 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgepLSTM: parallelizable Linear Source Transition Mark networks
Jun 13, 2025Modern recurrent architectures, such as xLSTM and Mamba, have recently challenged the Transformer in language modeling. However, their structure constrains their applicability to sequences only or requires processing multi-dimensional data structures, such as images or molecular graphs, in a pre-defined sequential order. In contrast, Multi-Dimensional RNNs (MDRNNs) are well suited for data with a higher level structure, like 2D grids, trees, and directed acyclic graphs (DAGs). In this work, we extend the notion of multi-dimensionality to linear RNNs. We introduce parallelizable Linear Source Transition Mark networks (pLSTMs) using Source, Transition, and Mark gates that act on the line graph of a general DAG. This enables parallelization in analogy to parallel associative scans and the chunkwise-recurrent form of sequential linear RNNs, but for DAGs. For regular grids (1D and 2D), like images, this scheme can be efficiently implemented using einsum operations, concatenations, and padding in logarithmic time. pLSTMs tackle the vanishing/exploding activation/gradient problem for long distances in DAGs via two distinct modes: a directed propagation mode (P-mode) and a diffusive distribution mode (D-mode). To showcase the long-range capabilities of pLSTM, we introduce arrow-pointing extrapolation as a synthetic computer vision task that contains long-distance directional information. We demonstrate that pLSTMs generalize well to larger image sizes, whereas Transformers struggle to extrapolate. On established molecular graph and computer vision benchmarks, pLSTMs also show strong performance. Code and Datasets are available at: https://github.com/ml-jku/plstm_experiments.
LLMs are Greedy Agents: Effects of RL Fine-tuning on Decision-Making Abilities
Apr 22, 2025The success of Large Language Models (LLMs) has sparked interest in various agentic applications. A key hypothesis is that LLMs, leveraging common sense and Chain-of-Thought (CoT) reasoning, can effectively explore and efficiently solve complex domains. However, LLM agents have been found to suffer from sub-optimal exploration and the knowing-doing gap, the inability to effectively act on knowledge present in the model. In this work, we systematically study why LLMs perform sub-optimally in decision-making scenarios. In particular, we closely examine three prevalent failure modes: greediness, frequency bias, and the knowing-doing gap. We propose mitigation of these shortcomings by fine-tuning via Reinforcement Learning (RL) on self-generated CoT rationales. Our experiments across multi-armed bandits, contextual bandits, and Tic-tac-toe, demonstrate that RL fine-tuning enhances the decision-making abilities of LLMs by increasing exploration and narrowing the knowing-doing gap. Finally, we study both classic exploration mechanisms, such as $\epsilon$-greedy, and LLM-specific approaches, such as self-correction and self-consistency, to enable more effective fine-tuning of LLMs for decision-making.
A Large Recurrent Action Model: xLSTM enables Fast Inference for Robotics Tasks
Oct 29, 2024In recent years, there has been a trend in the field of Reinforcement Learning (RL) towards large action models trained offline on large-scale datasets via sequence modeling. Existing models are primarily based on the Transformer architecture, which result in powerful agents. However, due to slow inference times, Transformer-based approaches are impractical for real-time applications, such as robotics. Recently, modern recurrent architectures, such as xLSTM and Mamba, have been proposed that exhibit parallelization benefits during training similar to the Transformer architecture while offering fast inference. In this work, we study the aptitude of these modern recurrent architectures for large action models. Consequently, we propose a Large Recurrent Action Model (LRAM) with an xLSTM at its core that comes with linear-time inference complexity and natural sequence length extrapolation abilities. Experiments on 432 tasks from 6 domains show that LRAM compares favorably to Transformers in terms of performance and speed.
