12, 2023Learning from large amounts of unsupervised data and a small amount of supervision is an important open problem in computer vision. We propose a new semi-supervised learning method, Semantic Positives via Pseudo-Labels (SemPPL), that combines labelled and unlabelled data to learn informative representations. Our method extends self-supervised contrastive learning -- where representations are shaped by distinguishing whether two samples represent the same underlying datum (positives) or not (negatives) -- with a novel approach to selecting positives. To enrich the set of positives, we leverage the few existing ground-truth labels to predict the missing ones through a $k$-nearest neighbours classifier by using the learned embeddings of the labelled data. We thus extend the set of positives with datapoints having the same pseudo-label and call these semantic positives. We jointly learn the representation and predict bootstrapped pseudo-labels. This creates a reinforcing cycle. Strong initial representations enable better pseudo-label predictions which then improve the selection of semantic positives and lead to even better representations. SemPPL outperforms competing semi-supervised methods setting new state-of-the-art performance of $68.5\%$ and $76\%$ top-$1$ accuracy when using a ResNet-$50$ and training on $1\%$ and $10\%$ of labels on ImageNet, respectively. Furthermore, when using selective kernels, SemPPL significantly outperforms previous state-of-the-art achieving $72.3\%$ and $78.3\%$ top-$1$ accuracy on ImageNet with $1\%$ and $10\%$ labels, respectively, which improves absolute $+7.8\%$ and $+6.2\%$ over previous work. SemPPL also exhibits state-of-the-art performance over larger ResNet models as well as strong robustness, out-of-distribution and transfer performance.
Pushing the limits of self-supervised ResNets: Can we outperform supervised learning without labels on ImageNet?
Jan 13, 2022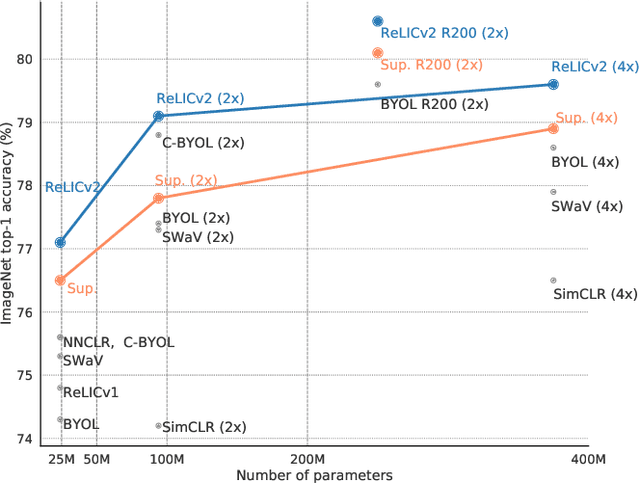
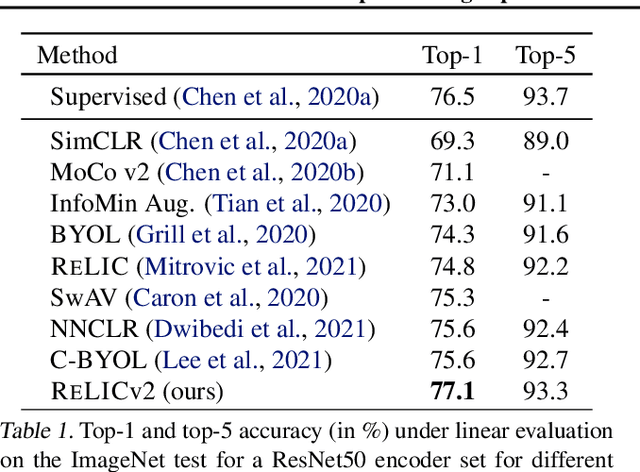
