 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA social path to human-like artificial intelligence
May 22, 2024Traditionally, cognitive and computer scientists have viewed intelligence solipsistically, as a property of unitary agents devoid of social context. Given the success of contemporary learning algorithms, we argue that the bottleneck in artificial intelligence (AI) progress is shifting from data assimilation to novel data generation. We bring together evidence showing that natural intelligence emerges at multiple scales in networks of interacting agents via collective living, social relationships and major evolutionary transitions, which contribute to novel data generation through mechanisms such as population pressures, arms races, Machiavellian selection, social learning and cumulative culture. Many breakthroughs in AI exploit some of these processes, from multi-agent structures enabling algorithms to master complex games like Capture-The-Flag and StarCraft II, to strategic communication in Diplomacy and the shaping of AI data streams by other AIs. Moving beyond a solipsistic view of agency to integrate these mechanisms suggests a path to human-like compounding innovation through ongoing novel data generation.
CogBench: a large language model walks into a psychology lab
Feb 28, 2024
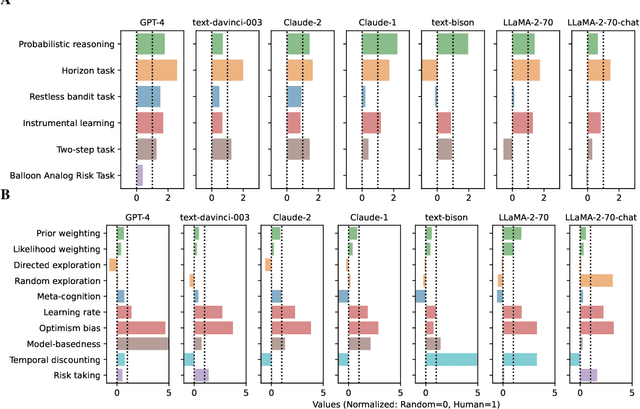
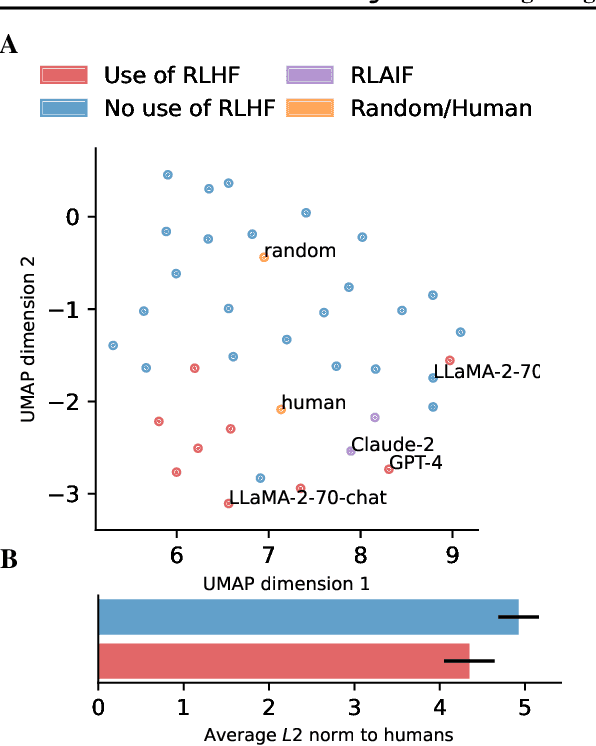
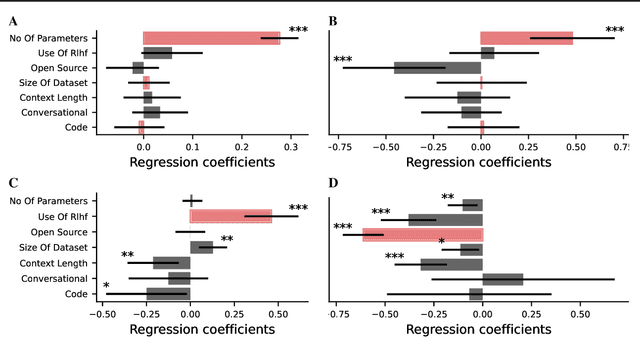
Large language models (LLMs) have significantly advanced the field of artificial intelligence. Yet, evaluating them comprehensively remains challenging. We argue that this is partly due to the predominant focus on performance metrics in most benchmarks. This paper introduces CogBench, a benchmark that includes ten behavioral metrics derived from seven cognitive psychology experiments. This novel approach offers a toolkit for phenotyping LLMs' behavior. We apply CogBench to 35 LLMs, yielding a rich and diverse dataset. We analyze this data using statistical multilevel modeling techniques, accounting for the nested dependencies among fine-tuned versions of specific LLMs. Our study highlights the crucial role of model size and reinforcement learning from human feedback (RLHF) in improving performance and aligning with human behavior. Interestingly, we find that open-source models are less risk-prone than proprietary models and that fine-tuning on code does not necessarily enhance LLMs' behavior. Finally, we explore the effects of prompt-engineering techniques. We discover that chain-of-thought prompting improves probabilistic reasoning, while take-a-step-back prompting fosters model-based behaviors.
