 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Video Masked Autoencoders
Dec 15, 2025We present Recurrent Video Masked-Autoencoders (RVM): a novel video representation learning approach that uses a transformer-based recurrent neural network to aggregate dense image features over time, effectively capturing the spatio-temporal structure of natural video data. RVM learns via an asymmetric masked prediction task requiring only a standard pixel reconstruction objective. This design yields a highly efficient ``generalist'' encoder: RVM achieves competitive performance with state-of-the-art video models (e.g. VideoMAE, V-JEPA) on video-level tasks like action recognition and point/object tracking, while also performing favorably against image models (e.g. DINOv2) on tasks that test geometric and dense spatial understanding. Notably, RVM achieves strong performance in the small-model regime without requiring knowledge distillation, exhibiting up to 30x greater parameter efficiency than competing video masked autoencoders. Moreover, we demonstrate that RVM's recurrent nature allows for stable feature propagation over long temporal horizons with linear computational cost, overcoming some of the limitations of standard spatio-temporal attention-based architectures. Finally, we use qualitative visualizations to highlight that RVM learns rich representations of scene semantics, structure, and motion.
Learning from Streaming Video with Orthogonal Gradients
Apr 02, 2025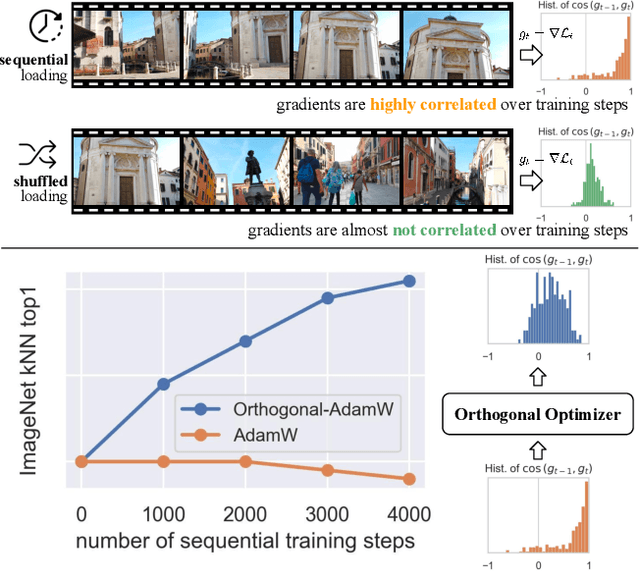
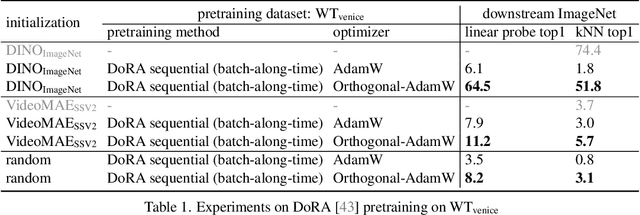
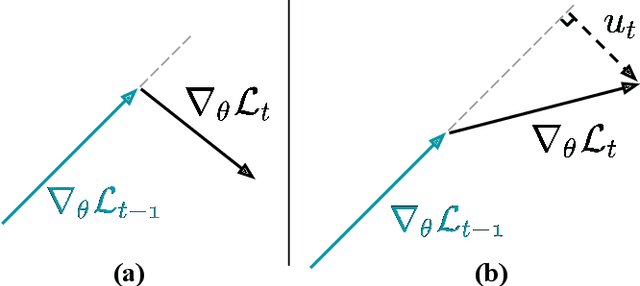
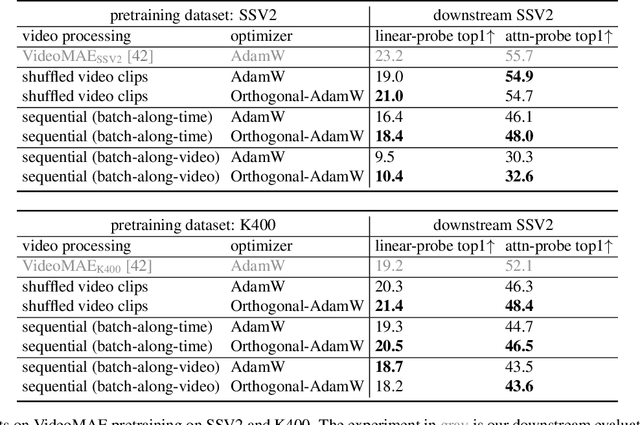
We address the challenge of representation learning from a continuous stream of video as input, in a self-supervised manner. This differs from the standard approaches to video learning where videos are chopped and shuffled during training in order to create a non-redundant batch that satisfies the independently and identically distributed (IID) sample assumption expected by conventional training paradigms. When videos are only available as a continuous stream of input, the IID assumption is evidently broken, leading to poor performance. We demonstrate the drop in performance when moving from shuffled to sequential learning on three tasks: the one-video representation learning method DoRA, standard VideoMAE on multi-video datasets, and the task of future video prediction. To address this drop, we propose a geometric modification to standard optimizers, to decorrelate batches by utilising orthogonal gradients during training. The proposed modification can be applied to any optimizer -- we demonstrate it with Stochastic Gradient Descent (SGD) and AdamW. Our proposed orthogonal optimizer allows models trained from streaming videos to alleviate the drop in representation learning performance, as evaluated on downstream tasks. On three scenarios (DoRA, VideoMAE, future prediction), we show our orthogonal optimizer outperforms the strong AdamW in all three scenarios.
