 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the generalization of language models from in-context learning and finetuning: a controlled study
May 01, 2025Large language models exhibit exciting capabilities, yet can show surprisingly narrow generalization from finetuning -- from failing to generalize to simple reversals of relations they are trained on, to missing logical deductions that can be made from trained information. These failures to generalize from fine-tuning can hinder practical application of these models. However, language models' in-context learning shows different inductive biases, and can generalize better in some of these cases. Here, we explore these differences in generalization between in-context- and fine-tuning-based learning. To do so, we constructed several novel datasets to evaluate and improve models' ability to generalize from finetuning data. The datasets are constructed to isolate the knowledge in the dataset from that in pretraining, to create clean tests of generalization. We expose pretrained large models to controlled subsets of the information in these datasets -- either in context, or through fine-tuning -- and evaluate their performance on test sets that require various types of generalization. We find overall that in data-matched settings, in-context learning can generalize more flexibly than fine-tuning (though we also find some qualifications of prior findings, such as cases when fine-tuning can generalize to reversals embedded in a larger structure of knowledge). We build on these findings to propose a method to enable improved generalization from fine-tuning: adding in-context inferences to finetuning data. We show that this method improves generalization across various splits of our datasets and other benchmarks. Our results have implications for understanding the inductive biases of different modes of learning in language models, and practically improving their performance.
LLMs are Greedy Agents: Effects of RL Fine-tuning on Decision-Making Abilities
Apr 22, 2025The success of Large Language Models (LLMs) has sparked interest in various agentic applications. A key hypothesis is that LLMs, leveraging common sense and Chain-of-Thought (CoT) reasoning, can effectively explore and efficiently solve complex domains. However, LLM agents have been found to suffer from sub-optimal exploration and the knowing-doing gap, the inability to effectively act on knowledge present in the model. In this work, we systematically study why LLMs perform sub-optimally in decision-making scenarios. In particular, we closely examine three prevalent failure modes: greediness, frequency bias, and the knowing-doing gap. We propose mitigation of these shortcomings by fine-tuning via Reinforcement Learning (RL) on self-generated CoT rationales. Our experiments across multi-armed bandits, contextual bandits, and Tic-tac-toe, demonstrate that RL fine-tuning enhances the decision-making abilities of LLMs by increasing exploration and narrowing the knowing-doing gap. Finally, we study both classic exploration mechanisms, such as $\epsilon$-greedy, and LLM-specific approaches, such as self-correction and self-consistency, to enable more effective fine-tuning of LLMs for decision-making.
How do language models learn facts? Dynamics, curricula and hallucinations
Mar 27, 2025Large language models accumulate vast knowledge during pre-training, yet the dynamics governing this acquisition remain poorly understood. This work investigates the learning dynamics of language models on a synthetic factual recall task, uncovering three key findings: First, language models learn in three phases, exhibiting a performance plateau before acquiring precise factual knowledge. Mechanistically, this plateau coincides with the formation of attention-based circuits that support recall. Second, the training data distribution significantly impacts learning dynamics, as imbalanced distributions lead to shorter plateaus. Finally, hallucinations emerge simultaneously with knowledge, and integrating new knowledge into the model through fine-tuning is challenging, as it quickly corrupts its existing parametric memories. Our results emphasize the importance of data distribution in knowledge acquisition and suggest novel data scheduling strategies to accelerate neural network training.
Towards Robust and Efficient Continual Language Learning
Jul 11, 2023



As the application space of language models continues to evolve, a natural question to ask is how we can quickly adapt models to new tasks. We approach this classic question from a continual learning perspective, in which we aim to continue fine-tuning models trained on past tasks on new tasks, with the goal of "transferring" relevant knowledge. However, this strategy also runs the risk of doing more harm than good, i.e., negative transfer. In this paper, we construct a new benchmark of task sequences that target different possible transfer scenarios one might face, such as a sequence of tasks with high potential of positive transfer, high potential for negative transfer, no expected effect, or a mixture of each. An ideal learner should be able to maximally exploit information from all tasks that have any potential for positive transfer, while also avoiding the negative effects of any distracting tasks that may confuse it. We then propose a simple, yet effective, learner that satisfies many of our desiderata simply by leveraging a selective strategy for initializing new models from past task checkpoints. Still, limitations remain, and we hope this benchmark can help the community to further build and analyze such learners.
