 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Wavelet-Sparse FDK for 3D Cone-Beam CT Reconstruction
May 19, 2025Cone-Beam Computed Tomography (CBCT) is essential in medical imaging, and the Feldkamp-Davis-Kress (FDK) algorithm is a popular choice for reconstruction due to its efficiency. However, FDK is susceptible to noise and artifacts. While recent deep learning methods offer improved image quality, they often increase computational complexity and lack the interpretability of traditional methods. In this paper, we introduce an enhanced FDK-based neural network that maintains the classical algorithm's interpretability by selectively integrating trainable elements into the cosine weighting and filtering stages. Recognizing the challenge of a large parameter space inherent in 3D CBCT data, we leverage wavelet transformations to create sparse representations of the cosine weights and filters. This strategic sparsification reduces the parameter count by $93.75\%$ without compromising performance, accelerates convergence, and importantly, maintains the inference computational cost equivalent to the classical FDK algorithm. Our method not only ensures volumetric consistency and boosts robustness to noise, but is also designed for straightforward integration into existing CT reconstruction pipelines. This presents a pragmatic enhancement that can benefit clinical applications, particularly in environments with computational limitations.
Filter2Noise: Interpretable Self-Supervised Single-Image Denoising for Low-Dose CT with Attention-Guided Bilateral Filtering
Apr 18, 2025Effective denoising is crucial in low-dose CT to enhance subtle structures and low-contrast lesions while preventing diagnostic errors. Supervised methods struggle with limited paired datasets, and self-supervised approaches often require multiple noisy images and rely on deep networks like U-Net, offering little insight into the denoising mechanism. To address these challenges, we propose an interpretable self-supervised single-image denoising framework -- Filter2Noise (F2N). Our approach introduces an Attention-Guided Bilateral Filter that adapted to each noisy input through a lightweight module that predicts spatially varying filter parameters, which can be visualized and adjusted post-training for user-controlled denoising in specific regions of interest. To enable single-image training, we introduce a novel downsampling shuffle strategy with a new self-supervised loss function that extends the concept of Noise2Noise to a single image and addresses spatially correlated noise. On the Mayo Clinic 2016 low-dose CT dataset, F2N outperforms the leading self-supervised single-image method (ZS-N2N) by 4.59 dB PSNR while improving transparency, user control, and parametric efficiency. These features provide key advantages for medical applications that require precise and interpretable noise reduction. Our code is demonstrated at https://github.com/sypsyp97/Filter2Noise.git .
