 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncreasing happiness through conversations with artificial intelligence
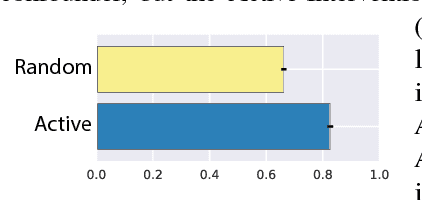
Apr 02, 2025Chatbots powered by artificial intelligence (AI) have rapidly become a significant part of everyday life, with over a quarter of American adults using them multiple times per week. While these tools offer potential benefits and risks, a fundamental question remains largely unexplored: How do conversations with AI influence subjective well-being? To investigate this, we conducted a study where participants either engaged in conversations with an AI chatbot (N = 334) or wrote journal entires (N = 193) on the same randomly assigned topics and reported their momentary happiness afterward. We found that happiness after AI chatbot conversations was higher than after journaling, particularly when discussing negative topics such as depression or guilt. Leveraging large language models for sentiment analysis, we found that the AI chatbot mirrored participants' sentiment while maintaining a consistent positivity bias. When discussing negative topics, participants gradually aligned their sentiment with the AI's positivity, leading to an overall increase in happiness. We hypothesized that the history of participants' sentiment prediction errors, the difference between expected and actual emotional tone when responding to the AI chatbot, might explain this happiness effect. Using computational modeling, we find the history of these sentiment prediction errors over the course of a conversation predicts greater post-conversation happiness, demonstrating a central role of emotional expectations during dialogue. Our findings underscore the effect that AI interactions can have on human well-being.
Alchemy: A structured task distribution for meta-reinforcement learning
Feb 04, 2021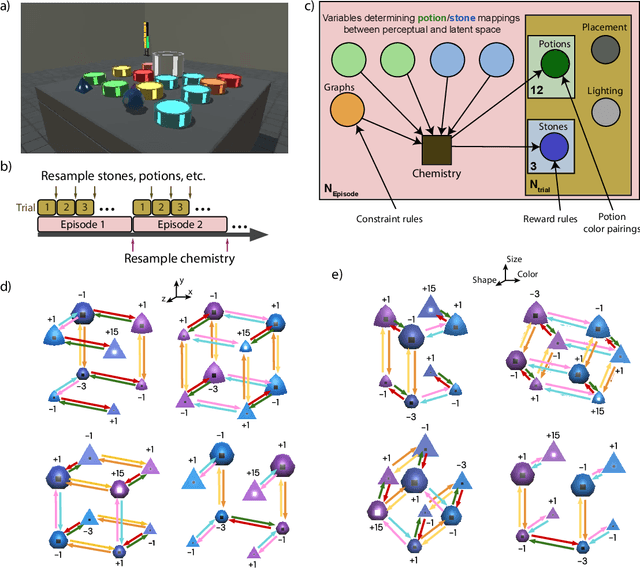

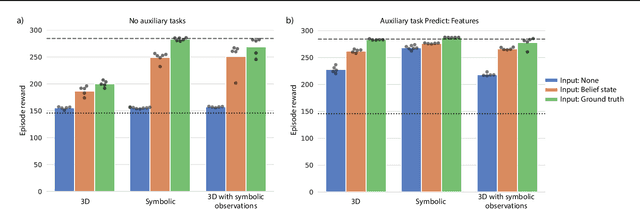

There has been rapidly growing interest in meta-learning as a method for increasing the flexibility and sample efficiency of reinforcement learning. One problem in this area of research, however, has been a scarcity of adequate benchmark tasks. In general, the structure underlying past benchmarks has either been too simple to be inherently interesting, or too ill-defined to support principled analysis. In the present work, we introduce a new benchmark for meta-RL research, which combines structural richness with structural transparency. Alchemy is a 3D video game, implemented in Unity, which involves a latent causal structure that is resampled procedurally from episode to episode, affording structure learning, online inference, hypothesis testing and action sequencing based on abstract domain knowledge. We evaluate a pair of powerful RL agents on Alchemy and present an in-depth analysis of one of these agents. Results clearly indicate a frank and specific failure of meta-learning, providing validation for Alchemy as a challenging benchmark for meta-RL. Concurrent with this report, we are releasing Alchemy as public resource, together with a suite of analysis tools and sample agent trajectories.
