 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARIN: Adaptive Resampling and Instance Normalization for Robust Blind Inpainting of Dunhuang Cave Paintings
Feb 25, 2024Image enhancement algorithms are very useful for real world computer vision tasks where image resolution is often physically limited by the sensor size. While state-of-the-art deep neural networks show impressive results for image enhancement, they often struggle to enhance real-world images. In this work, we tackle a real-world setting: inpainting of images from Dunhuang caves. The Dunhuang dataset consists of murals, half of which suffer from corrosion and aging. These murals feature a range of rich content, such as Buddha statues, bodhisattvas, sponsors, architecture, dance, music, and decorative patterns designed by different artists spanning ten centuries, which makes manual restoration challenging. We modify two different existing methods (CAR, HINet) that are based upon state-of-the-art (SOTA) super resolution and deblurring networks. We show that those can successfully inpaint and enhance these deteriorated cave paintings. We further show that a novel combination of CAR and HINet, resulting in our proposed inpainting network (ARIN), is very robust to external noise, especially Gaussian noise. To this end, we present a quantitative and qualitative comparison of our proposed approach with existing SOTA networks and winners of the Dunhuang challenge. One of the proposed methods HINet) represents the new state of the art and outperforms the 1st place of the Dunhuang Challenge, while our combination ARIN, which is robust to noise, is comparable to the 1st place. We also present and discuss qualitative results showing the impact of our method for inpainting on Dunhuang cave images.
ODOR: The ICPR2022 ODeuropa Challenge on Olfactory Object Recognition
Jan 24, 2023The Odeuropa Challenge on Olfactory Object Recognition aims to foster the development of object detection in the visual arts and to promote an olfactory perspective on digital heritage. Object detection in historical artworks is particularly challenging due to varying styles and artistic periods. Moreover, the task is complicated due to the particularity and historical variance of predefined target objects, which exhibit a large intra-class variance, and the long tail distribution of the dataset labels, with some objects having only very few training examples. These challenges should encourage participants to create innovative approaches using domain adaptation or few-shot learning. We provide a dataset of 2647 artworks annotated with 20 120 tightly fit bounding boxes that are split into a training and validation set (public). A test set containing 1140 artworks and 15 480 annotations is kept private for the challenge evaluation.
* 6 pages, 6 figures
ICC++: Explainable Image Retrieval for Art Historical Corpora using Image Composition Canvas
Jun 22, 2022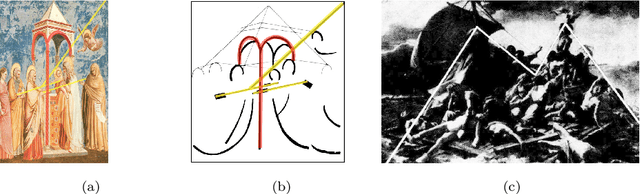
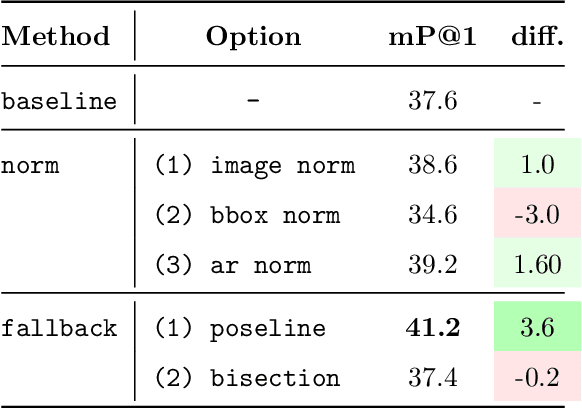
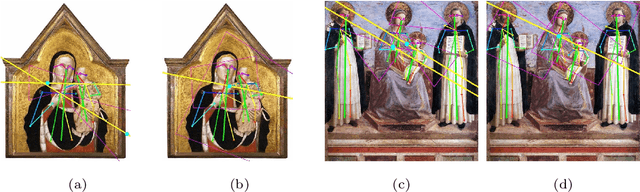
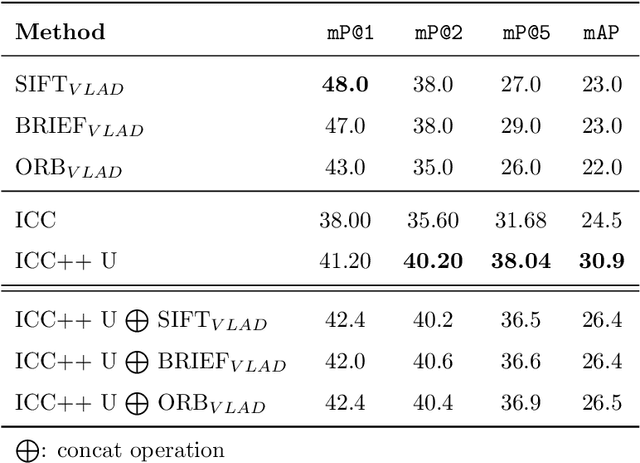
Image compositions are helpful in the study of image structures and assist in discovering the semantics of the underlying scene portrayed across art forms and styles. With the digitization of artworks in recent years, thousands of images of a particular scene or narrative could potentially be linked together. However, manually linking this data with consistent objectiveness can be a highly challenging and time-consuming task. In this work, we present a novel approach called Image Composition Canvas (ICC++) to compare and retrieve images having similar compositional elements. ICC++ is an improvement over ICC specializing in generating low and high-level features (compositional elements) motivated by Max Imdahl's work. To this end, we present a rigorous quantitative and qualitative comparison of our approach with traditional and state-of-the-art (SOTA) methods showing that our proposed method outperforms all of them. In combination with deep features, our method outperforms the best deep learning-based method, opening the research direction for explainable machine learning for digital humanities. We will release the code and the data post-publication.
