 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Perceiver
Feb 22, 2022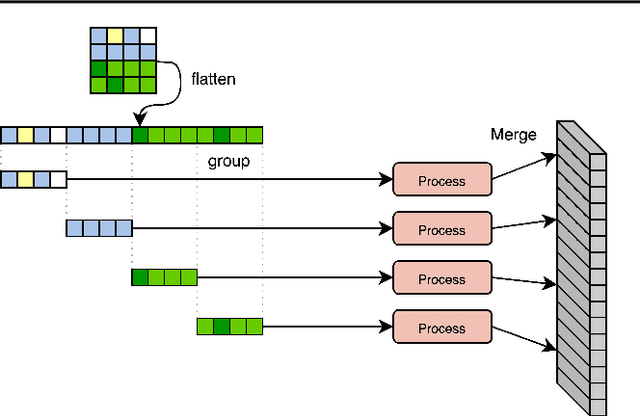

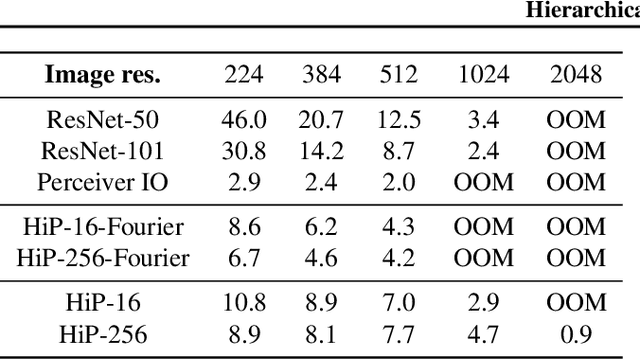

General perception systems such as Perceivers can process arbitrary modalities in any combination and are able to handle up to a few hundred thousand inputs. They achieve this generality by exclusively using global attention operations. This however hinders them from scaling up to the inputs sizes required to process raw high-resolution images or video. In this paper, we show that some degree of locality can be introduced back into these models, greatly improving their efficiency while preserving their generality. To scale them further, we introduce a self-supervised approach that enables learning dense low-dimensional positional embeddings for very large signals. We call the resulting model a Hierarchical Perceiver (HiP). HiP retains the ability to process arbitrary modalities, but now at higher-resolution and without any specialized preprocessing, improving over flat Perceivers in both efficiency and accuracy on the ImageNet, Audioset and PASCAL VOC datasets.
Towards Learning Universal Audio Representations
Dec 01, 2021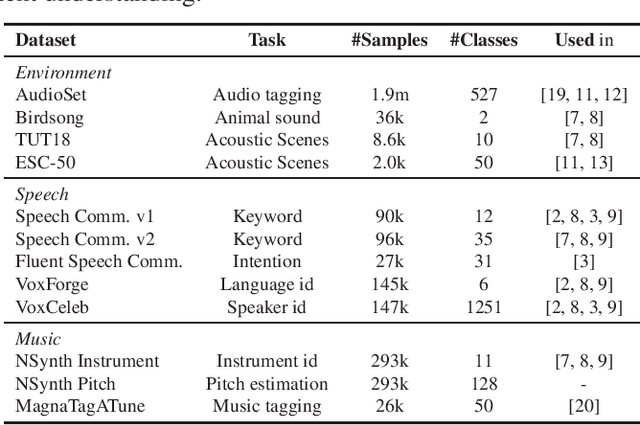
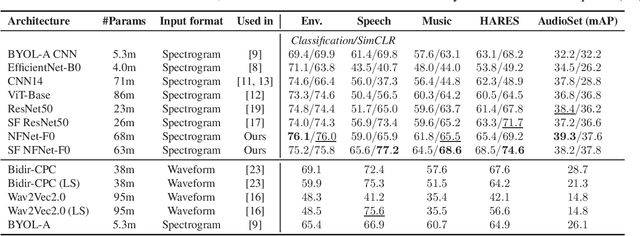
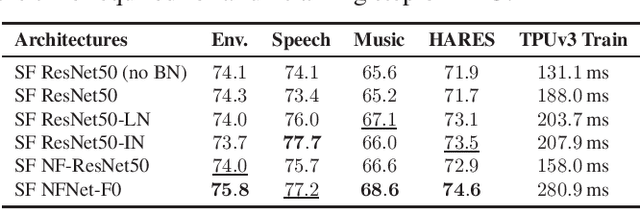
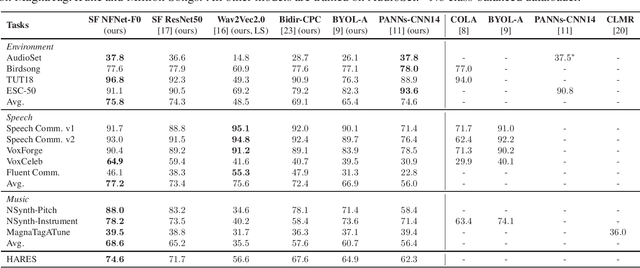
The ability to learn universal audio representations that can solve diverse speech, music, and environment tasks can spur many applications that require general sound content understanding. In this work, we introduce a holistic audio representation evaluation suite (HARES) spanning 12 downstream tasks across audio domains and provide a thorough empirical study of recent sound representation learning systems on that benchmark. We discover that previous sound event classification or speech models do not generalize outside of their domains. We observe that more robust audio representations can be learned with the SimCLR objective; however, the model's transferability depends heavily on the model architecture. We find the Slowfast architecture is good at learning rich representations required by different domains, but its performance is affected by the normalization scheme. Based on these findings, we propose a novel normalizer-free Slowfast NFNet and achieve state-of-the-art performance across all domains.
Multimodal Self-Supervised Learning of General Audio Representations
Apr 28, 2021



