 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation biases: will we achieve complete understanding by analyzing representations?
Jul 29, 2025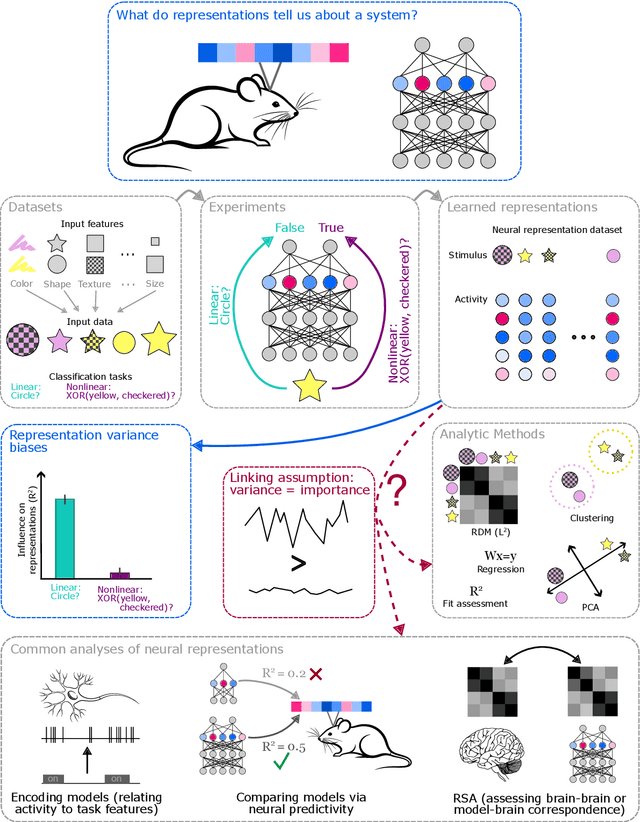
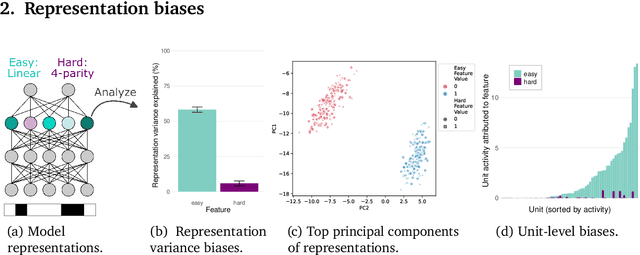
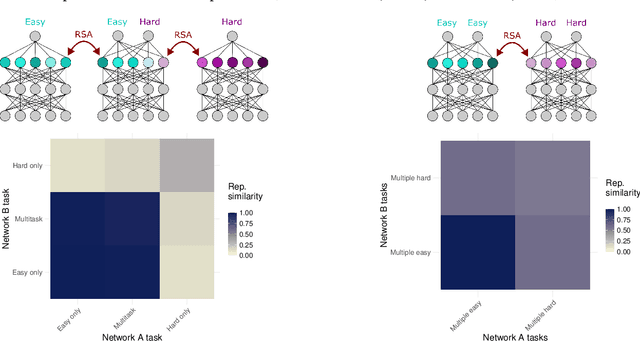
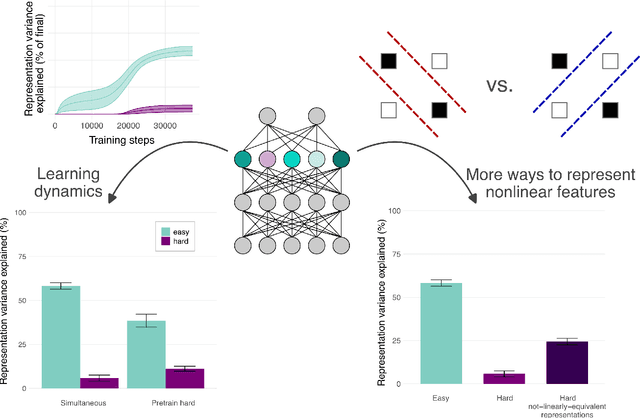
A common approach in neuroscience is to study neural representations as a means to understand a system -- increasingly, by relating the neural representations to the internal representations learned by computational models. However, a recent work in machine learning (Lampinen, 2024) shows that learned feature representations may be biased to over-represent certain features, and represent others more weakly and less-consistently. For example, simple (linear) features may be more strongly and more consistently represented than complex (highly nonlinear) features. These biases could pose challenges for achieving full understanding of a system through representational analysis. In this perspective, we illustrate these challenges -- showing how feature representation biases can lead to strongly biased inferences from common analyses like PCA, regression, and RSA. We also present homomorphic encryption as a simple case study of the potential for strong dissociation between patterns of representation and computation. We discuss the implications of these results for representational comparisons between systems, and for neuroscience more generally.