Scaling 4D Representations
Dec 19, 2024



Scaling has not yet been convincingly demonstrated for pure self-supervised learning from video. However, prior work has focused evaluations on semantic-related tasks $\unicode{x2013}$ action classification, ImageNet classification, etc. In this paper we focus on evaluating self-supervised learning on non-semantic vision tasks that are more spatial (3D) and temporal (+1D = 4D), such as camera pose estimation, point and object tracking, and depth estimation. We show that by learning from very large video datasets, masked auto-encoding (MAE) with transformer video models actually scales, consistently improving performance on these 4D tasks, as model size increases from 20M all the way to the largest by far reported self-supervised video model $\unicode{x2013}$ 22B parameters. Rigorous apples-to-apples comparison with many recent image and video models demonstrates the benefits of scaling 4D representations.
Moving Off-the-Grid: Scene-Grounded Video Representations
Nov 08, 2024



Current vision models typically maintain a fixed correspondence between their representation structure and image space. Each layer comprises a set of tokens arranged "on-the-grid," which biases patches or tokens to encode information at a specific spatio(-temporal) location. In this work we present Moving Off-the-Grid (MooG), a self-supervised video representation model that offers an alternative approach, allowing tokens to move "off-the-grid" to better enable them to represent scene elements consistently, even as they move across the image plane through time. By using a combination of cross-attention and positional embeddings we disentangle the representation structure and image structure. We find that a simple self-supervised objective--next frame prediction--trained on video data, results in a set of latent tokens which bind to specific scene structures and track them as they move. We demonstrate the usefulness of MooG's learned representation both qualitatively and quantitatively by training readouts on top of the learned representation on a variety of downstream tasks. We show that MooG can provide a strong foundation for different vision tasks when compared to "on-the-grid" baselines.
