 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew Shot Learning for the Classification of Confocal Laser Endomicroscopy Images of Head and Neck Tumors
Nov 13, 2023


The surgical removal of head and neck tumors requires safe margins, which are usually confirmed intraoperatively by means of frozen sections. This method is, in itself, an oversampling procedure, which has a relatively low sensitivity compared to the definitive tissue analysis on paraffin-embedded sections. Confocal laser endomicroscopy (CLE) is an in-vivo imaging technique that has shown its potential in the live optical biopsy of tissue. An automated analysis of this notoriously difficult to interpret modality would help surgeons. However, the images of CLE show a wide variability of patterns, caused both by individual factors but also, and most strongly, by the anatomical structures of the imaged tissue, making it a challenging pattern recognition task. In this work, we evaluate four popular few shot learning (FSL) methods towards their capability of generalizing to unseen anatomical domains in CLE images. We evaluate this on images of sinunasal tumors (SNT) from five patients and on images of the vocal folds (VF) from 11 patients using a cross-validation scheme. The best respective approach reached a median accuracy of 79.6% on the rather homogeneous VF dataset, but only of 61.6% for the highly diverse SNT dataset. Our results indicate that FSL on CLE images is viable, but strongly affected by the number of patients, as well as the diversity of anatomical patterns.
ConFUDA: Contrastive Fewshot Unsupervised Domain Adaptation for Medical Image Segmentation
Jun 08, 2022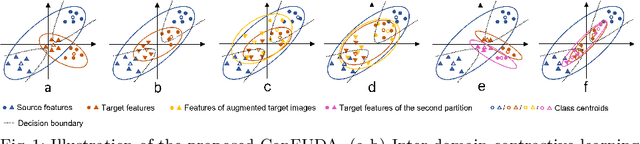
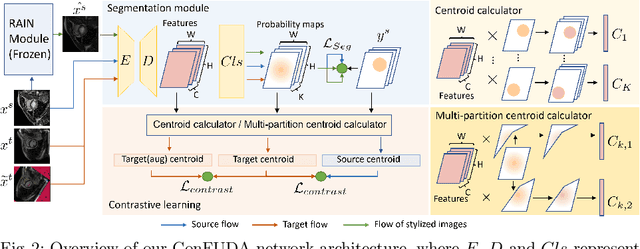

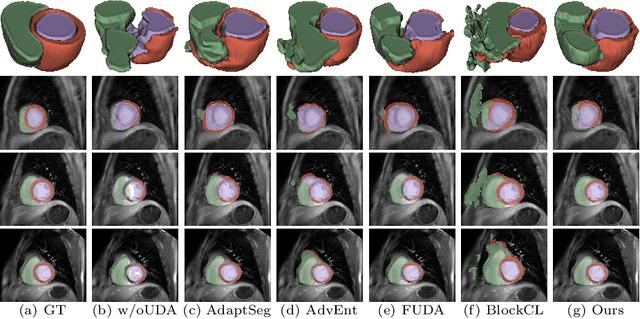
Unsupervised domain adaptation (UDA) aims to transfer knowledge learned from a labeled source domain to an unlabeled target domain. Contrastive learning (CL) in the context of UDA can help to better separate classes in feature space. However, in image segmentation, the large memory footprint due to the computation of the pixel-wise contrastive loss makes it prohibitive to use. Furthermore, labeled target data is not easily available in medical imaging, and obtaining new samples is not economical. As a result, in this work, we tackle a more challenging UDA task when there are only a few (fewshot) or a single (oneshot) image available from the target domain. We apply a style transfer module to mitigate the scarcity of target samples. Then, to align the source and target features and tackle the memory issue of the traditional contrastive loss, we propose the centroid-based contrastive learning (CCL) and a centroid norm regularizer (CNR) to optimize the contrastive pairs in both direction and magnitude. In addition, we propose multi-partition centroid contrastive learning (MPCCL) to further reduce the variance in the target features. Fewshot evaluation on MS-CMRSeg dataset demonstrates that ConFUDA improves the segmentation performance by 0.34 of the Dice score on the target domain compared with the baseline, and 0.31 Dice score improvement in a more rigorous oneshot setting.
What Do We Really Need? Degenerating U-Net on Retinal Vessel Segmentation
Nov 06, 2019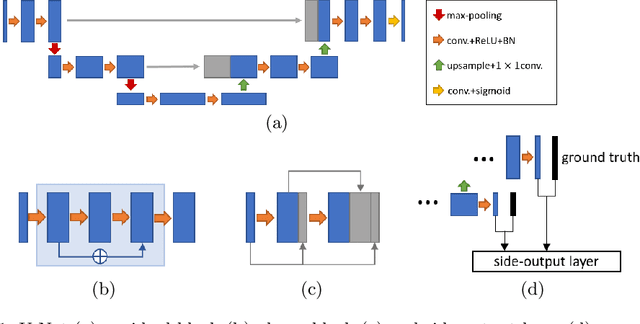
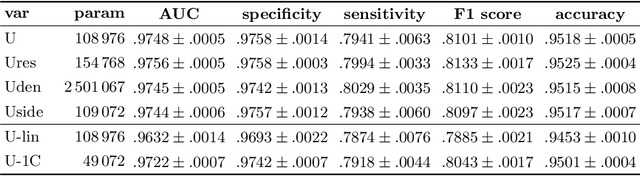

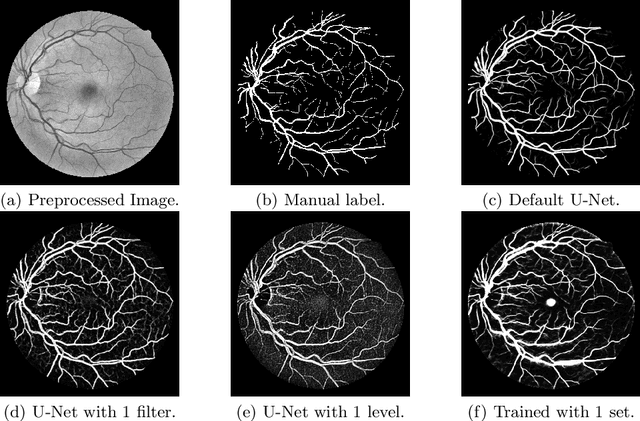
Retinal vessel segmentation is an essential step for fundus image analysis. With the recent advances of deep learning technologies, many convolutional neural networks have been applied in this field, including the successful U-Net. In this work, we firstly modify the U-Net with functional blocks aiming to pursue higher performance. The absence of the expected performance boost then lead us to dig into the opposite direction of shrinking the U-Net and exploring the extreme conditions such that its segmentation performance is maintained. Experiment series to simplify the network structure, reduce the network size and restrict the training conditions are designed. Results show that for retinal vessel segmentation on DRIVE database, U-Net does not degenerate until surprisingly acute conditions: one level, one filter in convolutional layers, and one training sample. This experimental discovery is both counter-intuitive and worthwhile. Not only are the extremes of the U-Net explored on a well-studied application, but also one intriguing warning is raised for the research methodology which seeks for marginal performance enhancement regardless of the resource cost.