The emergence of sparse attention: impact of data distribution and benefits of repetition
May 23, 2025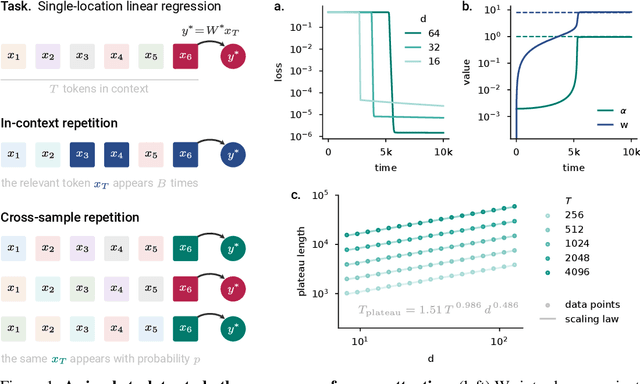
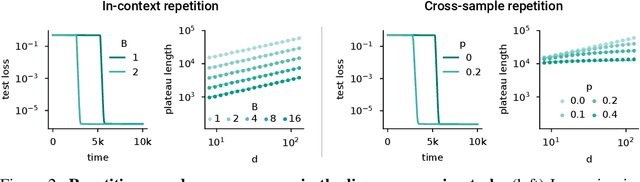
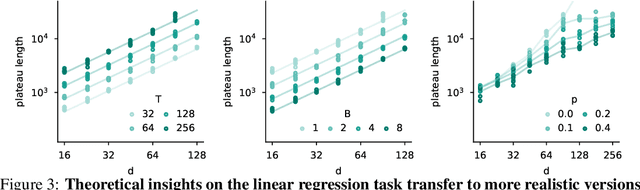
Emergence is a fascinating property of large language models and neural networks more broadly: as models scale and train for longer, they sometimes develop new abilities in sudden ways. Despite initial studies, we still lack a comprehensive understanding of how and when these abilities emerge. To address this gap, we study the emergence over training of sparse attention, a critical and frequently observed attention pattern in Transformers. By combining theoretical analysis of a toy model with empirical observations on small Transformers trained on a linear regression variant, we uncover the mechanics driving sparse attention emergence and reveal that emergence timing follows power laws based on task structure, architecture, and optimizer choice. We additionally find that repetition can greatly speed up emergence. Finally, we confirm these results on a well-studied in-context associative recall task. Our findings provide a simple, theoretically grounded framework for understanding how data distributions and model design influence the learning dynamics behind one form of emergence.
Predictability Shapes Adaptation: An Evolutionary Perspective on Modes of Learning in Transformers
May 14, 2025Transformer models learn in two distinct modes: in-weights learning (IWL), encoding knowledge into model weights, and in-context learning (ICL), adapting flexibly to context without weight modification. To better understand the interplay between these learning modes, we draw inspiration from evolutionary biology's analogous adaptive strategies: genetic encoding (akin to IWL, adapting over generations and fixed within an individual's lifetime) and phenotypic plasticity (akin to ICL, enabling flexible behavioral responses to environmental cues). In evolutionary biology, environmental predictability dictates the balance between these strategies: stability favors genetic encoding, while reliable predictive cues promote phenotypic plasticity. We experimentally operationalize these dimensions of predictability and systematically investigate their influence on the ICL/IWL balance in Transformers. Using regression and classification tasks, we show that high environmental stability decisively favors IWL, as predicted, with a sharp transition at maximal stability. Conversely, high cue reliability enhances ICL efficacy, particularly when stability is low. Furthermore, learning dynamics reveal task-contingent temporal evolution: while a canonical ICL-to-IWL shift occurs in some settings (e.g., classification with many classes), we demonstrate that scenarios with easier IWL (e.g., fewer classes) or slower ICL acquisition (e.g., regression) can exhibit an initial IWL phase later yielding to ICL dominance. These findings support a relative-cost hypothesis for explaining these learning mode transitions, establishing predictability as a critical factor governing adaptive strategies in Transformers, and offering novel insights for understanding ICL and guiding training methodologies.