Meta-in-context learning in large language models
May 22, 2023Large language models have shown tremendous performance in a variety of tasks. In-context learning -- the ability to improve at a task after being provided with a number of demonstrations -- is seen as one of the main contributors to their success. In the present paper, we demonstrate that the in-context learning abilities of large language models can be recursively improved via in-context learning itself. We coin this phenomenon meta-in-context learning. Looking at two idealized domains, a one-dimensional regression task and a two-armed bandit task, we show that meta-in-context learning adaptively reshapes a large language model's priors over expected tasks. Furthermore, we find that meta-in-context learning modifies the in-context learning strategies of such models. Finally, we extend our approach to a benchmark of real-world regression problems where we observe competitive performance to traditional learning algorithms. Taken together, our work improves our understanding of in-context learning and paves the way toward adapting large language models to the environment they are applied purely through meta-in-context learning rather than traditional finetuning.
Meta-Learned Models of Cognition
Apr 12, 2023Meta-learning is a framework for learning learning algorithms through repeated interactions with an environment as opposed to designing them by hand. In recent years, this framework has established itself as a promising tool for building models of human cognition. Yet, a coherent research program around meta-learned models of cognition is still missing. The purpose of this article is to synthesize previous work in this field and establish such a research program. We rely on three key pillars to accomplish this goal. We first point out that meta-learning can be used to construct Bayes-optimal learning algorithms. This result not only implies that any behavioral phenomenon that can be explained by a Bayesian model can also be explained by a meta-learned model but also allows us to draw strong connections to the rational analysis of cognition. We then discuss several advantages of the meta-learning framework over traditional Bayesian methods. In particular, we argue that meta-learning can be applied to situations where Bayesian inference is impossible and that it enables us to make rational models of cognition more realistic, either by incorporating limited computational resources or neuroscientific knowledge. Finally, we reexamine prior studies from psychology and neuroscience that have applied meta-learning and put them into the context of these new insights. In summary, our work highlights that meta-learning considerably extends the scope of rational analysis and thereby of cognitive theories more generally.