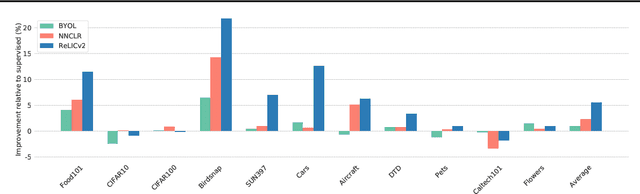
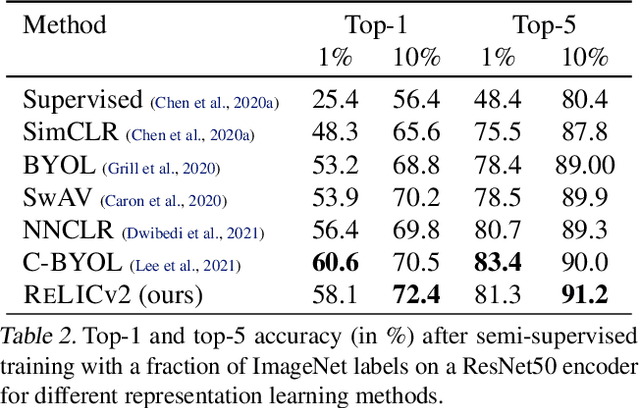
Despite recent progress made by self-supervised methods in representation learning with residual networks, they still underperform supervised learning on the ImageNet classification benchmark, limiting their applicability in performance-critical settings. Building on prior theoretical insights from Mitrovic et al., 2021, we propose ReLICv2 which combines an explicit invariance loss with a contrastive objective over a varied set of appropriately constructed data views. ReLICv2 achieves 77.1% top-1 classification accuracy on ImageNet using linear evaluation with a ResNet50 architecture and 80.6% with larger ResNet models, outperforming previous state-of-the-art self-supervised approaches by a wide margin. Most notably, ReLICv2 is the first representation learning method to consistently outperform the supervised baseline in a like-for-like comparison using a range of standard ResNet architectures. Finally we show that despite using ResNet encoders, ReLICv2 is comparable to state-of-the-art self-supervised vision transformers.
CoBERL: Contrastive BERT for Reinforcement Learning
Jul 12, 2021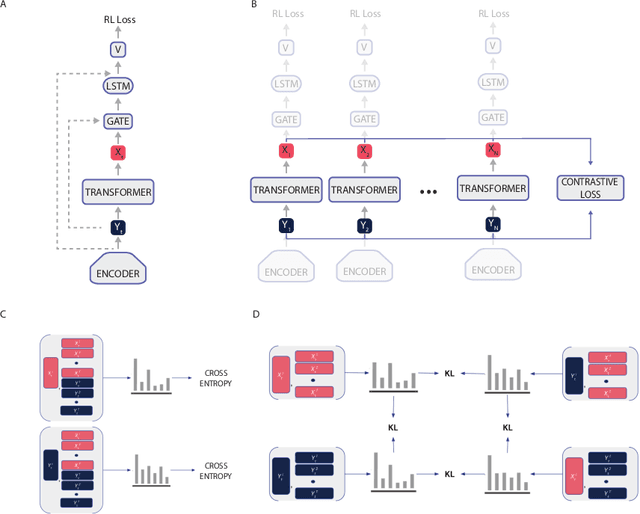

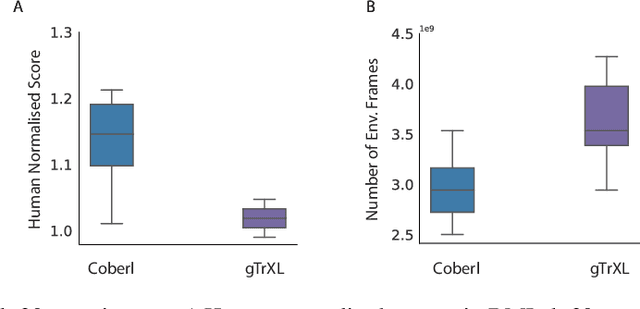

Many reinforcement learning (RL) agents require a large amount of experience to solve tasks. We propose Contrastive BERT for RL (CoBERL), an agent that combines a new contrastive loss and a hybrid LSTM-transformer architecture to tackle the challenge of improving data efficiency. CoBERL enables efficient, robust learning from pixels across a wide range of domains. We use bidirectional masked prediction in combination with a generalization of recent contrastive methods to learn better representations for transformers in RL, without the need of hand engineered data augmentations. We find that CoBERL consistently improves performance across the full Atari suite, a set of control tasks and a challenging 3D environment.