On the generalization of language models from in-context learning and finetuning: a controlled study
May 01, 2025Large language models exhibit exciting capabilities, yet can show surprisingly narrow generalization from finetuning -- from failing to generalize to simple reversals of relations they are trained on, to missing logical deductions that can be made from trained information. These failures to generalize from fine-tuning can hinder practical application of these models. However, language models' in-context learning shows different inductive biases, and can generalize better in some of these cases. Here, we explore these differences in generalization between in-context- and fine-tuning-based learning. To do so, we constructed several novel datasets to evaluate and improve models' ability to generalize from finetuning data. The datasets are constructed to isolate the knowledge in the dataset from that in pretraining, to create clean tests of generalization. We expose pretrained large models to controlled subsets of the information in these datasets -- either in context, or through fine-tuning -- and evaluate their performance on test sets that require various types of generalization. We find overall that in data-matched settings, in-context learning can generalize more flexibly than fine-tuning (though we also find some qualifications of prior findings, such as cases when fine-tuning can generalize to reversals embedded in a larger structure of knowledge). We build on these findings to propose a method to enable improved generalization from fine-tuning: adding in-context inferences to finetuning data. We show that this method improves generalization across various splits of our datasets and other benchmarks. Our results have implications for understanding the inductive biases of different modes of learning in language models, and practically improving their performance.
Strategy Coopetition Explains the Emergence and Transience of In-Context Learning
Mar 07, 2025In-context learning (ICL) is a powerful ability that emerges in transformer models, enabling them to learn from context without weight updates. Recent work has established emergent ICL as a transient phenomenon that can sometimes disappear after long training times. In this work, we sought a mechanistic understanding of these transient dynamics. Firstly, we find that, after the disappearance of ICL, the asymptotic strategy is a remarkable hybrid between in-weights and in-context learning, which we term "context-constrained in-weights learning" (CIWL). CIWL is in competition with ICL, and eventually replaces it as the dominant strategy of the model (thus leading to ICL transience). However, we also find that the two competing strategies actually share sub-circuits, which gives rise to cooperative dynamics as well. For example, in our setup, ICL is unable to emerge quickly on its own, and can only be enabled through the simultaneous slow development of asymptotic CIWL. CIWL thus both cooperates and competes with ICL, a phenomenon we term "strategy coopetition." We propose a minimal mathematical model that reproduces these key dynamics and interactions. Informed by this model, we were able to identify a setup where ICL is truly emergent and persistent.
The broader spectrum of in-context learning
Dec 05, 2024

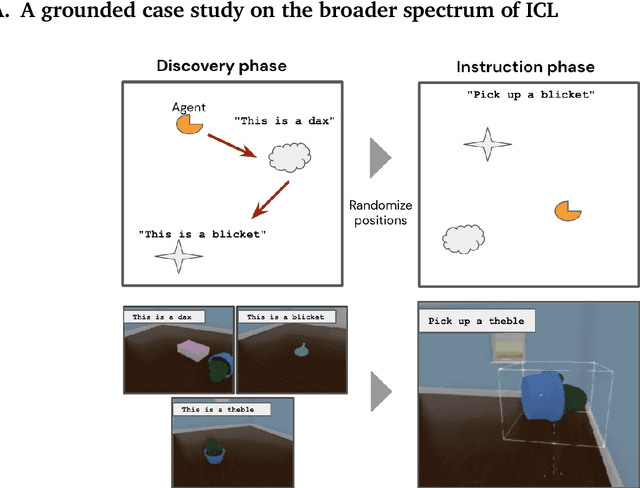
The ability of language models to learn a task from a few examples in context has generated substantial interest. Here, we provide a perspective that situates this type of supervised few-shot learning within a much broader spectrum of meta-learned in-context learning. Indeed, we suggest that any distribution of sequences in which context non-trivially decreases loss on subsequent predictions can be interpreted as eliciting a kind of in-context learning. We suggest that this perspective helps to unify the broad set of in-context abilities that language models exhibit $\unicode{x2014}$ such as adapting to tasks from instructions or role play, or extrapolating time series. This perspective also sheds light on potential roots of in-context learning in lower-level processing of linguistic dependencies (e.g. coreference or parallel structures). Finally, taking this perspective highlights the importance of generalization, which we suggest can be studied along several dimensions: not only the ability to learn something novel, but also flexibility in learning from different presentations, and in applying what is learned. We discuss broader connections to past literature in meta-learning and goal-conditioned agents, and other perspectives on learning and adaptation. We close by suggesting that research on in-context learning should consider this broader spectrum of in-context capabilities and types of generalization.