Learning from One Continuous Video Stream
Dec 01, 2023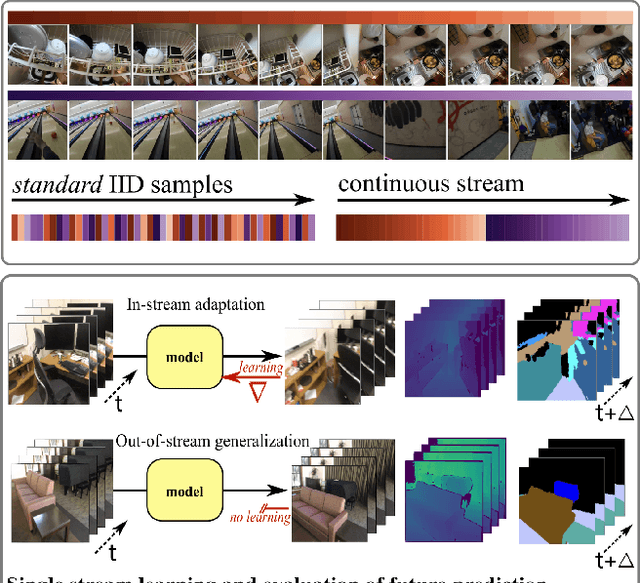

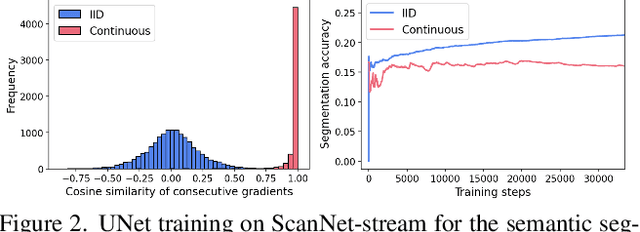

We introduce a framework for online learning from a single continuous video stream -- the way people and animals learn, without mini-batches, data augmentation or shuffling. This poses great challenges given the high correlation between consecutive video frames and there is very little prior work on it. Our framework allows us to do a first deep dive into the topic and includes a collection of streams and tasks composed from two existing video datasets, plus methodology for performance evaluation that considers both adaptation and generalization. We employ pixel-to-pixel modelling as a practical and flexible way to switch between pre-training and single-stream evaluation as well as between arbitrary tasks, without ever requiring changes to models and always using the same pixel loss. Equipped with this framework we obtained large single-stream learning gains from pre-training with a novel family of future prediction tasks, found that momentum hurts, and that the pace of weight updates matters. The combination of these insights leads to matching the performance of IID learning with batch size 1, when using the same architecture and without costly replay buffers.
SODA: Bottleneck Diffusion Models for Representation Learning
Nov 29, 2023We introduce SODA, a self-supervised diffusion model, designed for representation learning. The model incorporates an image encoder, which distills a source view into a compact representation, that, in turn, guides the generation of related novel views. We show that by imposing a tight bottleneck between the encoder and a denoising decoder, and leveraging novel view synthesis as a self-supervised objective, we can turn diffusion models into strong representation learners, capable of capturing visual semantics in an unsupervised manner. To the best of our knowledge, SODA is the first diffusion model to succeed at ImageNet linear-probe classification, and, at the same time, it accomplishes reconstruction, editing and synthesis tasks across a wide range of datasets. Further investigation reveals the disentangled nature of its emergent latent space, that serves as an effective interface to control and manipulate the model's produced images. All in all, we aim to shed light on the exciting and promising potential of diffusion models, not only for image generation, but also for learning rich and robust representations.
Combining Behaviors with the Successor Features Keyboard
Oct 24, 2023The Option Keyboard (OK) was recently proposed as a method for transferring behavioral knowledge across tasks. OK transfers knowledge by adaptively combining subsets of known behaviors using Successor Features (SFs) and Generalized Policy Improvement (GPI). However, it relies on hand-designed state-features and task encodings which are cumbersome to design for every new environment. In this work, we propose the "Successor Features Keyboard" (SFK), which enables transfer with discovered state-features and task encodings. To enable discovery, we propose the "Categorical Successor Feature Approximator" (CSFA), a novel learning algorithm for estimating SFs while jointly discovering state-features and task encodings. With SFK and CSFA, we achieve the first demonstration of transfer with SFs in a challenging 3D environment where all the necessary representations are discovered. We first compare CSFA against other methods for approximating SFs and show that only CSFA discovers representations compatible with SF&GPI at this scale. We then compare SFK against transfer learning baselines and show that it transfers most quickly to long-horizon tasks.
