 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReweighted Wake-Sleep
Paper and Code
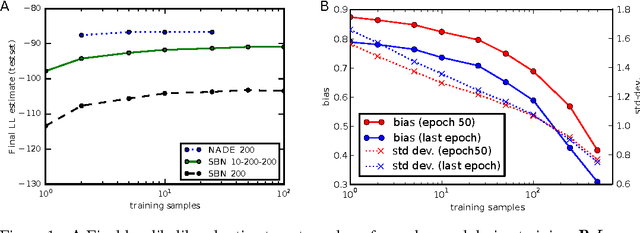



Training deep directed graphical models with many hidden variables and performing inference remains a major challenge. Helmholtz machines and deep belief networks are such models, and the wake-sleep algorithm has been proposed to train them. The wake-sleep algorithm relies on training not just the directed generative model but also a conditional generative model (the inference network) that runs backward from visible to latent, estimating the posterior distribution of latent given visible. We propose a novel interpretation of the wake-sleep algorithm which suggests that better estimators of the gradient can be obtained by sampling latent variables multiple times from the inference network. This view is based on importance sampling as an estimator of the likelihood, with the approximate inference network as a proposal distribution. This interpretation is confirmed experimentally, showing that better likelihood can be achieved with this reweighted wake-sleep procedure. Based on this interpretation, we propose that a sigmoidal belief network is not sufficiently powerful for the layers of the inference network in order to recover a good estimator of the posterior distribution of latent variables. Our experiments show that using a more powerful layer model, such as NADE, yields substantially better generative models.