We present a multimodal framework to learn general audio representations from videos. Existing contrastive audio representation learning methods mainly focus on using the audio modality alone during training. In this work, we show that additional information contained in video can be utilized to greatly improve the learned features. First, we demonstrate that our contrastive framework does not require high resolution images to learn good audio features. This allows us to scale up the training batch size, while keeping the computational load incurred by the additional video modality to a reasonable level. Second, we use augmentations that mix together different samples. We show that this is effective to make the proxy task harder, which leads to substantial performance improvements when increasing the batch size. As a result, our audio model achieves a state-of-the-art of 42.4 mAP on the AudioSet classification downstream task, closing the gap between supervised and self-supervised methods trained on the same dataset. Moreover, we show that our method is advantageous on a broad range of non-semantic audio tasks, including speaker identification, keyword spotting, language identification, and music instrument classification.
A Deep Learning Approach for Characterizing Major Galaxy Mergers
Feb 09, 2021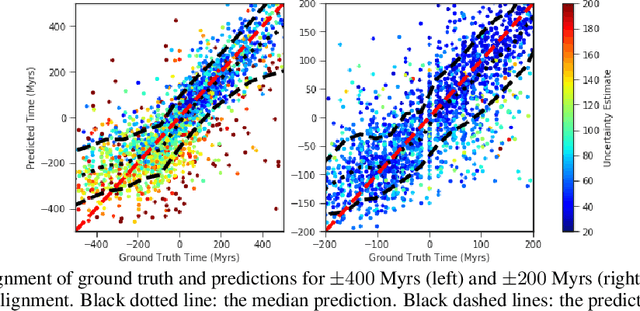