Deep Reinforcement Learning and its Neuroscientific Implications
Jul 07, 2020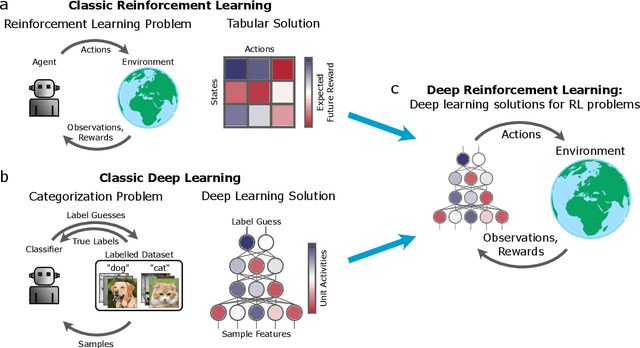
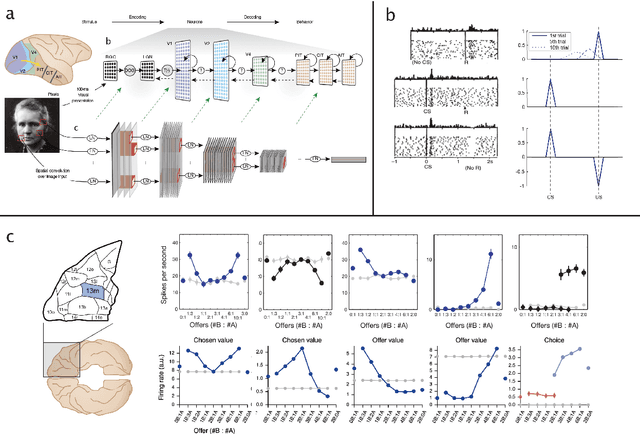
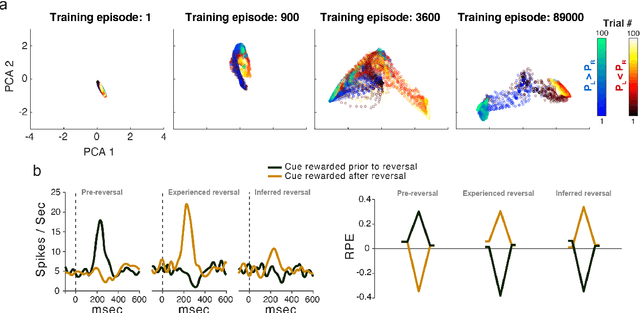
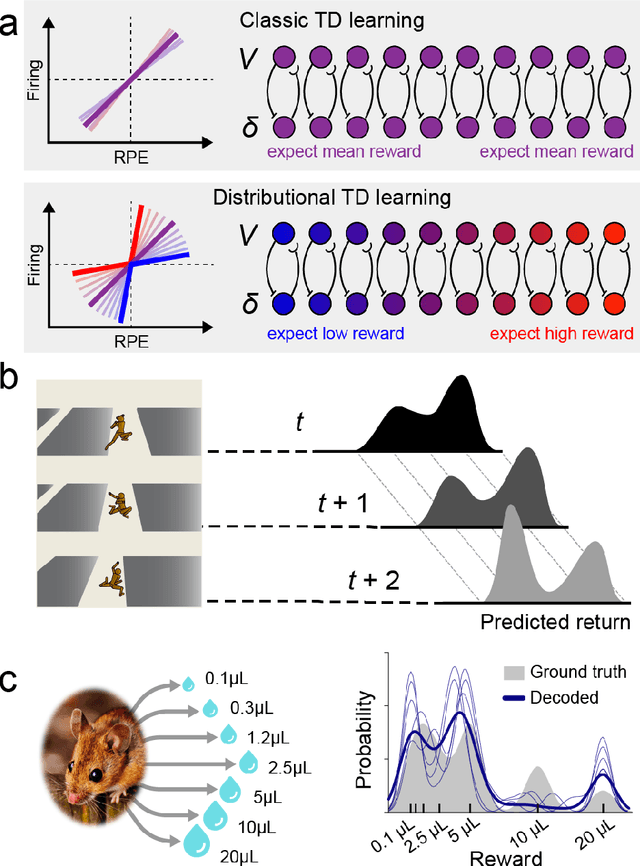
The emergence of powerful artificial intelligence is defining new research directions in neuroscience. To date, this research has focused largely on deep neural networks trained using supervised learning, in tasks such as image classification. However, there is another area of recent AI work which has so far received less attention from neuroscientists, but which may have profound neuroscientific implications: deep reinforcement learning. Deep RL offers a comprehensive framework for studying the interplay among learning, representation and decision-making, offering to the brain sciences a new set of research tools and a wide range of novel hypotheses. In the present review, we provide a high-level introduction to deep RL, discuss some of its initial applications to neuroscience, and survey its wider implications for research on brain and behavior, concluding with a list of opportunities for next-stage research.