When Does Re-initialization Work?
Jun 20, 2022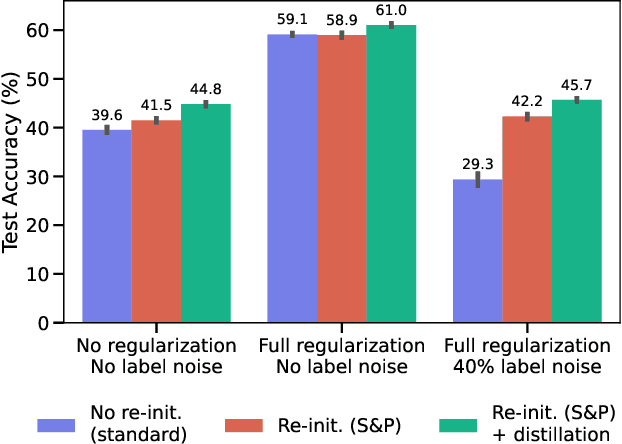
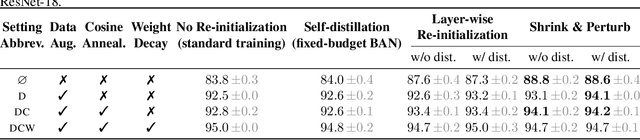
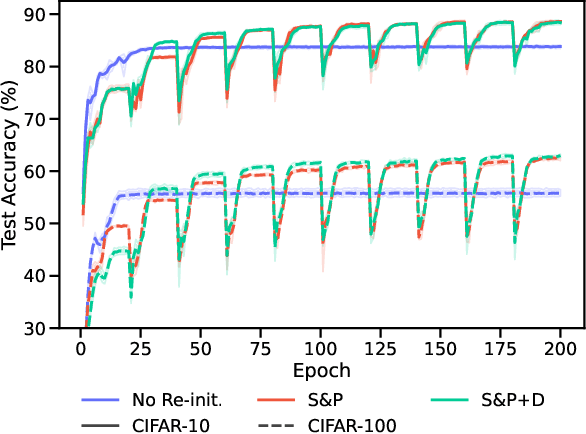

Re-initializing a neural network during training has been observed to improve generalization in recent works. Yet it is neither widely adopted in deep learning practice nor is it often used in state-of-the-art training protocols. This raises the question of when re-initialization works, and whether it should be used together with regularization techniques such as data augmentation, weight decay and learning rate schedules. In this work, we conduct an extensive empirical comparison of standard training with a selection of re-initialization methods to answer this question, training over 15,000 models on a variety of image classification benchmarks. We first establish that such methods are consistently beneficial for generalization in the absence of any other regularization. However, when deployed alongside other carefully tuned regularization techniques, re-initialization methods offer little to no added benefit for generalization, although optimal generalization performance becomes less sensitive to the choice of learning rate and weight decay hyperparameters. To investigate the impact of re-initialization methods on noisy data, we also consider learning under label noise. Surprisingly, in this case, re-initialization significantly improves upon standard training, even in the presence of other carefully tuned regularization techniques.
ProSper -- A Python Library for Probabilistic Sparse Coding with Non-Standard Priors and Superpositions
Aug 01, 2019
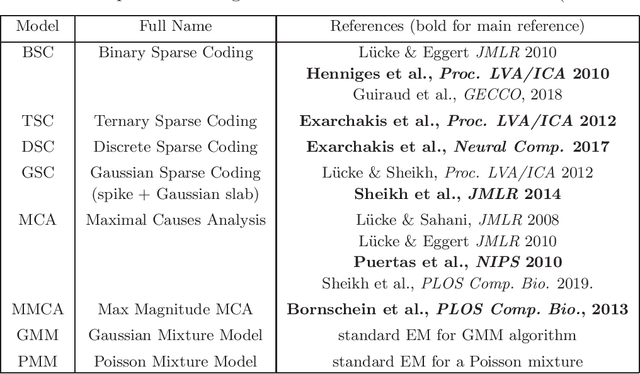
ProSper is a python library containing probabilistic algorithms to learn dictionaries. Given a set of data points, the implemented algorithms seek to learn the elementary components that have generated the data. The library widens the scope of dictionary learning approaches beyond implementations of standard approaches such as ICA, NMF or standard L1 sparse coding. The implemented algorithms are especially well-suited in cases when data consist of components that combine non-linearly and/or for data requiring flexible prior distributions. Furthermore, the implemented algorithms go beyond standard approaches by inferring prior and noise parameters of the data, and they provide rich a-posteriori approximations for inference. The library is designed to be extendable and it currently includes: Binary Sparse Coding (BSC), Ternary Sparse Coding (TSC), Discrete Sparse Coding (DSC), Maximal Causes Analysis (MCA), Maximum Magnitude Causes Analysis (MMCA), and Gaussian Sparse Coding (GSC, a recent spike-and-slab sparse coding approach). The algorithms are scalable due to a combination of variational approximations and parallelization. Implementations of all algorithms allow for parallel execution on multiple CPUs and multiple machines for medium to large-scale applications. Typical large-scale runs of the algorithms can use hundreds of CPUs to learn hundreds of dictionary elements from data with tens of millions of floating-point numbers such that models with several hundred thousand parameters can be optimized. The library is designed to have minimal dependencies and to be easy to use. It targets users of dictionary learning algorithms and Machine Learning researchers.