Retrieval-Augmented Decision Transformer: External Memory for In-context RL
Oct 09, 2024



In-context learning (ICL) is the ability of a model to learn a new task by observing a few exemplars in its context. While prevalent in NLP, this capability has recently also been observed in Reinforcement Learning (RL) settings. Prior in-context RL methods, however, require entire episodes in the agent's context. Given that complex environments typically lead to long episodes with sparse rewards, these methods are constrained to simple environments with short episodes. To address these challenges, we introduce Retrieval-Augmented Decision Transformer (RA-DT). RA-DT employs an external memory mechanism to store past experiences from which it retrieves only sub-trajectories relevant for the current situation. The retrieval component in RA-DT does not require training and can be entirely domain-agnostic. We evaluate the capabilities of RA-DT on grid-world environments, robotics simulations, and procedurally-generated video games. On grid-worlds, RA-DT outperforms baselines, while using only a fraction of their context length. Furthermore, we illuminate the limitations of current in-context RL methods on complex environments and discuss future directions. To facilitate future research, we release datasets for four of the considered environments.
One Initialization to Rule them All: Fine-tuning via Explained Variance Adaptation
Oct 09, 2024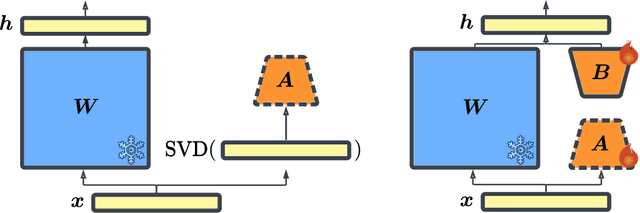
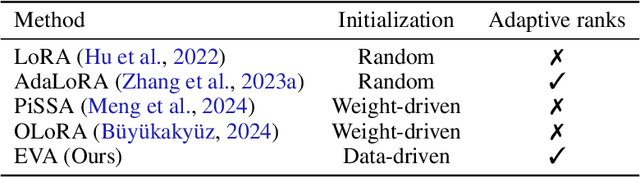
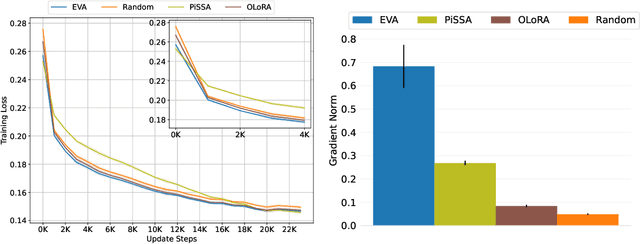
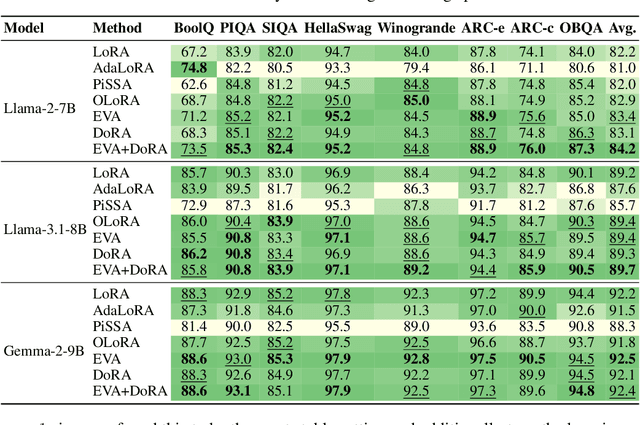
Foundation models (FMs) are pre-trained on large-scale datasets and then fine-tuned on a downstream task for a specific application. The most successful and most commonly used fine-tuning method is to update the pre-trained weights via a low-rank adaptation (LoRA). LoRA introduces new weight matrices that are usually initialized at random with a uniform rank distribution across model weights. Recent works focus on weight-driven initialization or learning of adaptive ranks during training. Both approaches have only been investigated in isolation, resulting in slow convergence or a uniform rank distribution, in turn leading to sub-optimal performance. We propose to enhance LoRA by initializing the new weights in a data-driven manner by computing singular value decomposition on minibatches of activation vectors. Then, we initialize the LoRA matrices with the obtained right-singular vectors and re-distribute ranks among all weight matrices to explain the maximal amount of variance and continue the standard LoRA fine-tuning procedure. This results in our new method Explained Variance Adaptation (EVA). We apply EVA to a variety of fine-tuning tasks ranging from language generation and understanding to image classification and reinforcement learning. EVA exhibits faster convergence than competitors and attains the highest average score across a multitude of tasks per domain.