ConFUDA: Contrastive Fewshot Unsupervised Domain Adaptation for Medical Image Segmentation
Jun 08, 2022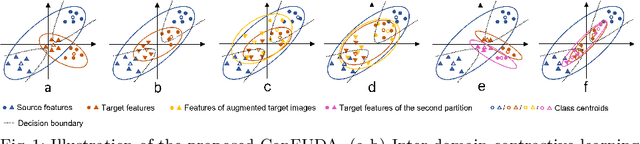
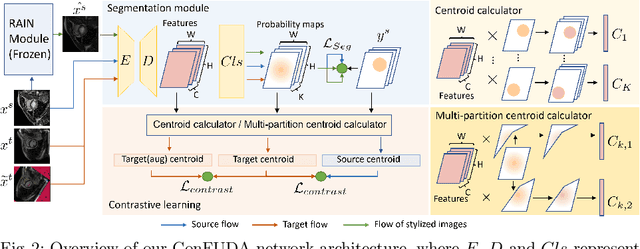

Unsupervised domain adaptation (UDA) aims to transfer knowledge learned from a labeled source domain to an unlabeled target domain. Contrastive learning (CL) in the context of UDA can help to better separate classes in feature space. However, in image segmentation, the large memory footprint due to the computation of the pixel-wise contrastive loss makes it prohibitive to use. Furthermore, labeled target data is not easily available in medical imaging, and obtaining new samples is not economical. As a result, in this work, we tackle a more challenging UDA task when there are only a few (fewshot) or a single (oneshot) image available from the target domain. We apply a style transfer module to mitigate the scarcity of target samples. Then, to align the source and target features and tackle the memory issue of the traditional contrastive loss, we propose the centroid-based contrastive learning (CCL) and a centroid norm regularizer (CNR) to optimize the contrastive pairs in both direction and magnitude. In addition, we propose multi-partition centroid contrastive learning (MPCCL) to further reduce the variance in the target features. Fewshot evaluation on MS-CMRSeg dataset demonstrates that ConFUDA improves the segmentation performance by 0.34 of the Dice score on the target domain compared with the baseline, and 0.31 Dice score improvement in a more rigorous oneshot setting.