Semantic Exploration from Language Abstractions and Pretrained Representations
Apr 08, 2022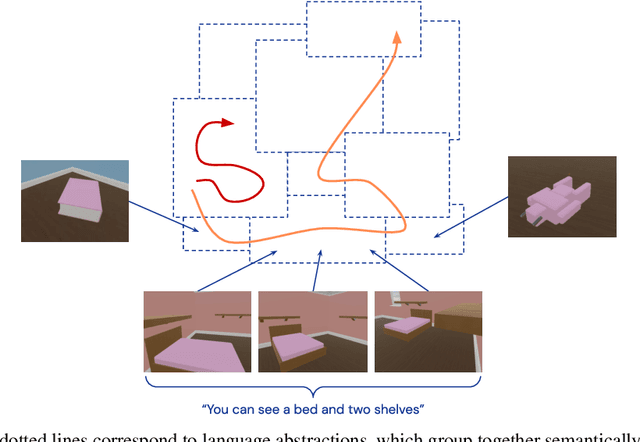


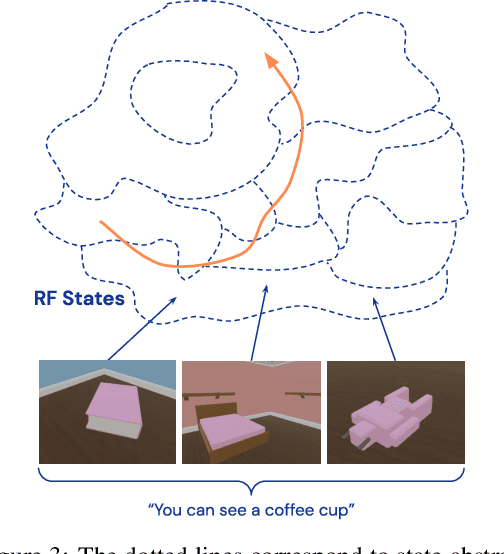
Continuous first-person 3D environments pose unique exploration challenges to reinforcement learning (RL) agents because of their high-dimensional state and action spaces. These challenges can be ameliorated by using semantically meaningful state abstractions to define novelty for exploration. We propose that learned representations shaped by natural language provide exactly this form of abstraction. In particular, we show that vision-language representations, when pretrained on image captioning datasets sampled from the internet, can drive meaningful, task-relevant exploration and improve performance on 3D simulated environments. We also characterize why and how language provides useful abstractions for exploration by comparing the impacts of using representations from a pretrained model, a language oracle, and several ablations. We demonstrate the benefits of our approach in two very different task domains -- one that stresses the identification and manipulation of everyday objects, and one that requires navigational exploration in an expansive world -- as well as two popular deep RL algorithms: Impala and R2D2. Our results suggest that using language-shaped representations could improve exploration for various algorithms and agents in challenging environments.
Can language models learn from explanations in context?
Apr 05, 2022
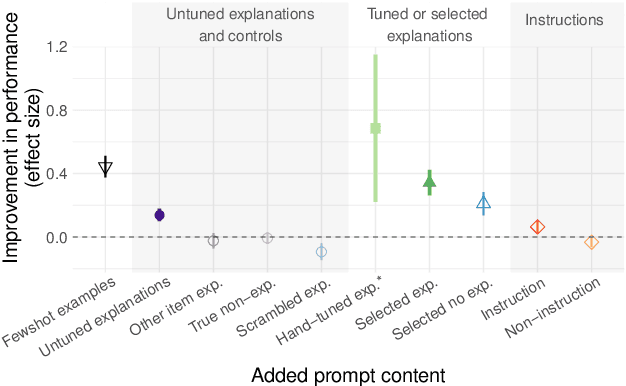
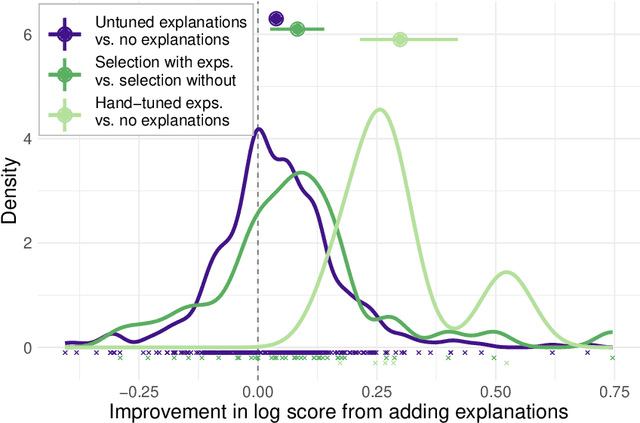
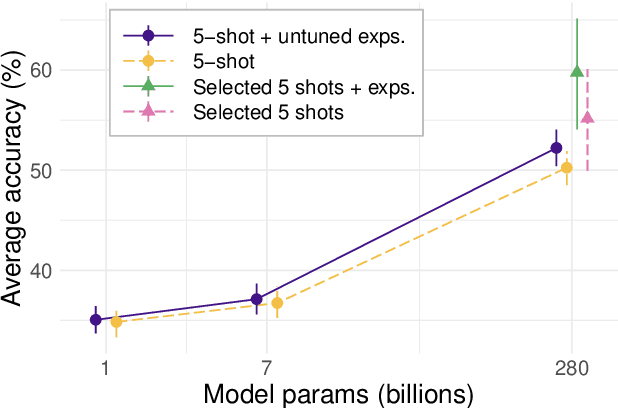
Large language models can perform new tasks by adapting to a few in-context examples. For humans, rapid learning from examples can benefit from explanations that connect examples to task principles. We therefore investigate whether explanations of few-shot examples can allow language models to adapt more effectively. We annotate a set of 40 challenging tasks from BIG-Bench with explanations of answers to a small subset of questions, as well as a variety of matched control explanations. We evaluate the effects of various zero-shot and few-shot prompts that include different types of explanations, instructions, and controls on the performance of a range of large language models. We analyze these results using statistical multilevel modeling techniques that account for the nested dependencies among conditions, tasks, prompts, and models. We find that explanations of examples can improve