Learning to Modulate pre-trained Models in RL
Jun 26, 2023Reinforcement Learning (RL) has been successful in various domains like robotics, game playing, and simulation. While RL agents have shown impressive capabilities in their specific tasks, they insufficiently adapt to new tasks. In supervised learning, this adaptation problem is addressed by large-scale pre-training followed by fine-tuning to new down-stream tasks. Recently, pre-training on multiple tasks has been gaining traction in RL. However, fine-tuning a pre-trained model often suffers from catastrophic forgetting, that is, the performance on the pre-training tasks deteriorates when fine-tuning on new tasks. To investigate the catastrophic forgetting phenomenon, we first jointly pre-train a model on datasets from two benchmark suites, namely Meta-World and DMControl. Then, we evaluate and compare a variety of fine-tuning methods prevalent in natural language processing, both in terms of performance on new tasks, and how well performance on pre-training tasks is retained. Our study shows that with most fine-tuning approaches, the performance on pre-training tasks deteriorates significantly. Therefore, we propose a novel method, Learning-to-Modulate (L2M), that avoids the degradation of learned skills by modulating the information flow of the frozen pre-trained model via a learnable modulation pool. Our method achieves state-of-the-art performance on the Continual-World benchmark, while retaining performance on the pre-training tasks. Finally, to aid future research in this area, we release a dataset encompassing 50 Meta-World and 16 DMControl tasks.
Reactive Exploration to Cope with Non-Stationarity in Lifelong Reinforcement Learning
Jul 12, 2022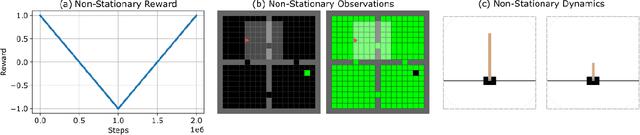
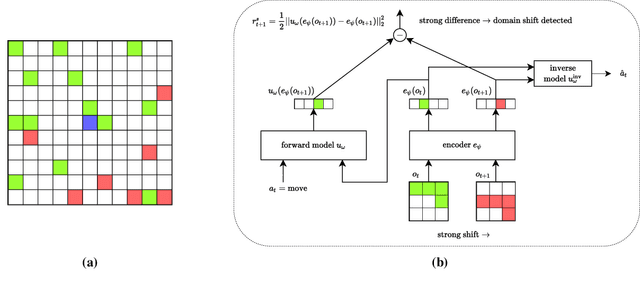
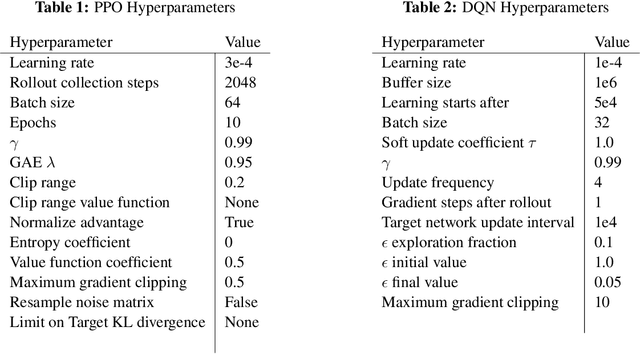
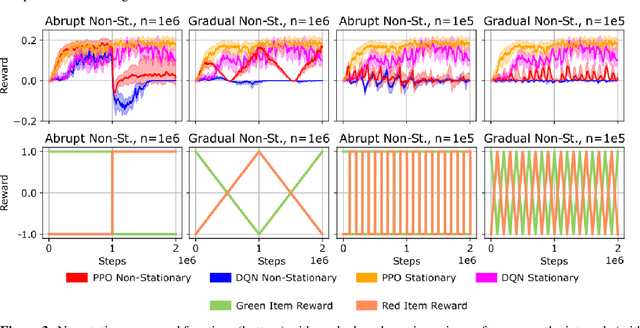
In lifelong learning, an agent learns throughout its entire life without resets, in a constantly changing environment, as we humans do. Consequently, lifelong learning comes with a plethora of research problems such as continual domain shifts, which result in non-stationary rewards and environment dynamics. These non-stationarities are difficult to detect and cope with due to their continuous nature. Therefore, exploration strategies and learning methods are required that are capable of tracking the steady domain shifts, and adapting to them. We propose Reactive Exploration to track and react to continual domain shifts in lifelong reinforcement learning, and to update the policy correspondingly. To this end, we conduct experiments in order to investigate different exploration strategies. We empirically show that representatives of the policy-gradient family are better suited for lifelong learning, as they adapt more quickly to distribution shifts than Q-learning. Thereby, policy-gradient methods profit the most from Reactive Exploration and show good results in lifelong learning with continual domain shifts. Our code is available at: https://github.com/ml-jku/reactive-exploration.