Laser: Latent Set Representations for 3D Generative Modeling
Jan 13, 2023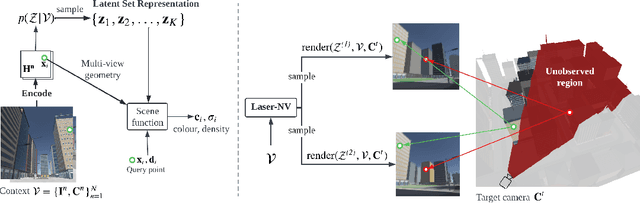
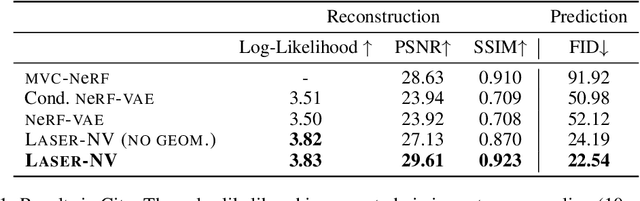


NeRF provides unparalleled fidelity of novel view synthesis: rendering a 3D scene from an arbitrary viewpoint. NeRF requires training on a large number of views that fully cover a scene, which limits its applicability. While these issues can be addressed by learning a prior over scenes in various forms, previous approaches have been either applied to overly simple scenes or struggling to render unobserved parts. We introduce Laser-NV: a generative model which achieves high modelling capacity, and which is based on a set-valued latent representation modelled by normalizing flows. Similarly to previous amortized approaches, Laser-NV learns structure from multiple scenes and is capable of fast, feed-forward inference from few views. To encourage higher rendering fidelity and consistency with observed views, Laser-NV further incorporates a geometry-informed attention mechanism over the observed views. Laser-NV further produces diverse and plausible completions of occluded parts of a scene while remaining consistent with observations. Laser-NV shows state-of-the-art novel-view synthesis quality when evaluated on ShapeNet and on a novel simulated City dataset, which features high uncertainty in the unobserved regions of the scene.
Solving Reasoning Tasks with a Slot Transformer
Oct 20, 2022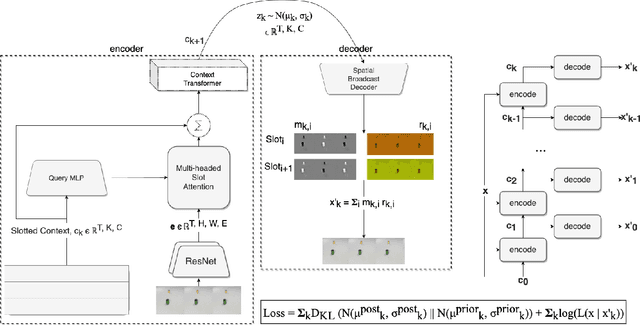
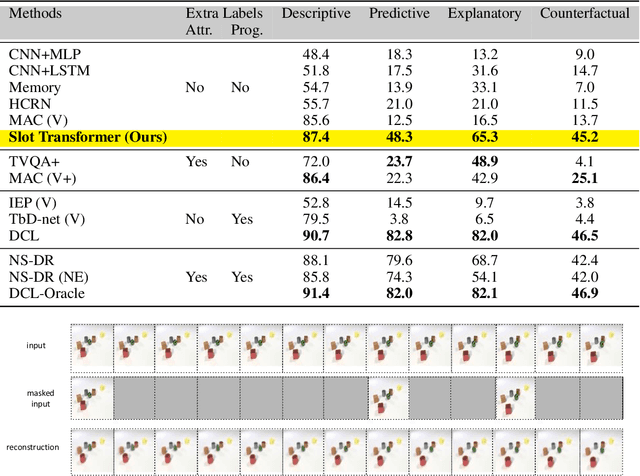
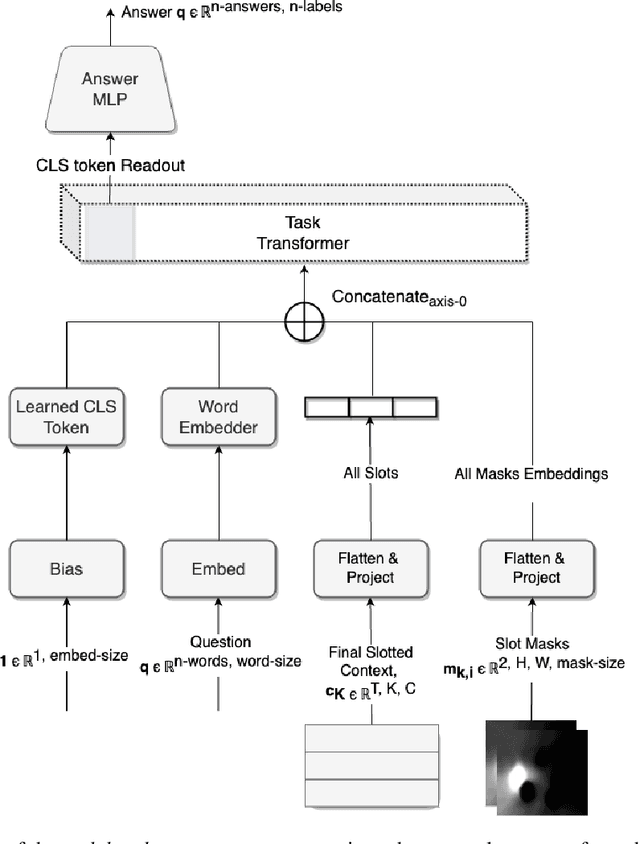
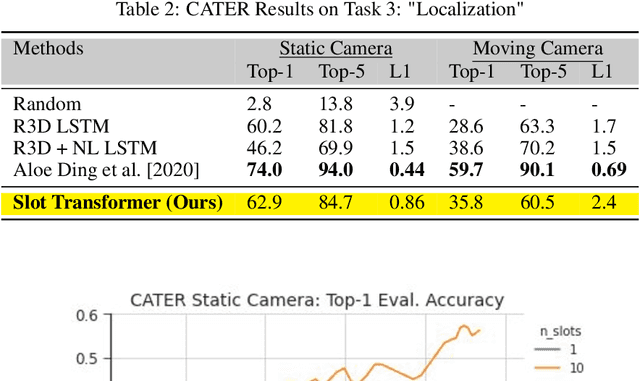
The ability to carve the world into useful abstractions in order to reason about time and space is a crucial component of intelligence. In order to successfully perceive and act effectively using senses we must parse and compress large amounts of information for further downstream reasoning to take place, allowing increasingly complex concepts to emerge. If there is any hope to