Representation Learning via Invariant Causal Mechanisms
Oct 15, 2020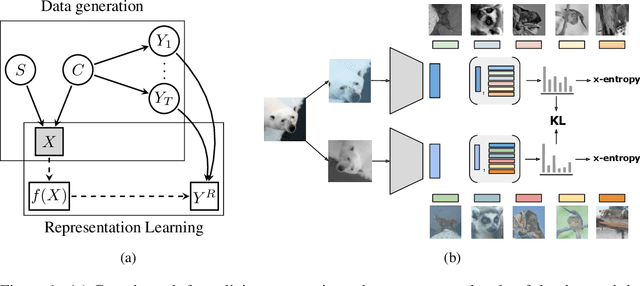
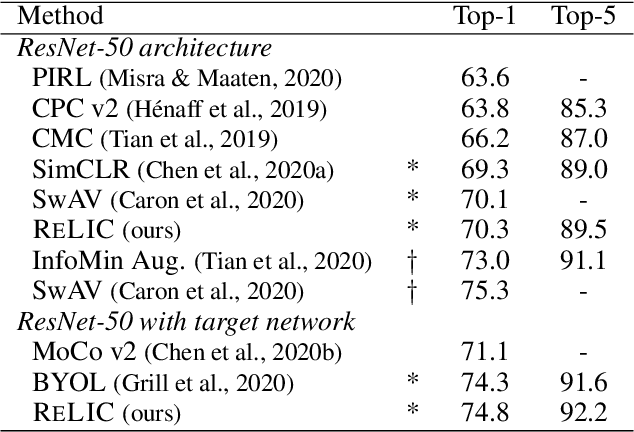
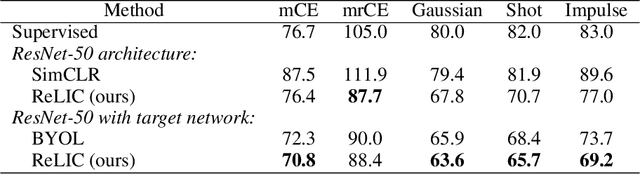
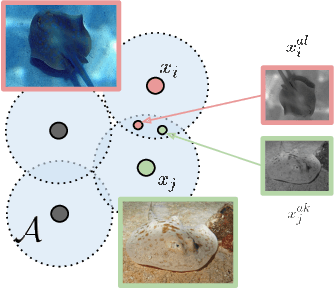
Self-supervised learning has emerged as a strategy to reduce the reliance on costly supervised signal by pretraining representations only using unlabeled data. These methods combine heuristic proxy classification tasks with data augmentations and have achieved significant success, but our theoretical understanding of this success remains limited. In this paper we analyze self-supervised representation learning using a causal framework. We show how data augmentations can be more effectively utilized through explicit invariance constraints on the proxy classifiers employed during pretraining. Based on this, we propose a novel self-supervised objective, Representation Learning via Invariant Causal Mechanisms (ReLIC), that enforces invariant prediction of proxy targets across augmentations through an invariance regularizer which yields improved generalization guarantees. Further, using causality we generalize contrastive learning, a particular kind of self-supervised method, and provide an alternative theoretical explanation for the success of these methods. Empirically, ReLIC significantly outperforms competing methods in terms of robustness and out-of-distribution generalization on ImageNet, while also significantly outperforming these methods on Atari achieving above human-level performance on $51$ out of $57$ games.