Meta-learning of Sequential Strategies
May 08, 2019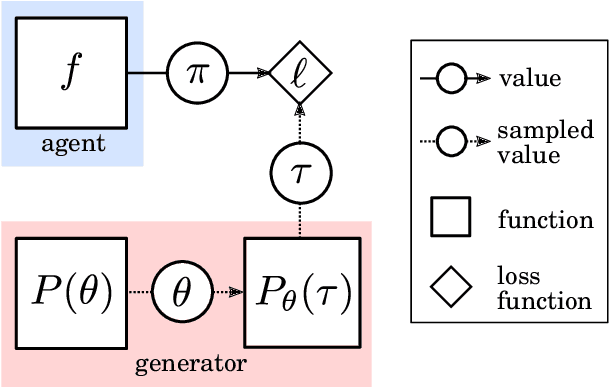
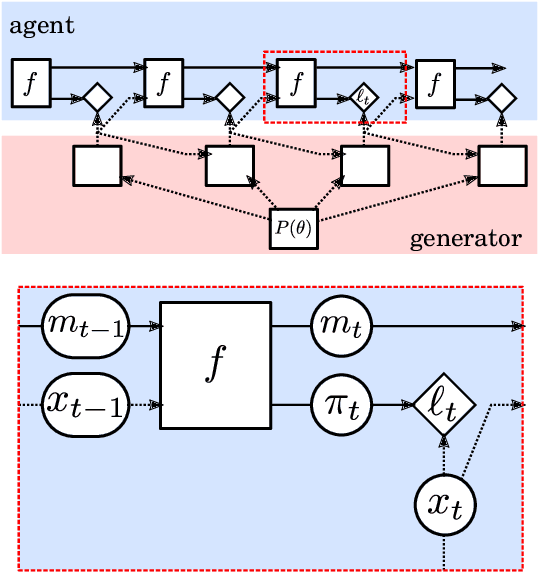
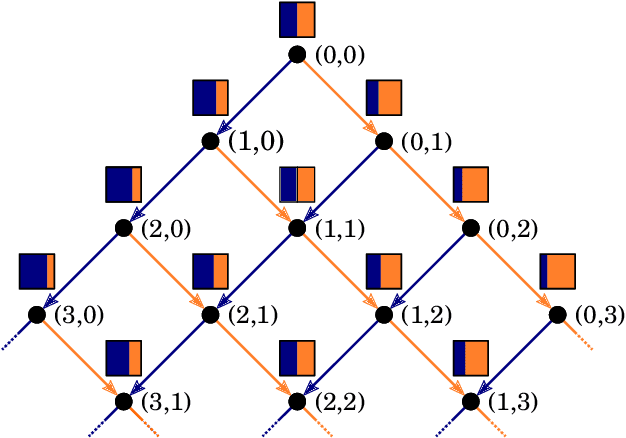
In this report we review memory-based meta-learning as a tool for building sample-efficient strategies that learn from past experience to adapt to any task within a target class. Our goal is to equip the reader with the conceptual foundations of this tool for building new, scalable agents that operate on broad domains. To do so, we present basic algorithmic templates for building near-optimal predictors and reinforcement learners which behave as if they had a probabilistic model that allowed them to efficiently exploit task structure. Furthermore, we recast memory-based meta-learning within a Bayesian framework, showing that the meta-learned strategies are near-optimal because they amortize Bayes-filtered data, where the adaptation is implemented in the memory dynamics as a state-machine of sufficient statistics. Essentially, memory-based meta-learning translates the hard problem of probabilistic sequential inference into a regression problem.