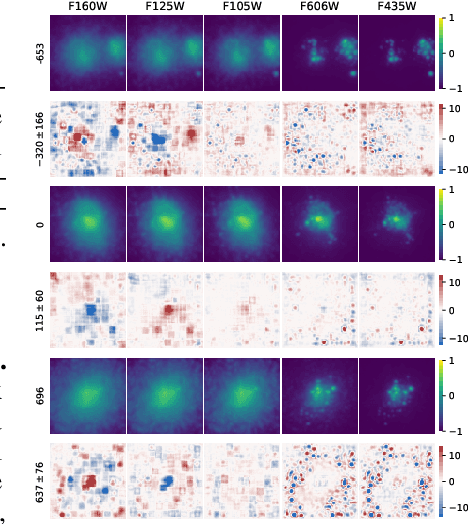
Fine-grained estimation of galaxy merger stages from observations is a key problem useful for validation of our current theoretical understanding of galaxy formation. To this end, we demonstrate a CNN-based regression model that is able to predict, for the first time, using a single image, the merger stage relative to the first perigee passage with a median error of 38.3 million years (Myrs) over a period of 400 Myrs. This model uses no specific dynamical modeling and learns only from simulated merger events. We show that our model provides reasonable estimates on real observations, approximately matching prior estimates provided by detailed dynamical modeling. We provide a preliminary interpretability analysis of our models, and demonstrate first steps toward calibrated uncertainty estimation.
Game Plan: What AI can do for Football, and What Football can do for AI
Nov 18, 2020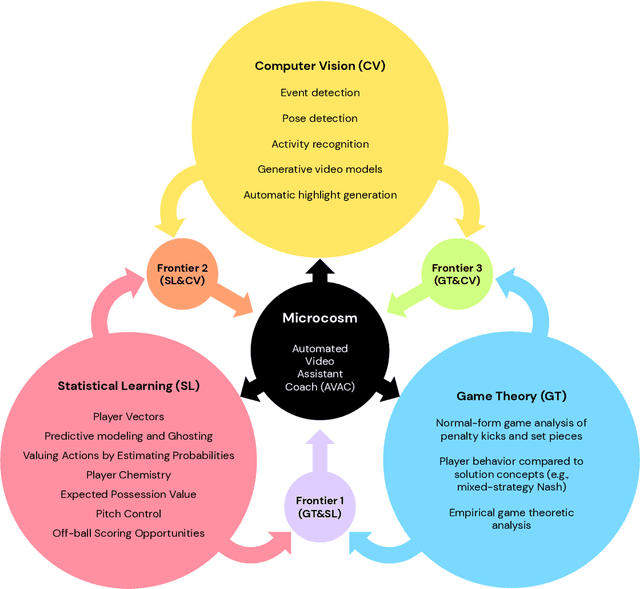



The rapid progress in artificial intelligence (AI) and machine learning has opened unprecedented analytics possibilities in various team and individual sports, including baseball, basketball, and tennis. More recently, AI techniques have been applied to football, due to a huge increase in data collection by professional teams, increased computational power, and advances in machine learning, with the goal of better addressing new scientific challenges involved in the analysis of both individual players' and coordinated teams' behaviors. The research challenges associated with predictive and prescriptive football analytics require new developments and progress at the intersection of statistical learning, game theory, and computer vision. In this paper, we provide an overarching perspective highlighting how the combination of these fields, in particular, forms a unique microcosm for AI research, while offering mutual benefits for professional teams, spectators, and broadcasters in the years to come. We illustrate that this duality makes football analytics a game changer of tremendous value, in terms of not only changing the game of football itself, but also in terms of what this domain can mean for the field of AI. We review the state-of-the-art and exemplify the types of analysis enabled by combining the aforementioned fields, including illustrative examples of counterfactual analysis using predictive models, and the combination of game-theoretic analysis of penalty kicks with statistical learning of player attributes. We conclude by highlighting envisioned downstream impacts, including possibilities for extensions to other sports (real and virtual).
Context Based Emotion Recognition using EMOTIC Dataset
Mar 30, 2020
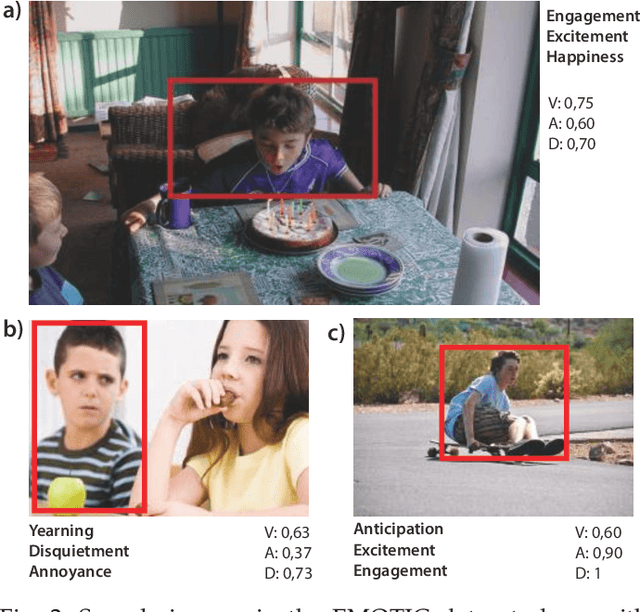