Few-shot Unsupervised Domain Adaptation for Multi-modal Cardiac Image Segmentation
Jan 28, 2022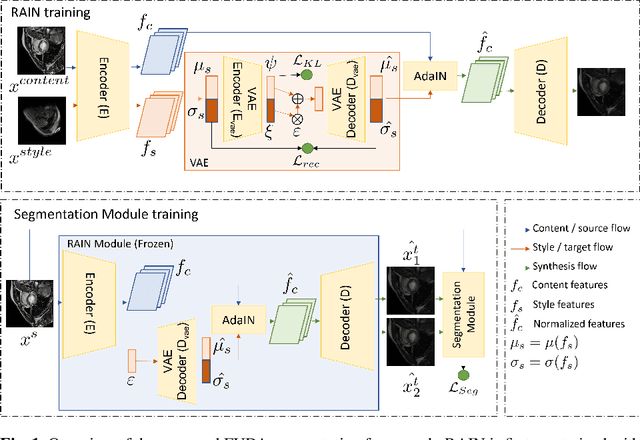

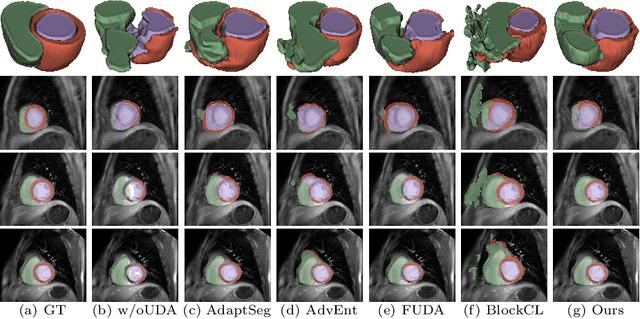
Unsupervised domain adaptation (UDA) methods intend to reduce the gap between source and target domains by using unlabeled target domain and labeled source domain data, however, in the medical domain, target domain data may not always be easily available, and acquiring new samples is generally time-consuming. This restricts the development of UDA methods for new domains. In this paper, we explore the potential of UDA in a more challenging while realistic scenario where only one unlabeled target patient sample is available. We call it Few-shot Unsupervised Domain adaptation (FUDA). We first generate target-style images from source images and explore diverse target styles from a single target patient with Random Adaptive Instance Normalization (RAIN). Then, a segmentation network is trained in a supervised manner with the generated target images. Our experiments demonstrate that FUDA improves the segmentation performance by 0.33 of Dice score on the target domain compared with the baseline, and it also gives 0.28 of Dice score improvement in a more rigorous one-shot setting. Our code is available at \url{https://github.com/MingxuanGu/Few-shot-UDA}.
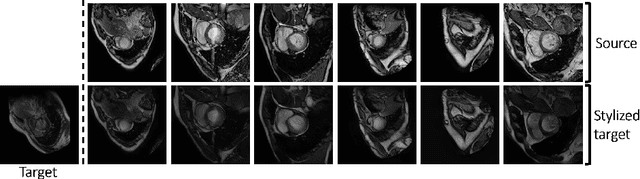
Adapt Everywhere: Unsupervised Adaptation of Point-Clouds and Entropy Minimisation for Multi-modal Cardiac Image Segmentation
Mar 15, 2021
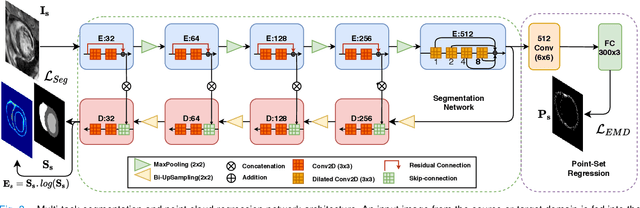
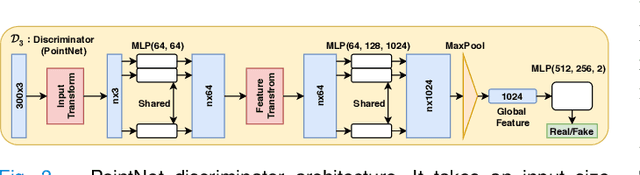
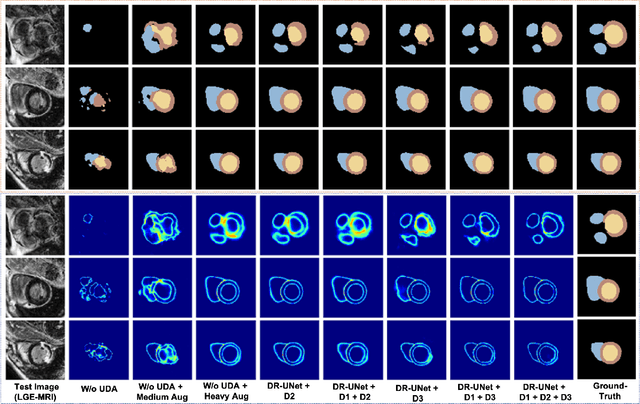
Deep learning models are sensitive to domain shift phenomena. A model trained on images from one domain cannot generalise well when tested on images from a different domain, despite capturing similar anatomical structures. It is mainly because the data distribution between the two domains is different. Moreover, creating annotation for every new modality is a tedious and time-consuming task, which also suffers from high inter- and intra- observer variability. Unsupervised domain adaptation (UDA) methods intend to reduce the gap between source and target domains by leveraging source domain labelled data to generate labels for the target domain. However, current state-of-the-art (SOTA) UDA methods demonstrate degraded performance when there is insufficient data in source and target domains. In this paper, we present a novel UDA method for multi-modal cardiac image segmentation. The proposed method is based on adversarial learning and adapts network features between source and target domain in different spaces. The paper introduces an end-to-end framework that integrates: a) entropy minimisation, b) output feature space alignment and c) a novel point-cloud shape adaptation based on the latent features learned by the segmentation model. We validated our method on two cardiac datasets by adapting from the annotated source domain, bSSFP-MRI (balanced Steady-State Free Procession-MRI), to the unannotated target domain, LGE-MRI (Late-gadolinium enhance-MRI), for the multi-sequence dataset; and from MRI (source) to CT (target) for the cross-modality dataset. The results highlighted that by enforcing adversarial learning in different parts of the network, the proposed method delivered promising performance, compared to other SOTA methods.