Causal Reasoning from Meta-reinforcement Learning
Jan 23, 2019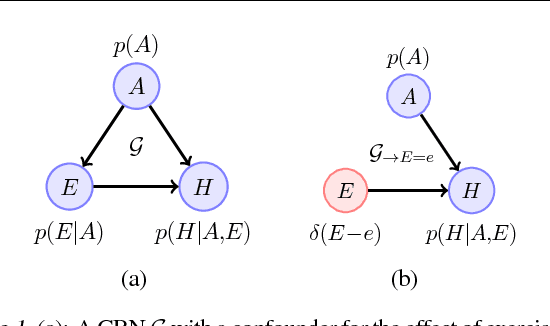


Discovering and exploiting the causal structure in the environment is a crucial challenge for intelligent agents. Here we explore whether causal reasoning can emerge via meta-reinforcement learning. We train a recurrent network with model-free reinforcement learning to solve a range of problems that each contain causal structure. We find that the trained agent can perform causal reasoning in novel situations in order to obtain rewards. The agent can select informative interventions, draw causal inferences from observational data, and make counterfactual predictions. Although established formal causal reasoning algorithms also exist, in this paper we show that such reasoning can arise from model-free reinforcement learning, and suggest that causal reasoning in complex settings may benefit from the more end-to-end learning-based approaches presented here. This work also offers new strategies for structured exploration in reinforcement learning, by providing agents with the ability to perform -- and interpret -- experiments.
Been There, Done That: Meta-Learning with Episodic Recall
Jul 06, 2018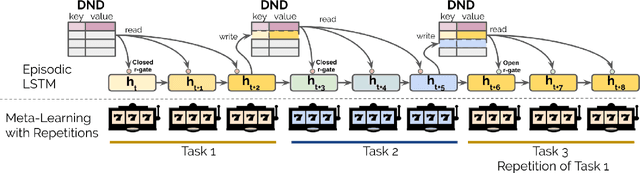
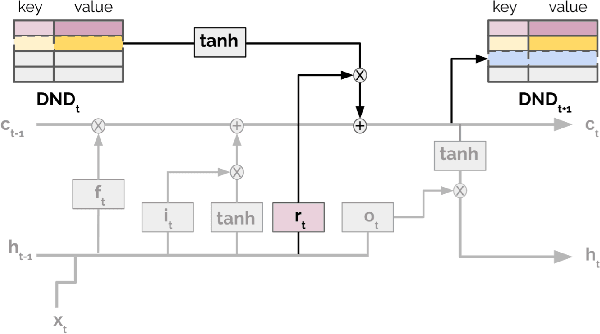
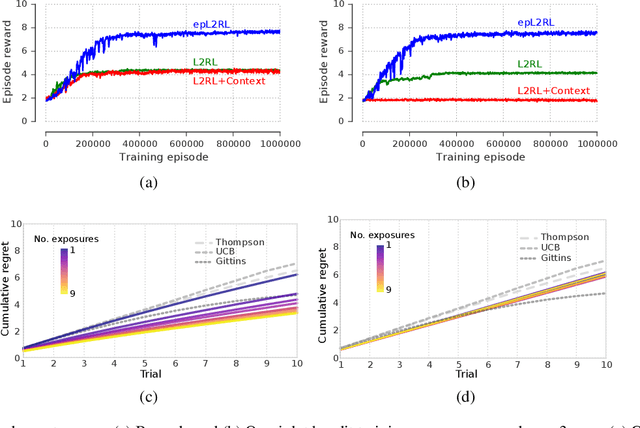
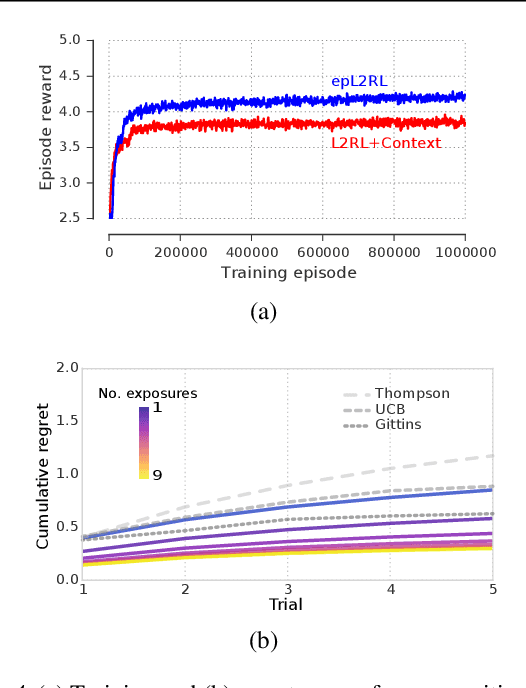
Meta-learning agents excel at rapidly learning new tasks from open-ended task distributions; yet, they forget what they learn about each task as soon as the next begins. When tasks reoccur - as they do in natural environments - metalearning agents must explore again instead of immediately exploiting previously discovered solutions. We propose a formalism for generating open-ended yet repetitious environments, then develop a meta-learning architecture for solving these environments. This architecture melds the standard LSTM working memory with a differentiable neural episodic memory. We explore the capabilities of agents with this episodic LSTM in five meta-learning environments with reoccurring tasks, ranging from bandits to navigation and stochastic sequential decision problems.