In our everyday lives and social interactions we often try to perceive the emotional states of people. There has been a lot of research in providing machines with a similar capacity of recognizing emotions. From a computer vision perspective, most of the previous efforts have been focusing in analyzing the facial expressions and, in some cases, also the body pose. Some of these methods work remarkably well in specific settings. However, their performance is limited in natural, unconstrained environments. Psychological studies show that the scene context, in addition to facial expression and body pose, provides important information to our perception of people's emotions. However, the processing of the context for automatic emotion recognition has not been explored in depth, partly due to the lack of proper data. In this paper we present EMOTIC, a dataset of images of people in a diverse set of natural situations, annotated with their apparent emotion. The EMOTIC dataset combines two different types of emotion representation: (1) a set of 26 discrete categories, and (2) the continuous dimensions Valence, Arousal, and Dominance. We also present a detailed statistical and algorithmic analysis of the dataset along with annotators' agreement analysis. Using the EMOTIC dataset we train different CNN models for emotion recognition, combining the information of the bounding box containing the person with the contextual information extracted from the scene. Our results show how scene context provides important information to automatically recognize emotional states and motivate further research in this direction. Dataset and code is open-sourced and available at: https://github.com/rkosti/emotic and link for the peer-reviewed published article: https://ieeexplore.ieee.org/document/8713881
Gaze360: Physically Unconstrained Gaze Estimation in the Wild
Oct 22, 2019
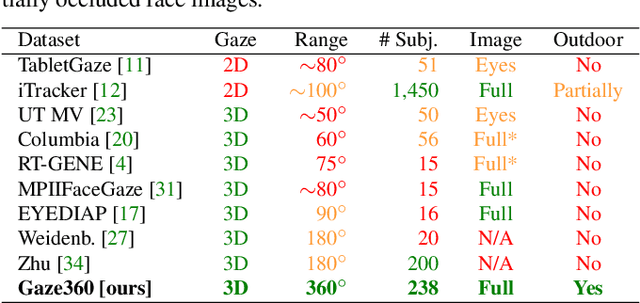

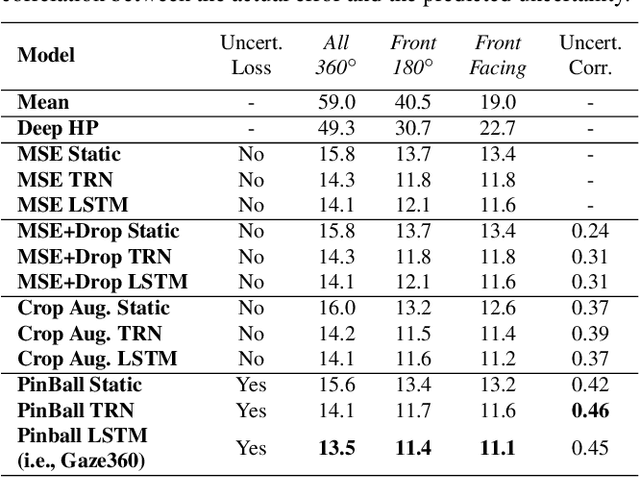
Understanding where people are looking is an informative social cue. In this work, we present Gaze360, a large-scale gaze-tracking dataset and method for robust 3D gaze estimation in unconstrained images. Our dataset consists of 238 subjects in indoor and outdoor environments with labelled 3D gaze across a wide range of head poses and distances. It is the largest publicly available dataset of its kind by both subject and variety, made possible by a simple and efficient collection method. Our proposed 3D gaze model extends existing models to include temporal information and to directly output an estimate of gaze uncertainty. We demonstrate the benefits of our model via an ablation study, and show its generalization performance via a cross-dataset evaluation against other recent gaze benchmark datasets. We furthermore propose a simple self-supervised approach to improve cross-dataset domain adaptation. Finally, we demonstrate an application of our model for estimating customer attention in a supermarket setting. Our dataset and models are available at http://gaze360.csail.mit.edu .
Understanding Infographics through Textual and Visual Tag Prediction
Sep 26, 2017



We introduce the problem of visual hashtag discovery for infographics: extracting visual elements from an infographic that are diagnostic of its topic. Given an infographic as input, our computational approach automatically outputs textual and visual elements predicted to be representative of the infographic content. Concretely, from a curated dataset of 29K large infographic images sampled across 26 categories and 391 tags, we present an automated two step approach. First, we extract the text from an infographic and use it to predict text tags indicative of the infographic content. And second, we use these predicted text tags as a supervisory signal to localize the most diagnostic visual elements from within the infographic i.e. visual hashtags. We report performances on a categorization and multi-label tag prediction problem and compare our proposed visual hashtags to human annotations.