Fast and Data-Efficient Training of Rainbow: an Experimental Study on Atari
Nov 19, 2021



Across the Arcade Learning Environment, Rainbow achieves a level of performance competitive with humans and modern RL algorithms. However, attaining this level of performance requires large amounts of data and hardware resources, making research in this area computationally expensive and use in practical applications often infeasible. This paper's contribution is threefold: We (1) propose an improved version of Rainbow, seeking to drastically reduce Rainbow's data, training time, and compute requirements while maintaining its competitive performance; (2) we empirically demonstrate the effectiveness of our approach through experiments on the Arcade Learning Environment, and (3) we conduct a number of ablation studies to investigate the effect of the individual proposed modifications. Our improved version of Rainbow reaches a median human normalized score close to classic Rainbow's, while using 20 times less data and requiring only 7.5 hours of training time on a single GPU. We also provide our full implementation including pre-trained models.
Towards a General Framework for ML-based Self-tuning Databases
Nov 16, 2020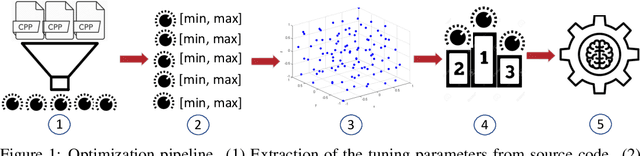
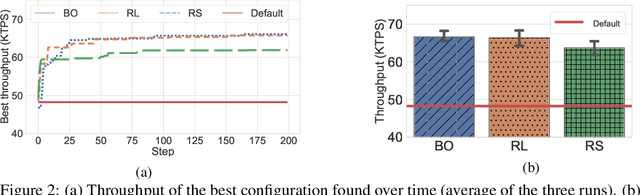
Machine learning (ML) methods have recently emerged as an effective way to perform automated parameter tuning of databases. State-of-the-art approaches include Bayesian optimization (BO) and reinforcement learning (RL). In this work, we describe our experience when applying these methods to a database not yet studied in this context: FoundationDB. Firstly, we describe the challenges we faced, such as unknown valid ranges of configuration parameters and combinations of parameter values that result in invalid runs, and how we mitigated them. While these issues are typically overlooked, we argue that they are a crucial barrier to the adoption of ML self-tuning techniques in databases, and thus deserve more attention from the research community. Secondly, we present experimental results obtained when tuning FoundationDB using ML methods. Unlike prior work in this domain, we also compare with the simplest of baselines: random search. Our results show that, while BO and RL methods can improve the throughput of FoundationDB by up to 38%, random search is a highly competitive baseline, finding a configuration that is only 4% worse than the, vastly more complex, ML methods. We conclude that future work in this area may want to focus more on randomized, model-free optimization algorithms.