performance. Adding untuned explanations to a few-shot prompt offers a modest improvement in performance; about 1/3 the effect size of adding few-shot examples, but twice the effect size of task instructions. We then show that explanations tuned for performance on a small validation set offer substantially larger benefits; building a prompt by selecting examples and explanations together substantially improves performance over selecting examples alone. Hand-tuning explanations can substantially improve performance on challenging tasks. Furthermore, even untuned explanations outperform carefully matched controls, suggesting that the benefits are due to the link between an example and its explanation, rather than lower-level features of the language used. However, only large models can benefit from explanations. In summary, explanations can support the in-context learning abilities of large language models on
Tell me why! -- Explanations support learning of relational and causal structure
Dec 08, 2021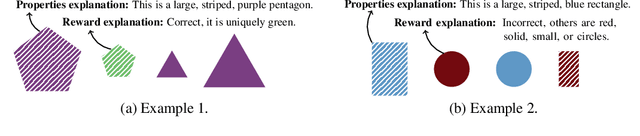
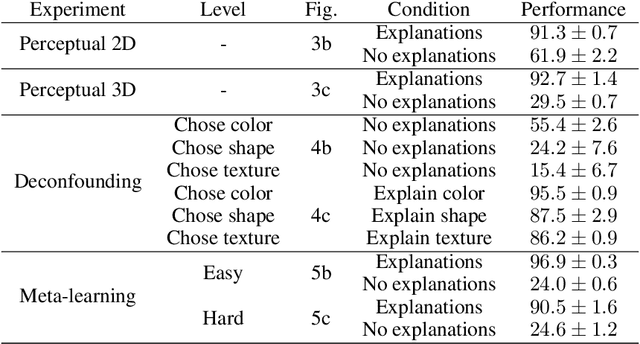
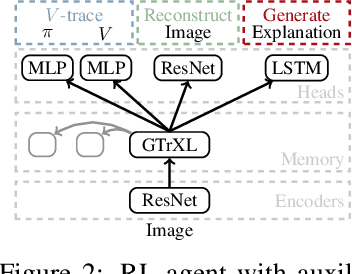
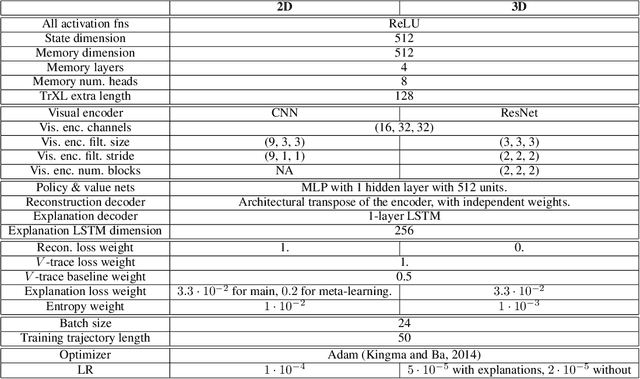
Explanations play a considerable role in human learning, especially in areas that remain major challenges for AI -- forming abstractions, and learning about the relational and causal structure of the world. Here, we explore whether reinforcement learning agents might likewise benefit from explanations. We outline a family of relational tasks that involve selecting an object that is the odd one out in a set (i.e., unique along one of many possible feature dimensions). Odd-one-out tasks require agents to reason over multi-dimensional relationships among a set of objects. We show that agents do not learn these tasks well from reward alone, but achieve >90% performance when they are also trained to generate language explaining object properties or why a choice is correct or incorrect. In further experiments, we show how predicting explanations enables agents to generalize appropriately from ambiguous, causally-confounded training, and even to meta-learn to perform experimental interventions to identify causal structure. We show that explanations help overcome the tendency of agents to fixate on simple features, and explore which aspects of explanations make them most beneficial. Our results suggest that learning from explanations is a powerful principle that could offer a promising path towards training more robust and general machine learning systems.