CyclePose -- Leveraging Cycle-Consistency for Annotation-Free Nuclei Segmentation in Fluorescence Microscopy
Mar 14, 2025In recent years, numerous neural network architectures specifically designed for the instance segmentation of nuclei in microscopic images have been released. These models embed nuclei-specific priors to outperform generic architectures like U-Nets; however, they require large annotated datasets, which are often not available. Generative models (GANs, diffusion models) have been used to compensate for this by synthesizing training data. These two-stage approaches are computationally expensive, as first a generative model and then a segmentation model has to be trained. We propose CyclePose, a hybrid framework integrating synthetic data generation and segmentation training. CyclePose builds on a CycleGAN architecture, which allows unpaired translation between microscopy images and segmentation masks. We embed a segmentation model into CycleGAN and leverage a cycle consistency loss for self-supervision. Without annotated data, CyclePose outperforms other weakly or unsupervised methods on two public datasets. Code is available at https://github.com/jonasutz/CyclePose
On the Influence of Smoothness Constraints in Computed Tomography Motion Compensation
May 29, 2024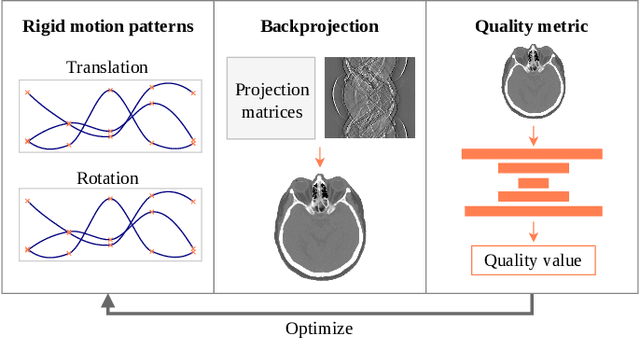
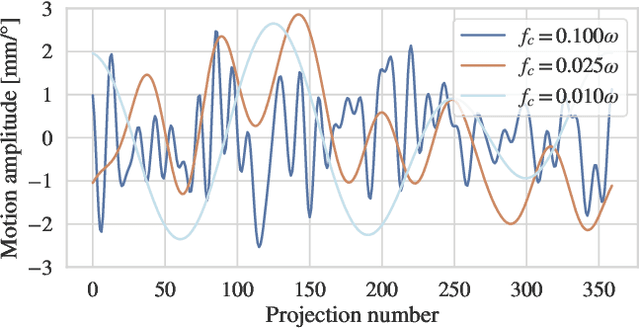
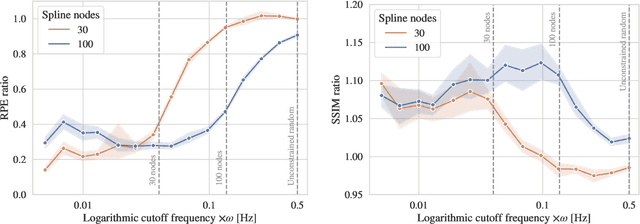
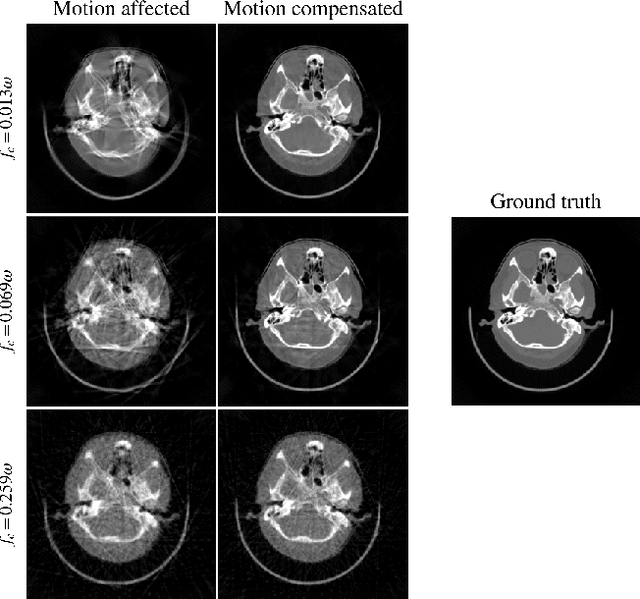
Computed tomography (CT) relies on precise patient immobilization during image acquisition. Nevertheless, motion artifacts in the reconstructed images can persist. Motion compensation methods aim to correct such artifacts post-acquisition, often incorporating temporal smoothness constraints on the estimated motion patterns. This study analyzes the influence of a spline-based motion model within an existing rigid motion compensation algorithm for cone-beam CT on the recoverable motion frequencies. Results demonstrate that the choice of motion model crucially influences recoverable frequencies. The optimization-based motion compensation algorithm is able to accurately fit the spline nodes for frequencies almost up to the node-dependent theoretical limit according to the Nyquist-Shannon theorem. Notably, a higher node count does not compromise reconstruction performance for slow motion patterns, but can extend the range of recoverable high frequencies for the investigated algorithm. Eventually, the optimal motion model is dependent on the imaged anatomy, clinical use case, and scanning protocol and should be tailored carefully to the expected motion frequency spectrum to ensure accurate motion compensation.
