 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIDE: AI-Driven Exploration in the Space of Code
Feb 18, 2025Machine learning, the foundation of modern artificial intelligence, has driven innovations that have fundamentally transformed the world. Yet, behind advancements lies a complex and often tedious process requiring labor and compute intensive iteration and experimentation. Engineers and scientists developing machine learning models spend much of their time on trial-and-error tasks instead of conceptualizing innovative solutions or research hypotheses. To address this challenge, we introduce AI-Driven Exploration (AIDE), a machine learning engineering agent powered by large language models (LLMs). AIDE frames machine learning engineering as a code optimization problem, and formulates trial-and-error as a tree search in the space of potential solutions. By strategically reusing and refining promising solutions, AIDE effectively trades computational resources for enhanced performance, achieving state-of-the-art results on multiple machine learning engineering benchmarks, including our Kaggle evaluations, OpenAI MLE-Bench and METRs RE-Bench.
Towards Generalist Robot Learning from Internet Video: A Survey
Apr 30, 2024



This survey presents an overview of methods for learning from video (LfV) in the context of reinforcement learning (RL) and robotics. We focus on methods capable of scaling to large internet video datasets and, in the process, extracting foundational knowledge about the world's dynamics and physical human behaviour. Such methods hold great promise for developing general-purpose robots. We open with an overview of fundamental concepts relevant to the LfV-for-robotics setting. This includes a discussion of the exciting benefits LfV methods can offer (e.g., improved generalization beyond the available robot data) and commentary on key LfV challenges (e.g., challenges related to missing information in video and LfV distribution shifts). Our literature review begins with an analysis of video foundation model techniques that can extract knowledge from large, heterogeneous video datasets. Next, we review methods that specifically leverage video data for robot learning. Here, we categorise work according to which RL knowledge modality benefits from the use of video data. We additionally highlight techniques for mitigating LfV challenges, including reviewing action representations that address the issue of missing action labels in video. Finally, we examine LfV datasets and benchmarks, before concluding the survey by discussing challenges and opportunities in LfV. Here, we advocate for scalable approaches that can leverage the full range of available data and that target the key benefits of LfV. Overall, we hope this survey will serve as a comprehensive reference for the emerging field of LfV, catalysing further research in the area, and ultimately facilitating progress towards obtaining general-purpose robots.
Learning to Act without Actions
Dec 17, 2023

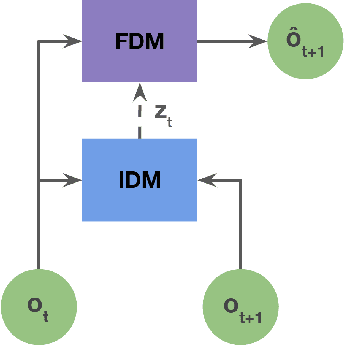

Pre-training large models on vast amounts of web data has proven to be an effective approach for obtaining powerful, general models in several domains, including language and vision. However, this paradigm has not yet taken hold in deep reinforcement learning (RL). This gap is due to the fact that the most abundant form of embodied behavioral data on the web consists of videos, which do not include the action labels required by existing methods for training policies from offline data. We introduce Latent Action Policies from Observation (LAPO), a method to infer latent actions and, consequently, latent-action policies purely from action-free demonstrations. Our experiments on challenging procedurally-generated environments show that LAPO can act as an effective pre-training method to obtain RL policies that can then be rapidly fine-tuned to expert-level performance. Our approach serves as a key stepping stone to enabling the pre-training of powerful, generalist RL models on the vast amounts of action-free demonstrations readily available on the web.
Fast and Data-Efficient Training of Rainbow: an Experimental Study on Atari
Nov 19, 2021



Across the Arcade Learning Environment, Rainbow achieves a level of performance competitive with humans and modern RL algorithms. However, attaining this level of performance requires large amounts of data and hardware resources, making research in this area computationally expensive and use in practical applications often infeasible. This paper's contribution is threefold: We (1) propose an improved version of Rainbow, seeking to drastically reduce Rainbow's data, training time, and compute requirements while maintaining its competitive performance; (2) we empirically demonstrate the effectiveness of our approach through experiments on the Arcade Learning Environment, and (3) we conduct a number of ablation studies to investigate the effect of the individual proposed modifications. Our improved version of Rainbow reaches a median human normalized score close to classic Rainbow's, while using 20 times less data and requiring only 7.5 hours of training time on a single GPU. We also provide our full implementation including pre-trained models.
Inferring Dynamical Systems with Long-Range Dependencies through Line Attractor Regularization
Oct 08, 2019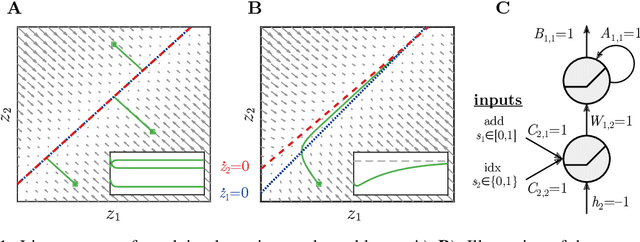

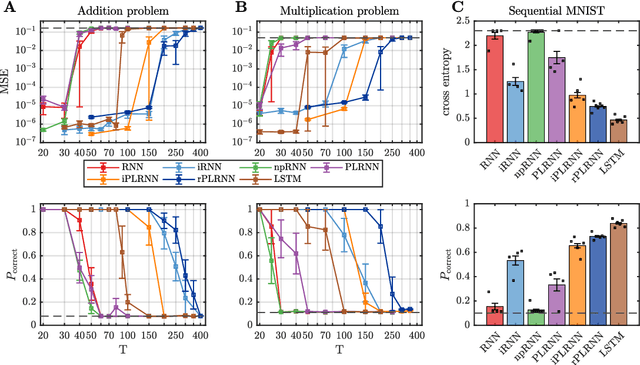
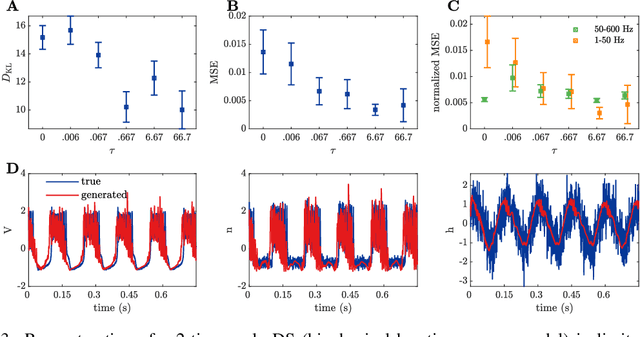
Vanilla RNN with ReLU activation have a simple structure that is amenable to systematic dynamical systems analysis and interpretation, but they suffer from the exploding vs. vanishing gradients problem. Recent attempts to retain this simplicity while alleviating the gradient problem are based on proper initialization schemes or orthogonality/unitary constraints on the RNN's recurrence matrix, which, however, comes with limitations to its expressive power with regards to dynamical systems phenomena like chaos or multi-stability. Here, we instead suggest a regularization scheme that pushes part of the RNN's latent subspace toward a line attractor configuration that enables long short-term memory and arbitrarily slow time scales. We show that our approach excels on a number of benchmarks like the sequential MNIST or multiplication problems, and enables reconstruction of dynamical systems which harbor widely different time scales.