Enhancing Human Pose Estimation in Ancient Vase Paintings via Perceptually-grounded Style Transfer Learning
Dec 10, 2020
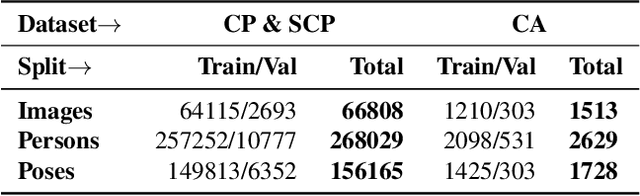

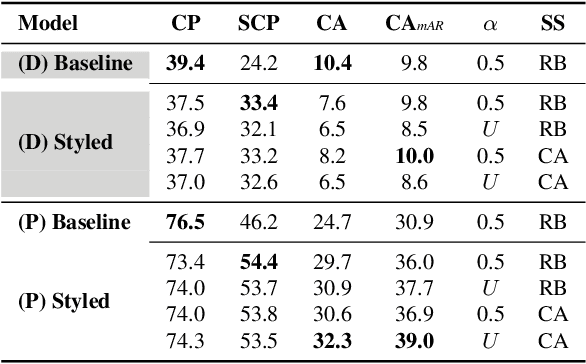
Human pose estimation (HPE) is a central part of understanding the visual narration and body movements of characters depicted in artwork collections, such as Greek vase paintings. Unfortunately, existing HPE methods do not generalise well across domains resulting in poorly recognized poses. Therefore, we propose a two step approach: (1) adapting a dataset of natural images of known person and pose annotations to the style of Greek vase paintings by means of image style-transfer. We introduce a perceptually-grounded style transfer training to enforce perceptual consistency. Then, we fine-tune the base model with this newly created dataset. We show that using style-transfer learning significantly improves the SOTA performance on unlabelled data by more than 6% mean average precision (mAP) as well as mean average recall (mAR). (2) To improve the already strong results further, we created a small dataset (ClassArch) consisting of ancient Greek vase paintings from the 6-5th century BCE with person and pose annotations. We show that fine-tuning on this data with a style-transferred model improves the performance further. In a thorough ablation study, we give a targeted analysis of the influence of style intensities, revealing that the model learns generic domain styles. Additionally, we provide a pose-based image retrieval to demonstrate the effectiveness of our method.
Understanding Compositional Structures in Art Historical Images using Pose and Gaze Priors
Sep 08, 2020



Image compositions as a tool for analysis of artworks is of extreme significance for art historians. These compositions are useful in analyzing the interactions in an image to study artists and their artworks. Max Imdahl in his work called Ikonik, along with other prominent art historians of the 20th century, underlined the aesthetic and semantic importance of the structural composition of an image. Understanding underlying compositional structures within images is challenging and a time consuming task. Generating these structures automatically using computer vision techniques (1) can help art historians towards their sophisticated analysis by saving lot of time; providing an overview and access to huge image repositories and (2) also provide an important step towards an understanding of man made imagery by machines. In this work, we attempt to automate this process using the existing state of the art machine learning techniques, without involving any form of training. Our approach, inspired by Max Imdahl's pioneering work, focuses on two central themes of image composition: (a) detection of action regions and action lines of the artwork; and (b) pose-based segmentation of foreground and background. Currently, our approach works for artworks comprising of protagonists (persons) in an image. In order to validate our approach qualitatively and quantitatively, we conduct a user study involving experts and non-experts. The outcome of the study highly correlates with our approach and also demonstrates its domain-agnostic capability. We have open-sourced the code at https://github.com/image-compostion-canvas-group/image-compostion-canvas.