Variational Memory Addressing in Generative Models
Sep 21, 2017
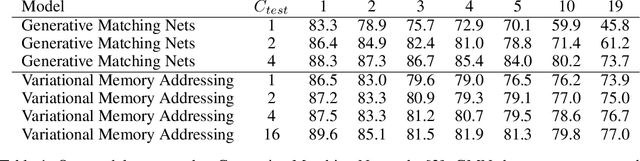

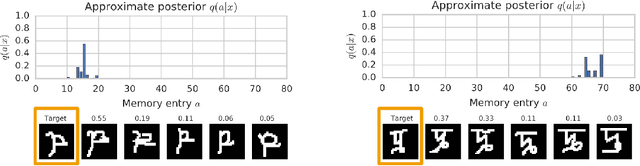
Aiming to augment generative models with external memory, we interpret the output of a memory module with stochastic addressing as a conditional mixture distribution, where a read operation corresponds to sampling a discrete memory address and retrieving the corresponding content from memory. This perspective allows us to apply variational inference to memory addressing, which enables effective training of the memory module by using the target information to guide memory lookups. Stochastic addressing is particularly well-suited for generative models as it naturally encourages multimodality which is a prominent aspect of most high-dimensional datasets. Treating the chosen address as a latent variable also allows us to quantify the amount of information gained with a memory lookup and measure the contribution of the memory module to the generative process. To illustrate the advantages of this approach we incorporate it into a variational autoencoder and apply the resulting model to the task of generative few-shot learning. The intuition behind this architecture is that the memory module can pick a relevant template from memory and the continuous part of the model can concentrate on modeling remaining variations. We demonstrate empirically that our model is able to identify and access the relevant memory contents even with hundreds of unseen Omniglot characters in memory
Reweighted Wake-Sleep
Apr 16, 2015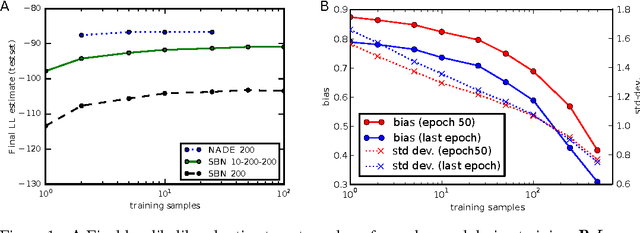



Training deep directed graphical models with many hidden variables and performing inference remains a major challenge. Helmholtz machines and deep belief networks are such models, and the wake-sleep algorithm has been proposed to train them. The wake-sleep algorithm relies on training not just the directed generative model but also a conditional generative model (the inference network) that runs backward from visible to latent, estimating the posterior distribution of latent given visible. We propose a novel interpretation of the wake-sleep algorithm which suggests that better estimators of the gradient can be obtained by sampling latent variables multiple times from the inference network. This view is based on importance sampling as an estimator of the likelihood, with the approximate inference network as a proposal distribution. This interpretation is confirmed experimentally, showing that better likelihood can be achieved with this reweighted wake-sleep procedure. Based on this interpretation, we propose that a sigmoidal belief network is not sufficiently powerful for the layers of the inference network in order to recover a good estimator of the posterior distribution of latent variables. Our experiments show that using a more powerful layer model, such as NADE, yields substantially better generative models.