Alchemy: A structured task distribution for meta-reinforcement learning
Feb 04, 2021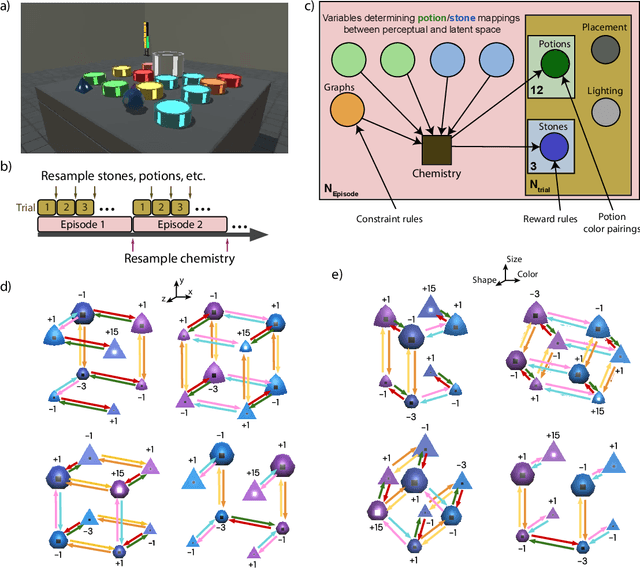

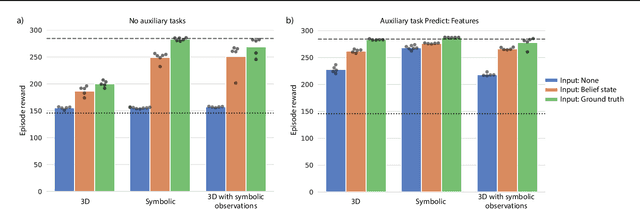

There has been rapidly growing interest in meta-learning as a method for increasing the flexibility and sample efficiency of reinforcement learning. One problem in this area of research, however, has been a scarcity of adequate benchmark tasks. In general, the structure underlying past benchmarks has either been too simple to be inherently interesting, or too ill-defined to support principled analysis. In the present work, we introduce a new benchmark for meta-RL research, which combines structural richness with structural transparency. Alchemy is a 3D video game, implemented in Unity, which involves a latent causal structure that is resampled procedurally from episode to episode, affording structure learning, online inference, hypothesis testing and action sequencing based on abstract domain knowledge. We evaluate a pair of powerful RL agents on Alchemy and present an in-depth analysis of one of these agents. Results clearly indicate a frank and specific failure of meta-learning, providing validation for Alchemy as a challenging benchmark for meta-RL. Concurrent with this report, we are releasing Alchemy as public resource, together with a suite of analysis tools and sample agent trajectories.