Amortized learning of neural causal representations
Aug 21, 2020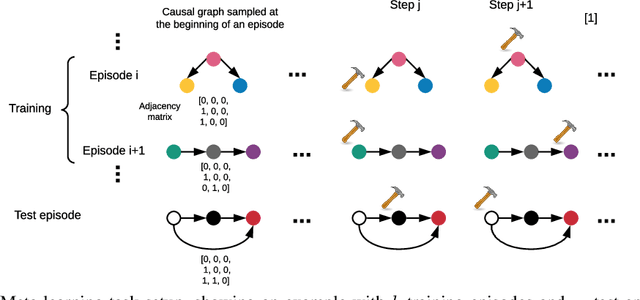
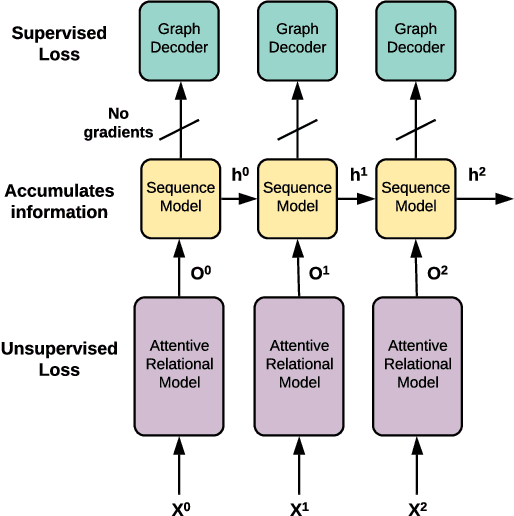
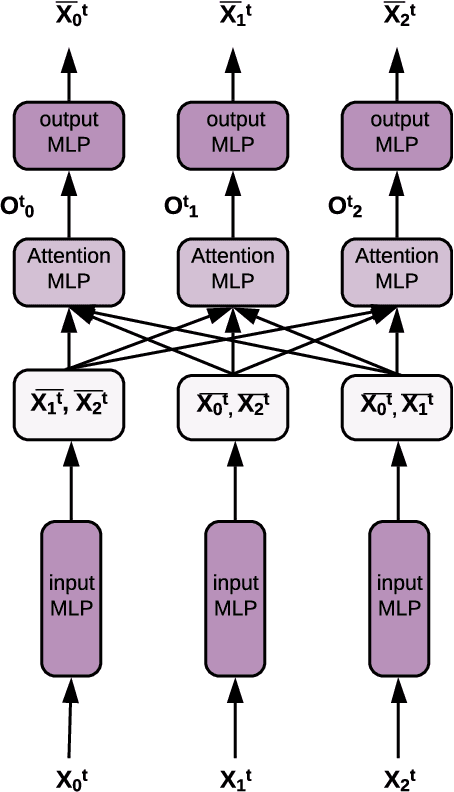

Causal models can compactly and efficiently encode the data-generating process under all interventions and hence may generalize better under changes in distribution. These models are often represented as Bayesian networks and learning them scales poorly with the number of variables. Moreover, these approaches cannot leverage previously learned knowledge to help with learning new causal models. In order to tackle these challenges, we represent a novel algorithm called \textit{causal relational networks} (CRN) for learning causal models using neural networks. The CRN represent causal models using continuous representations and hence could scale much better with the number of variables. These models also take in previously learned information to facilitate learning of new causal models. Finally, we propose a decoding-based metric to evaluate causal models with continuous representations. We test our method on synthetic data achieving high accuracy and quick adaptation to previously unseen causal models.