Learned feature representations are biased by complexity, learning order, position, and more
May 09, 2024
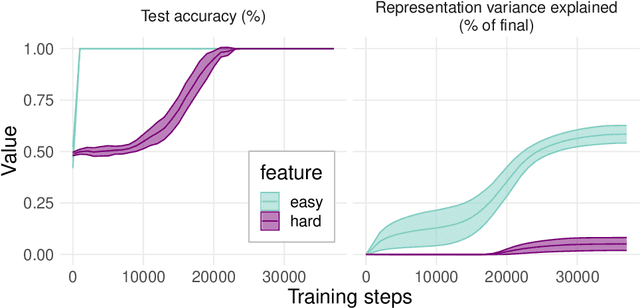

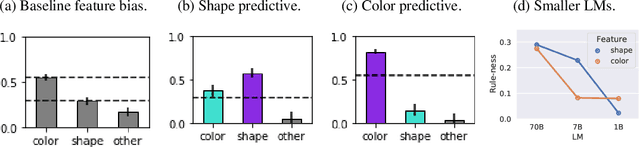
Representation learning, and interpreting learned representations, are key areas of focus in machine learning and neuroscience. Both fields generally use representations as a means to understand or improve a system's computations. In this work, however, we explore surprising dissociations between representation and computation that may pose challenges for such efforts. We create datasets in which we attempt to match the computational role that different features play, while manipulating other properties of the features or the data. We train various deep learning architectures to compute these multiple abstract features about their inputs. We find that their learned feature representations are systematically biased towards representing some features more strongly than others, depending upon extraneous properties such as feature complexity, the order in which features are learned, and the distribution of features over the inputs. For example, features that are simpler to compute or learned first tend to be represented more strongly and densely than features that are more complex or learned later, even if all features are learned equally well. We also explore how these biases are affected by architectures, optimizers, and training regimes (e.g., in transformers, features decoded earlier in the output sequence also tend to be represented more strongly). Our results help to characterize the inductive biases of gradient-based representation learning. These results also highlight a key challenge for interpretability $-$ or for comparing the representations of models and brains $-$ disentangling extraneous biases from the computationally important aspects of a system's internal representations.
What needs to go right for an induction head? A mechanistic study of in-context learning circuits and their formation
Apr 10, 2024



In-context learning is a powerful emergent ability in transformer models. Prior work in mechanistic interpretability has identified a circuit element that may be critical for in-context learning -- the induction head (IH), which performs a match-and-copy operation. During training of large transformers on natural language data, IHs emerge around the same time as a notable phase change in the loss. Despite the robust evidence for IHs and this interesting coincidence with the phase change, relatively little is known about the diversity and emergence dynamics of IHs. Why is there more than one IH, and how are they dependent on each other? Why do IHs appear all of a sudden, and what are the subcircuits that enable them to emerge? We answer these questions by studying IH emergence dynamics in a controlled setting by training on synthetic data. In doing so, we develop and share a novel optogenetics-inspired causal framework for modifying activations throughout training. Using this framework, we delineate the diverse and additive nature of IHs. By clamping subsets of activations throughout training, we then identify three underlying subcircuits that interact to drive IH formation, yielding the phase change. Furthermore, these subcircuits shed light on data-dependent properties of formation, such as phase change timing, already showing the promise of this more in-depth understanding of subcircuits that need to "go right" for an induction head.