Reference-Free Multi-Modality Volume Registration of X-Ray Microscopy and Light-Sheet Fluorescence Microscopy
Apr 23, 2024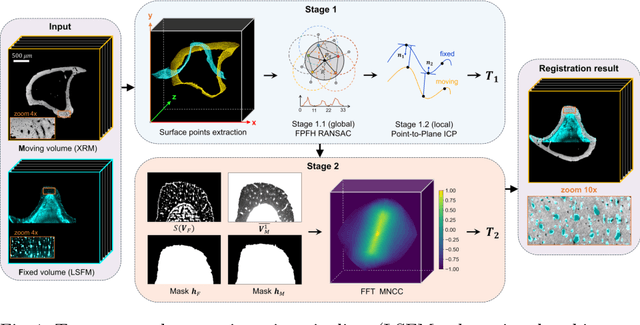
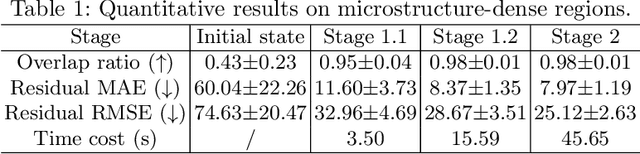
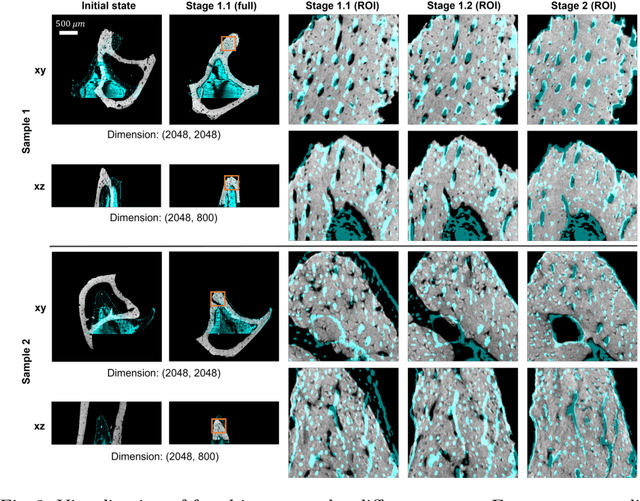
Recently, X-ray microscopy (XRM) and light-sheet fluorescence microscopy (LSFM) have emerged as two pivotal imaging tools in preclinical research on bone remodeling diseases, offering micrometer-level resolution. Integrating these complementary modalities provides a holistic view of bone microstructures, facilitating function-oriented volume analysis across different disease cycles. However, registering such independently acquired large-scale volumes is extremely challenging under real and reference-free scenarios. This paper presents a fast two-stage pipeline for volume registration of XRM and LSFM. The first stage extracts the surface features and employs two successive point cloud-based methods for coarse alignment. The second stage fine-tunes the initial alignment using a modified cross-correlation method, ensuring precise volumetric registration. Moreover, we propose residual similarity as a novel metric to assess the alignment of two complementary modalities. The results imply robust gradual improvement across the stages. In the end, all correlating microstructures, particularly lacunae in XRM and bone cells in LSFM, are precisely matched, enabling new insights into bone diseases like osteoporosis which are a substantial burden in aging societies.