Recognizing Characters in Art History Using Deep Learning
Apr 01, 2020

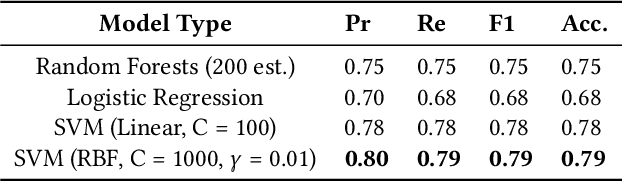

In the field of Art History, images of artworks and their contexts are core to understanding the underlying semantic information. However, the highly complex and sophisticated representation of these artworks makes it difficult, even for the experts, to analyze the scene. From the computer vision perspective, the task of analyzing such artworks can be divided into sub-problems by taking a bottom-up approach. In this paper, we focus on the problem of recognizing the characters in Art History. From the iconography of $Annunciation$ $of$ $the$ $Lord$ (Figure 1), we consider the representation of the main protagonists, $Mary$ and $Gabriel$, across different artworks and styles. We investigate and present the findings of training a character classifier on features extracted from their face images. The limitations of this method, and the inherent ambiguity in the representation of $Gabriel$, motivated us to consider their bodies (a bigger context) to analyze in order to recognize the characters. Convolutional Neural Networks (CNN) trained on the bodies of $Mary$ and $Gabriel$ are able to learn person related features and ultimately improve the performance of character recognition. We introduce a new technique that generates more data with similar styles, effectively creating data in the similar domain. We present experiments and analysis on three different models and show that the model trained on domain related data gives the best performance for recognizing character. Additionally, we analyze the localized image regions for the network predictions. Code is open-sourced and available at https://github.com/prathmeshrmadhu/recognize_characters_art_history and the link to the published peer-reviewed article is https://dl.acm.org/citation.cfm?id=3357242.
Context Based Emotion Recognition using EMOTIC Dataset
Mar 30, 2020
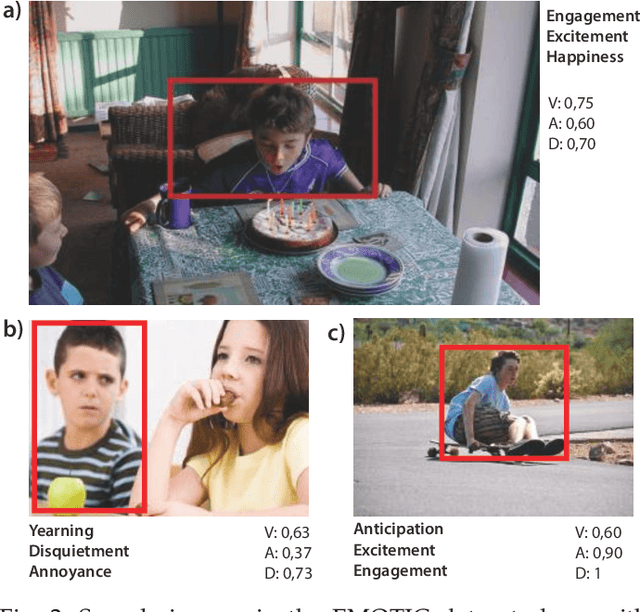


In our everyday lives and social interactions we often try to perceive the emotional states of people. There has been a lot of research in providing machines with a similar capacity of recognizing emotions. From a computer vision perspective, most of the previous efforts have been focusing in analyzing the facial expressions and, in some cases, also the body pose. Some of these methods work remarkably well in specific settings. However, their performance is limited in natural, unconstrained environments. Psychological studies show that the scene context, in addition to facial expression and body pose, provides important information to our perception of people's emotions. However, the processing of the context for automatic emotion recognition has not been explored in depth, partly due to the lack of proper data. In this paper we present EMOTIC, a dataset of images of people in a diverse set of natural situations, annotated with their apparent emotion. The EMOTIC dataset combines two different types of emotion representation: (1) a set of 26 discrete categories, and (2) the continuous dimensions Valence, Arousal, and Dominance. We also present a detailed statistical and algorithmic analysis of the dataset along with annotators' agreement analysis. Using the EMOTIC dataset we train different CNN models for emotion recognition, combining the information of the bounding box containing the person with the contextual information extracted from the scene. Our results show how scene context provides important information to automatically recognize emotional states and motivate further research in this direction. Dataset and code is open-sourced and available at: https://github.com/rkosti/emotic and link for the peer-reviewed published article: https://ieeexplore.ieee.org/document/8713881