scale representation learning methods to work with real world scenes and temporal dynamics then there must be a way to learn accurate, concise, and composable abstractions across time. We present the Slot Transformer, an architecture that leverages slot attention, transformers and iterative variational inference on video scene data to infer such representations. We evaluate the Slot Transformer on CLEVRER, Kinetics-600 and CATER datesets and demonstrate that the approach allows us to develop robust modeling and reasoning around complex behaviours as well as scores on these datasets that compare favourably to existing baselines. Finally we evaluate the effectiveness of key components of the architecture, the model's representational capacity and its ability to predict from incomplete input.
Object discovery and representation networks
Mar 16, 2022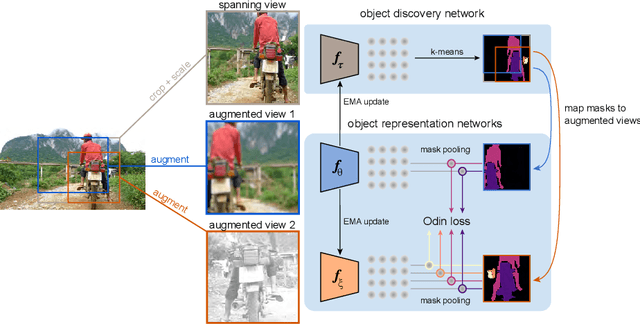
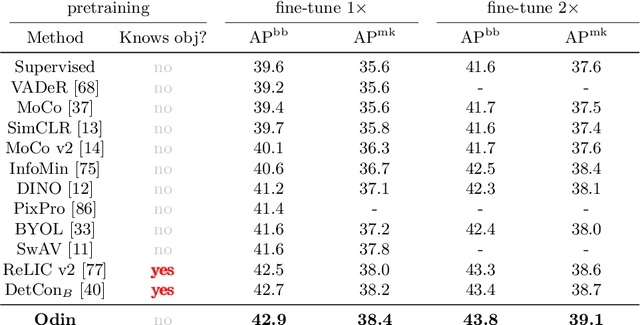


The promise of self-supervised learning (SSL) is to leverage large amounts of unlabeled data to solve complex tasks. While there has been excellent progress with simple, image-level learning, recent methods have shown the advantage of including knowledge of image structure. However, by introducing hand-crafted image segmentations to define regions of interest, or specialized augmentation strategies, these methods sacrifice the simplicity and generality that makes SSL so powerful. Instead, we propose a self-supervised learning paradigm that discovers the structure encoded in these priors by itself. Our method, Odin, couples object discovery and representation networks to discover meaningful image segmentations without any supervision. The resulting learning paradigm is simpler, less brittle, and more general, and achieves state-of-the-art transfer learning results for object detection and instance segmentation on COCO, and semantic segmentation on PASCAL and Cityscapes, while strongly surpassing supervised pre-training for video segmentation on DAVIS.