 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the limits of self-supervised ResNets: Can we outperform supervised learning without labels on ImageNet?
Paper and Code
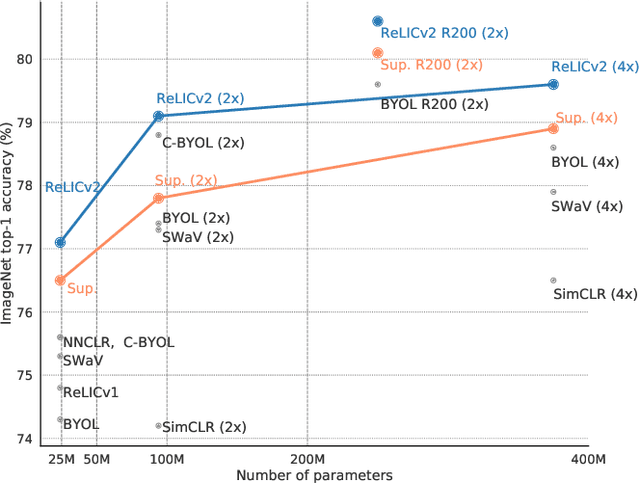
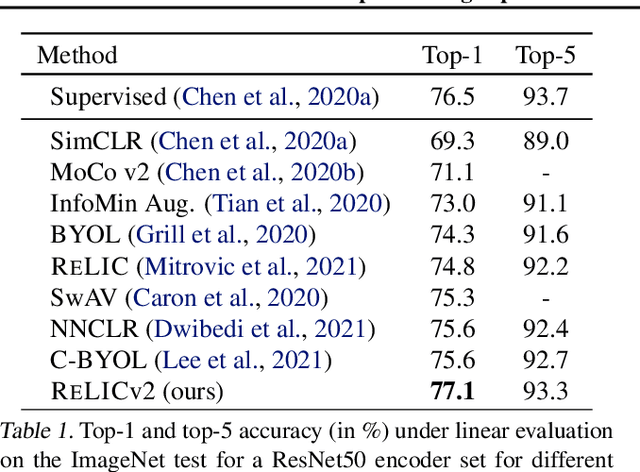
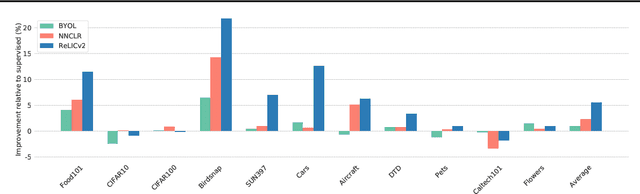
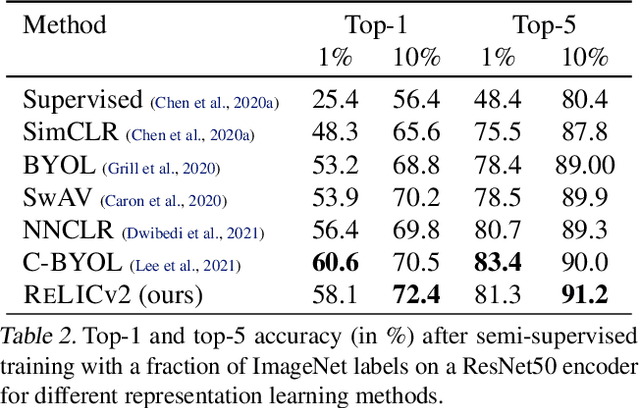
Despite recent progress made by self-supervised methods in representation learning with residual networks, they still underperform supervised learning on the ImageNet classification benchmark, limiting their applicability in performance-critical settings. Building on prior theoretical insights from Mitrovic et al., 2021, we propose ReLICv2 which combines an explicit invariance loss with a contrastive objective over a varied set of appropriately constructed data views. ReLICv2 achieves 77.1% top-1 classification accuracy on ImageNet using linear evaluation with a ResNet50 architecture and 80.6% with larger ResNet models, outperforming previous state-of-the-art self-supervised approaches by a wide margin. Most notably, ReLICv2 is the first representation learning method to consistently outperform the supervised baseline in a like-for-like comparison using a range of standard ResNet architectures. Finally we show that despite using ResNet encoders, ReLICv2 is comparable to state-of-the-art self-supervised vision transformers.