Differentiable Score-Based Likelihoods: Learning CT Motion Compensation From Clean Images
Apr 23, 2024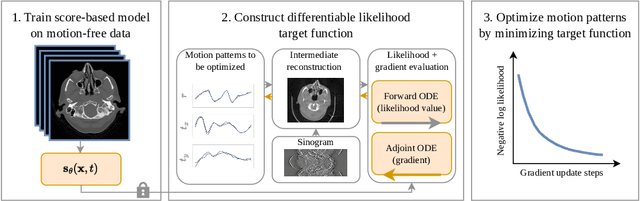
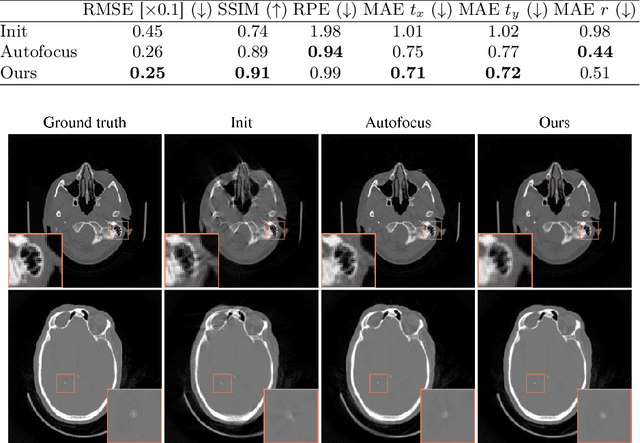
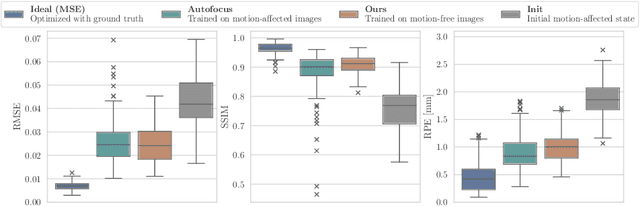
Motion artifacts can compromise the diagnostic value of computed tomography (CT) images. Motion correction approaches require a per-scan estimation of patient-specific motion patterns. In this work, we train a score-based model to act as a probability density estimator for clean head CT images. Given the trained model, we quantify the deviation of a given motion-affected CT image from the ideal distribution through likelihood computation. We demonstrate that the likelihood can be utilized as a surrogate metric for motion artifact severity in the CT image facilitating the application of an iterative, gradient-based motion compensation algorithm. By optimizing the underlying motion parameters to maximize likelihood, our method effectively reduces motion artifacts, bringing the image closer to the distribution of motion-free scans. Our approach achieves comparable performance to state-of-the-art methods while eliminating the need for a representative data set of motion-affected samples. This is particularly advantageous in real-world applications, where patient motion patterns may exhibit unforeseen variability, ensuring robustness without implicit assumptions about recoverable motion types.
Segmentation-Guided Knee Radiograph Generation using Conditional Diffusion Models
Apr 04, 2024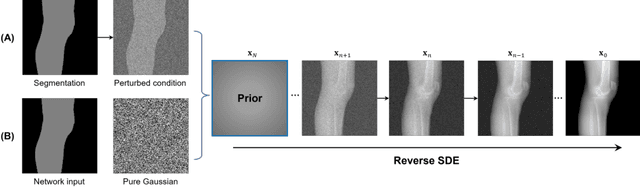
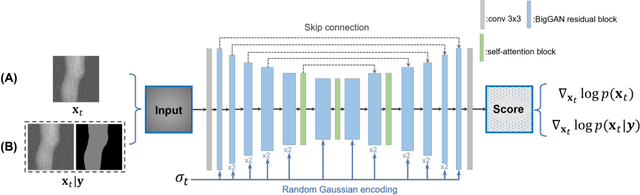
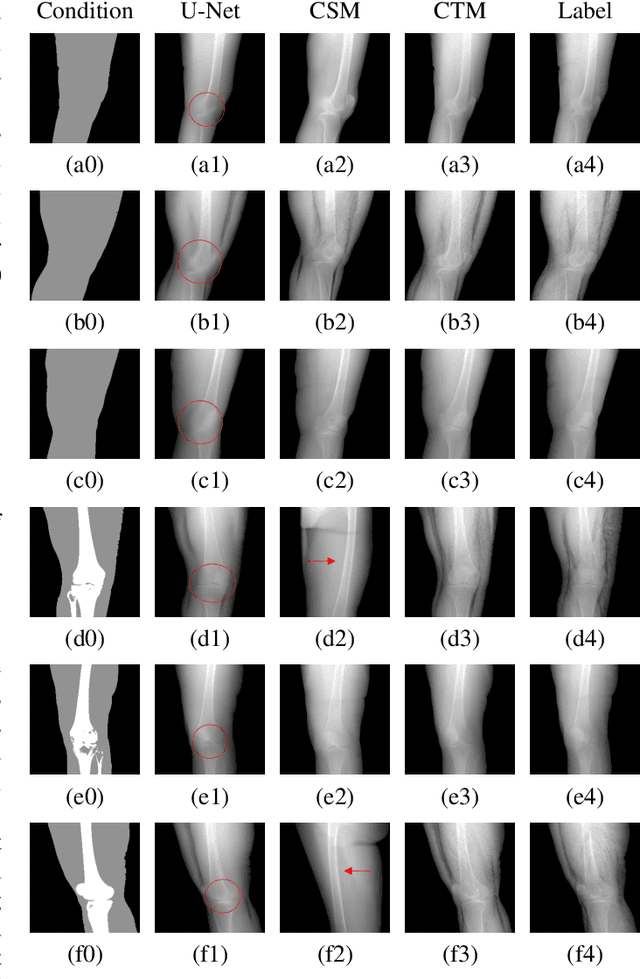
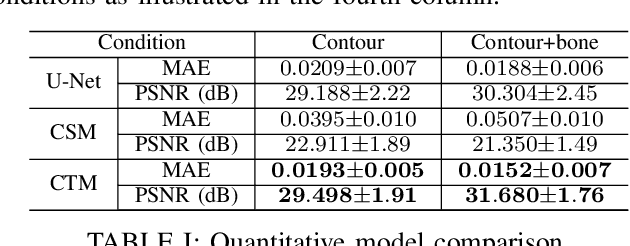