Learning to reinforcement learn
Jan 23, 2017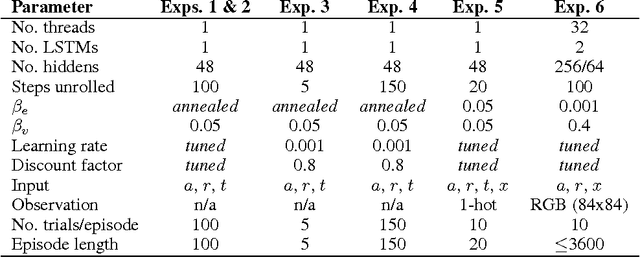
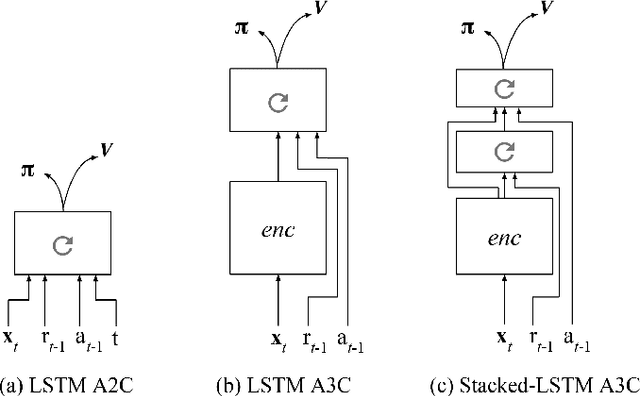
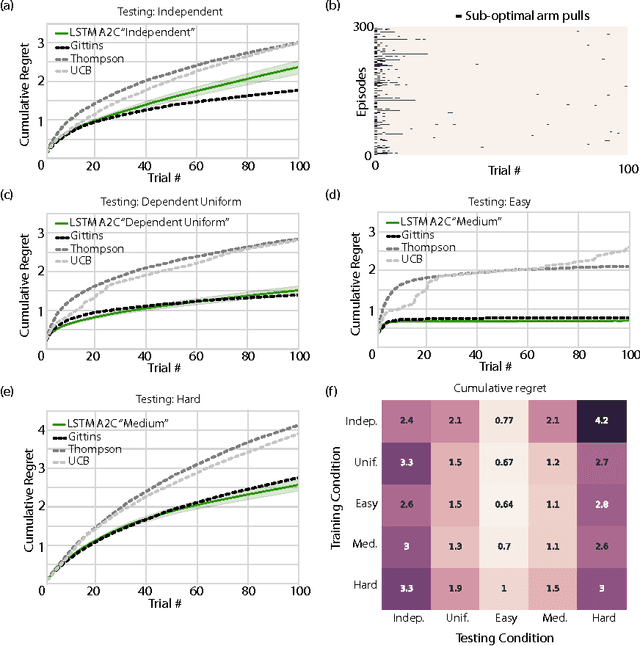
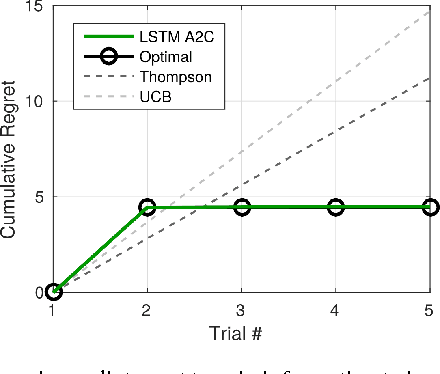
In recent years deep reinforcement learning (RL) systems have attained superhuman performance in a number of challenging task domains. However, a major limitation of such applications is their demand for massive amounts of training data. A critical present objective is thus to develop deep RL methods that can adapt rapidly to new tasks. In the present work we introduce a novel approach to this challenge, which we refer to as deep meta-reinforcement learning. Previous work has shown that recurrent networks can support meta-learning in a fully supervised context. We extend this approach to the RL setting. What emerges is a system that is trained using one RL algorithm, but whose recurrent dynamics implement a second, quite separate RL procedure. This second, learned RL algorithm can differ from the original one in arbitrary ways. Importantly, because it is learned, it is configured to exploit structure in the training domain. We unpack these points in a series of seven proof-of-concept experiments, each of which examines a key aspect of deep meta-RL. We consider prospects for extending and scaling up the approach, and also point out some potentially important implications for neuroscience.