Causally Correct Partial Models for Reinforcement Learning
Feb 07, 2020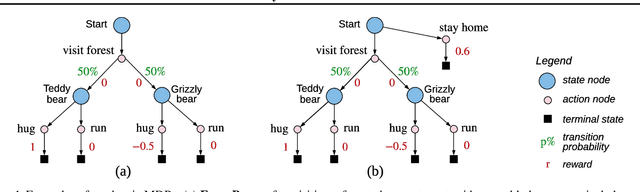


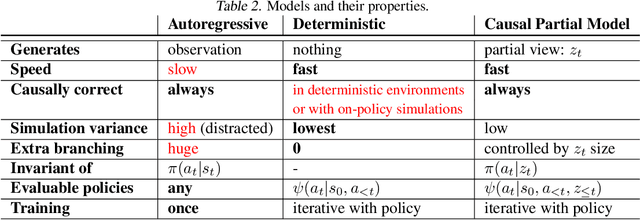
In reinforcement learning, we can learn a model of future observations and rewards, and use it to plan the agent's next actions. However, jointly modeling future observations can be computationally expensive or even intractable if the observations are high-dimensional (e.g. images). For this reason, previous works have considered partial models, which model only part of the observation. In this paper, we show that partial models can be causally incorrect: they are confounded by the observations they don't model, and can therefore lead to incorrect planning. To address this, we introduce a general family of partial models that are provably causally correct, yet remain fast because they do not need to fully model future observations.
Causal Reasoning from Meta-reinforcement Learning
Jan 23, 2019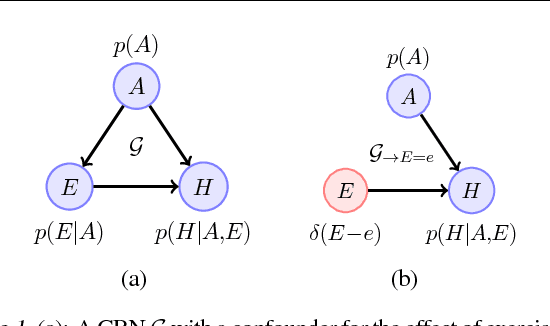


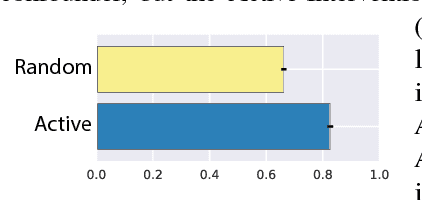
Discovering and exploiting the causal structure in the environment is a crucial challenge for intelligent agents. Here we explore whether causal reasoning can emerge via meta-reinforcement learning. We train a recurrent network with model-free reinforcement learning to solve a range of problems that each contain causal structure. We find that the trained agent can perform causal reasoning in novel situations in order to obtain rewards. The agent can select informative interventions, draw causal inferences from observational data, and make counterfactual predictions. Although established formal causal reasoning algorithms also exist, in this paper we show that such reasoning can arise from model-free reinforcement learning, and suggest that causal reasoning in complex settings may benefit from the more end-to-end learning-based approaches presented here. This work also offers new strategies for structured exploration in reinforcement learning, by providing agents with the ability to perform -- and interpret -- experiments.
Causal Inference via Kernel Deviance Measures
Apr 12, 2018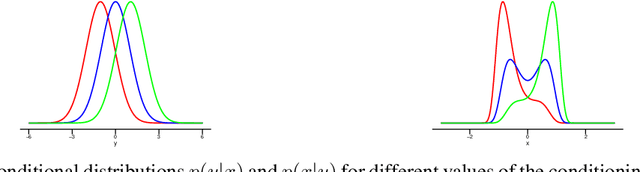


Discovering the causal structure among a set of variables is a fundamental problem in many areas of science. In this paper, we propose Kernel Conditional Deviance for Causal Inference (KCDC) a fully nonparametric causal discovery method based on purely observational data. From a novel interpretation of the notion of asymmetry between cause and effect, we derive a corresponding asymmetry measure using the framework of reproducing kernel Hilbert spaces. Based on this, we propose three decision rules for causal discovery. We demonstrate the wide applicability of our method across a range of diverse synthetic datasets. Furthermore, we test our method on real-world time series data and the real-world benchmark dataset Tubingen Cause-Effect Pairs where we outperform existing state-of-the-art methods.