Deep learning-based medical image processing algorithms require representative data during development. In particular, surgical data might be difficult to obtain, and high-quality public datasets are limited. To overcome this limitation and augment datasets, a widely adopted solution is the generation of synthetic images. In this work, we employ conditional diffusion models to generate knee radiographs from contour and bone segmentations. Remarkably, two distinct strategies are presented by incorporating the segmentation as a condition into the sampling and training process, namely, conditional sampling and conditional training. The results demonstrate that both methods can generate realistic images while adhering to the conditioning segmentation. The conditional training method outperforms the conditional sampling method and the conventional U-Net.
EAGLE: An Edge-Aware Gradient Localization Enhanced Loss for CT Image Reconstruction
Mar 15, 2024Computed Tomography (CT) image reconstruction is crucial for accurate diagnosis and deep learning approaches have demonstrated significant potential in improving reconstruction quality. However, the choice of loss function profoundly affects the reconstructed images. Traditional mean squared error loss often produces blurry images lacking fine details, while alternatives designed to improve may introduce structural artifacts or other undesirable effects. To address these limitations, we propose Eagle-Loss, a novel loss function designed to enhance the visual quality of CT image reconstructions. Eagle-Loss applies spectral analysis of localized features within gradient changes to enhance sharpness and well-defined edges. We evaluated Eagle-Loss on two public datasets across low-dose CT reconstruction and CT field-of-view extension tasks. Our results show that Eagle-Loss consistently improves the visual quality of reconstructed images, surpassing state-of-the-art methods across various network architectures. Code and data are available at \url{https://github.com/sypsyp97/Eagle_Loss}.