The Transient Nature of Emergent In-Context Learning in Transformers
Nov 15, 2023



Transformer neural networks can exhibit a surprising capacity for in-context learning (ICL) despite not being explicitly trained for it. Prior work has provided a deeper understanding of how ICL emerges in transformers, e.g. through the lens of mechanistic interpretability, Bayesian inference, or by examining the distributional properties of training data. However, in each of these cases, ICL is treated largely as a persistent phenomenon; namely, once ICL emerges, it is assumed to persist asymptotically. Here, we show that the emergence of ICL during transformer training is, in fact, often transient. We train transformers on synthetic data designed so that both ICL and in-weights learning (IWL) strategies can lead to correct predictions. We find that ICL first emerges, then disappears and gives way to IWL, all while the training loss decreases, indicating an asymptotic preference for IWL. The transient nature of ICL is observed in transformers across a range of model sizes and datasets, raising the question of how much to "overtrain" transformers when seeking compact, cheaper-to-run models. We find that L2 regularization may offer a path to more persistent ICL that removes the need for early stopping based on ICL-style validation tasks. Finally, we present initial evidence that ICL transience may be caused by competition between ICL and IWL circuits.
Transformers generalize differently from information stored in context vs in weights
Oct 11, 2022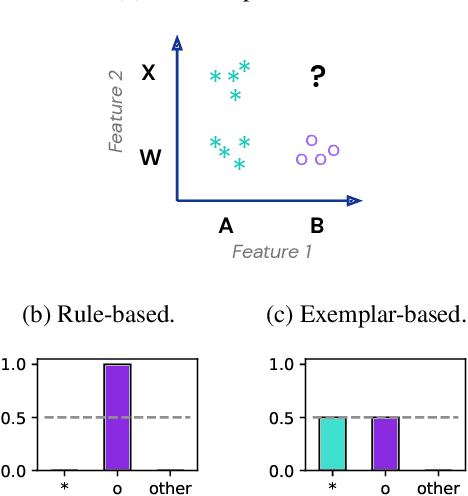
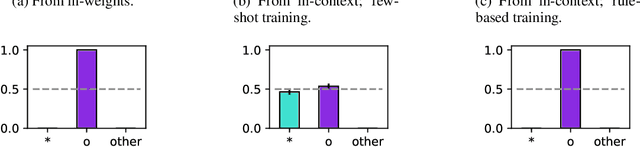
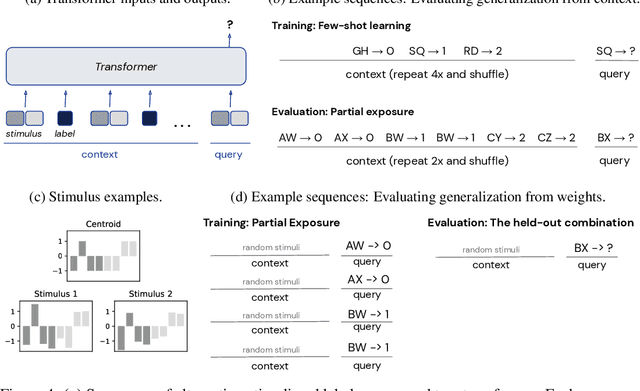
Transformer models can use two fundamentally different kinds of information: information stored in weights during training, and information provided ``in-context'' at inference time. In this work, we show that transformers exhibit different inductive biases in how they represent and generalize from the information in these two sources. In particular, we characterize whether they generalize via parsimonious rules (rule-based generalization) or via direct comparison with observed examples (exemplar-based generalization). This is of important practical consequence, as it informs whether to encode information in weights or in context, depending on how we want models to use that information. In transformers trained on controlled stimuli, we find that generalization from weights is more rule-based whereas generalization from context is largely exemplar-based. In contrast, we find that in transformers pre-trained on natural language, in-context learning is significantly rule-based, with larger models showing more rule-basedness. We hypothesise that rule-based generalization from in-context information might be an emergent consequence of large-scale training on language, which has sparse rule-like structure. Using controlled stimuli, we verify that transformers pretrained on data containing sparse rule-like structure exhibit more rule-based generalization.