 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Should I Spend My FLOPS? Efficiency Evaluations of Visual Pre-training Methods
Oct 06, 2022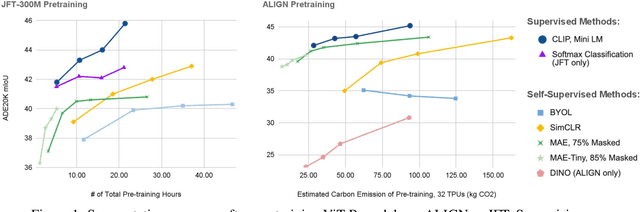
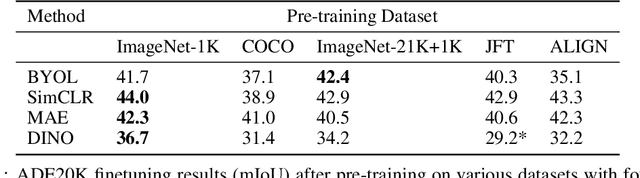
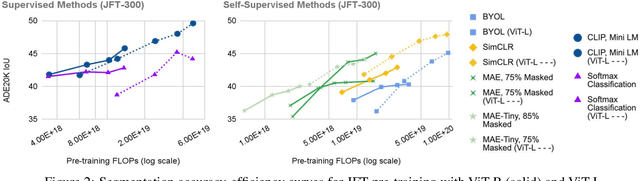
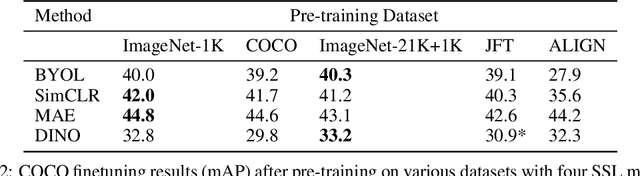
Self-supervised methods have achieved remarkable success in transfer learning, often achieving the same or better accuracy than supervised pre-training. Most prior work has done so by increasing pre-training computation by adding complex data augmentation, multiple views, or lengthy training schedules. In this work, we investigate a related, but orthogonal question: given a fixed FLOP budget, what are the best datasets, models, and (self-)supervised training methods for obtaining high accuracy on representative visual tasks? Given the availability of large datasets, this setting is often more relevant for both academic and industry labs alike. We examine five large-scale datasets (JFT-300M, ALIGN, ImageNet-1K, ImageNet-21K, and COCO) and six pre-training methods (CLIP, DINO, SimCLR, BYOL, Masked Autoencoding, and supervised). In a like-for-like fashion, we characterize their FLOP and CO$_2$ footprints, relative to their accuracy when transferred to a canonical image segmentation task. Our analysis reveals strong disparities in the computational efficiency of pre-training methods and their dependence on dataset quality. In particular, our results call into question the commonly-held assumption that self-supervised methods inherently scale to large, uncurated data. We therefore advocate for (1) paying closer attention to dataset curation and (2) reporting of accuracies in context of the total computational cost.
Hierarchical Perceiver
Feb 22, 2022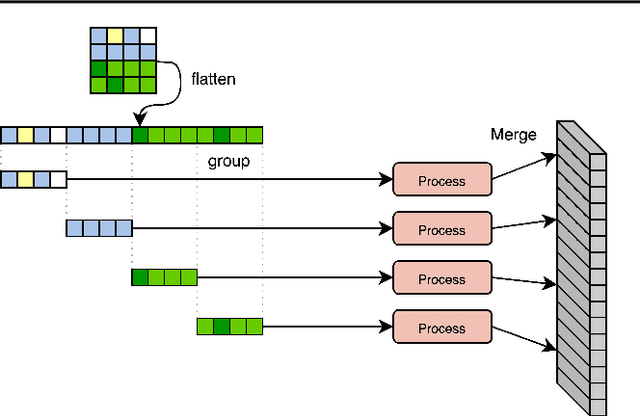