Meta-learning in natural and artificial intelligence
Nov 26, 2020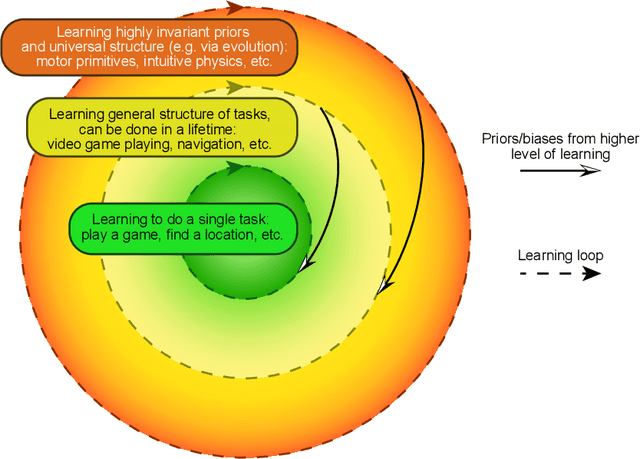
Meta-learning, or learning to learn, has gained renewed interest in recent years within the artificial intelligence community. However, meta-learning is incredibly prevalent within nature, has deep roots in cognitive science and psychology, and is currently studied in various forms within neuroscience. The aim of this review is to recast previous lines of research in the study of biological intelligence within the lens of meta-learning, placing these works into a common framework. More recent points of interaction between AI and neuroscience will be discussed, as well as interesting new directions that arise under this perspective.
Temporal Difference Uncertainties as a Signal for Exploration
Oct 05, 2020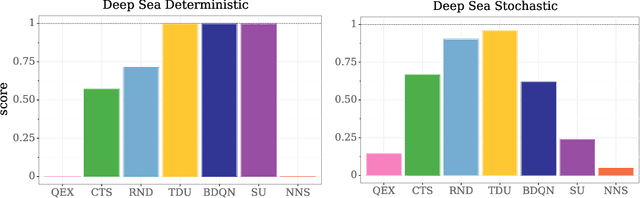
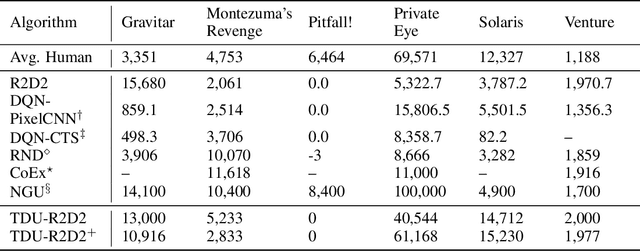
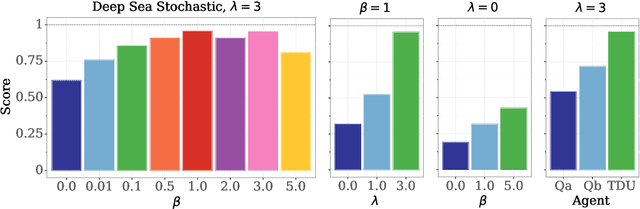

An effective approach to exploration in reinforcement learning is to rely on an agent's uncertainty over the optimal policy, which can yield near-optimal exploration strategies in tabular settings. However, in non-tabular settings that involve function approximators, obtaining accurate uncertainty estimates is almost as challenging a problem. In this paper, we highlight that value estimates are easily biased and temporally inconsistent. In light of this, we propose a novel method for estimating uncertainty over the value function that relies on inducing a distribution over temporal difference errors. This exploration signal controls for state-action transitions so as to isolate uncertainty in value that is due to uncertainty over the agent's parameters. Because our measure of uncertainty conditions on state-action transitions, we cannot act on this measure directly. Instead, we incorporate it as an intrinsic reward and treat exploration as a separate learning problem, induced by the agent's temporal difference uncertainties. We introduce a distinct exploration policy that learns to collect data with high estimated uncertainty, which gives rise to a curriculum that smoothly changes throughout learning and vanishes in the limit of perfect value estimates. We evaluate our method on hard exploration tasks, including Deep Sea and Atari 2600 environments and find that our proposed form of exploration facilitates both diverse and deep exploration.