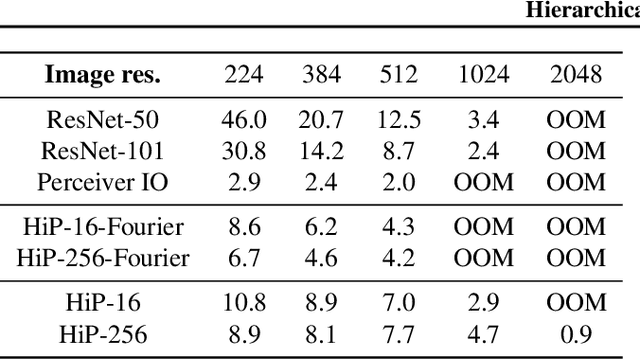

General perception systems such as Perceivers can process arbitrary modalities in any combination and are able to handle up to a few hundred thousand inputs. They achieve this generality by exclusively using global attention operations. This however hinders them from scaling up to the inputs sizes required to process raw high-resolution images or video. In this paper, we show that some degree of locality can be introduced back into these models, greatly improving their efficiency while preserving their generality. To scale them further, we introduce a self-supervised approach that enables learning dense low-dimensional positional embeddings for very large signals. We call the resulting model a Hierarchical Perceiver (HiP). HiP retains the ability to process arbitrary modalities, but now at higher-resolution and without any specialized preprocessing, improving over flat Perceivers in both efficiency and accuracy on the ImageNet, Audioset and PASCAL VOC datasets.
On the Effectiveness of Interval Bound Propagation for Training Verifiably Robust Models
Nov 05, 2018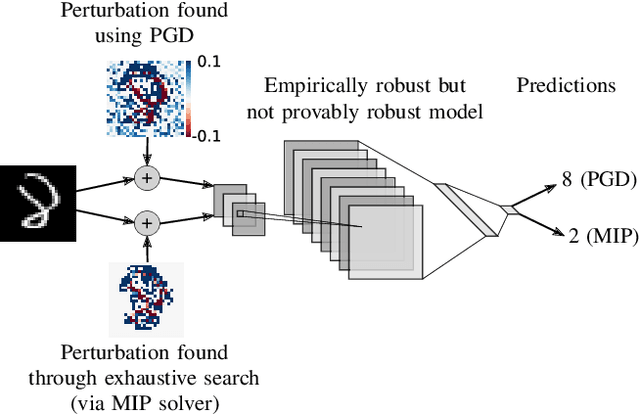

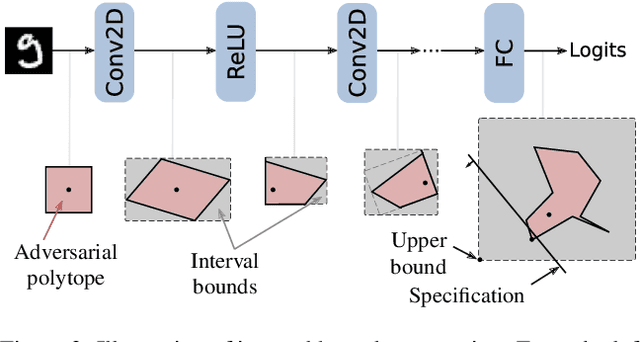

Recent works have shown that it is possible to train models that are verifiably robust to norm-bounded adversarial perturbations. While these recent methods show promise, they remain hard to scale and difficult to tune. This paper investigates how interval bound propagation (IBP) using simple interval arithmetic can be exploited to train verifiably robust neural networks that are surprisingly effective. While IBP itself has been studied in prior work, our contribution is in showing that, with an appropriate loss and careful tuning of hyper-parameters, verified training with IBP leads to a fast and stable learning algorithm. We compare our approach with recent techniques, and train classifiers that improve on the state-of-the-art in single-model adversarial robustness: we reduce the verified error rate from 3.67% to 2.23% on MNIST (with $\ell_\infty$ perturbations of $\epsilon = 0.1$), from 19.32% to 8.05% on MNIST (at $\epsilon = 0.3$), and from 78.22% to 72.91% on CIFAR-10 (at $\epsilon = 8/255$).
Training verified learners with learned verifiers
May 29, 2018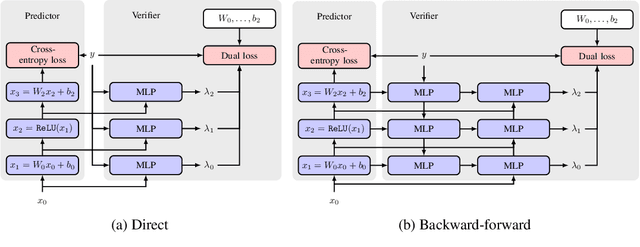
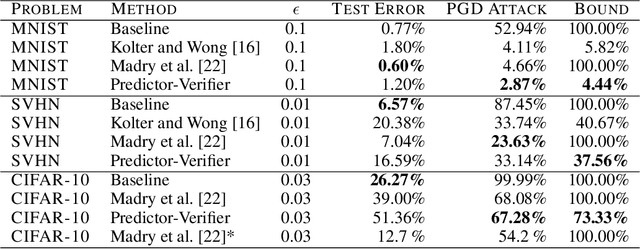
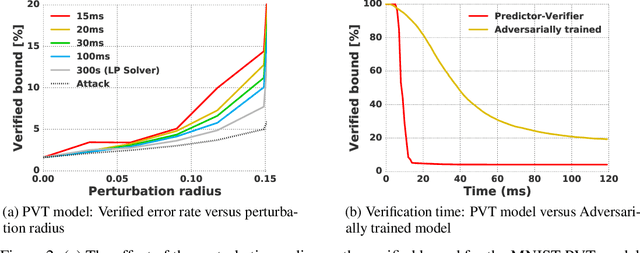
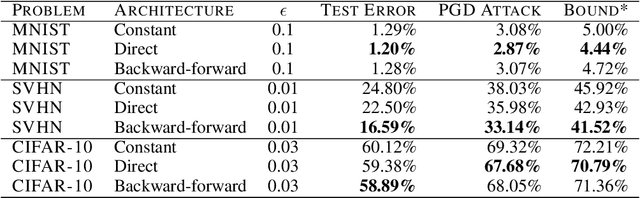
This paper proposes a new algorithmic framework, predictor-verifier training, to train neural networks that are verifiable, i.e., networks that provably satisfy some desired input-output properties. The key idea is to simultaneously train two networks: a predictor network that performs the task at hand,e.g., predicting labels given inputs, and a verifier network that computes a bound on how well the predictor satisfies the properties being verified. Both networks can be trained simultaneously to optimize a weighted combination of the standard data-fitting loss and a term that bounds the maximum violation of the property. Experiments show that not only is the predictor-verifier architecture able to train networks to achieve state of the art verified robustness to adversarial examples with much shorter training times (outperforming previous algorithms on small datasets like MNIST and SVHN), but it can also be scaled to produce the first known (to the best of our knowledge) verifiably robust networks for CIFAR-10.