Data-Driven Filter Design in FBP: Transforming CT Reconstruction with Trainable Fourier Series
Jan 29, 2024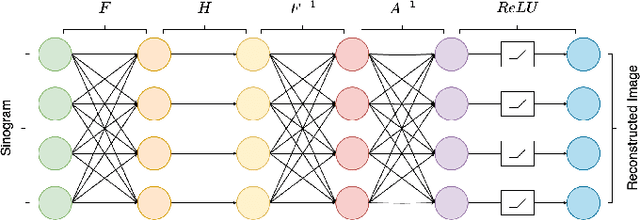
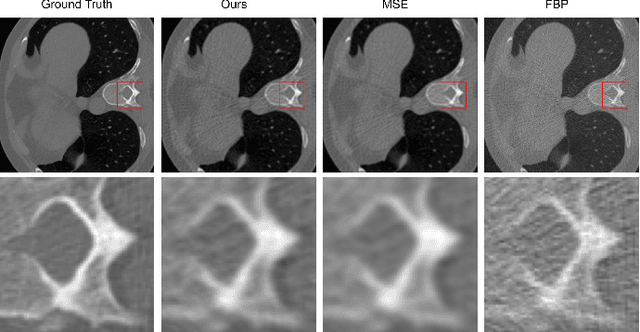
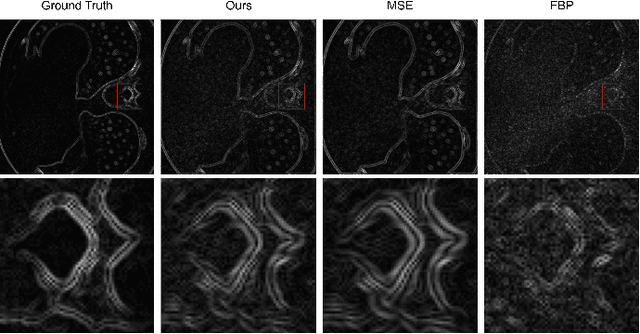
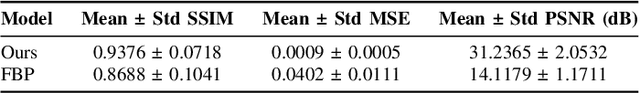
In this study, we introduce a Fourier series-based trainable filter for computed tomography (CT) reconstruction within the filtered backprojection (FBP) framework. This method overcomes the limitation in noise reduction, inherent in conventional FBP methods, by optimizing Fourier series coefficients to construct the filter. This method enables robust performance across different resolution scales and maintains computational efficiency with minimal increment for the trainable parameters compared to other deep learning frameworks. Additionally, we propose Gaussian edge-enhanced (GEE) loss function that prioritizes the $L_1$ norm of high-frequency magnitudes, effectively countering the blurring problems prevalent in mean squared error (MSE) approaches. The model's foundation in the FBP algorithm ensures excellent interpretability, as it relies on a data-driven filter with all other parameters derived through rigorous mathematical procedures. Designed as a plug-and-play solution, our Fourier series-based filter can be easily integrated into existing CT reconstruction models, making it a versatile tool for a wide range of practical applications. Our research presents a robust and scalable method that expands the utility of FBP in both medical and scientific imaging.
A gradient-based approach to fast and accurate head motion compensation in cone-beam CT
Jan 17, 2024Cone-beam computed tomography (CBCT) systems, with their portability, present a promising avenue for direct point-of-care medical imaging, particularly in critical scenarios such as acute stroke assessment. However, the integration of CBCT into clinical workflows faces challenges, primarily linked to long scan duration resulting in patient motion during scanning and leading to image quality degradation in the reconstructed volumes. This paper introduces a novel approach to CBCT motion estimation using a gradient-based optimization algorithm, which leverages generalized derivatives of the backprojection operator for cone-beam CT geometries. Building on that, a fully differentiable target function is formulated which grades the quality of the current motion estimate in reconstruction space. We drastically accelerate motion estimation yielding a 19-fold speed-up compared to existing methods. Additionally, we investigate the architecture of networks used for quality metric regression and propose predicting voxel-wise quality maps, favoring autoencoder-like architectures over contracting ones. This modification improves gradient flow, leading to more accurate motion estimation. The presented method is evaluated through realistic experiments on head anatomy. It achieves a reduction in reprojection error from an initial average of 3mm to 0.61mm after motion compensation and consistently demonstrates superior performance compared to existing approaches. The analytic Jacobian for the backprojection operation, which is at the core of the proposed method, is made publicly available. In summary, this paper contributes to the advancement of CBCT integration into clinical workflows by proposing a robust motion estimation approach that enhances efficiency and accuracy, addressing critical challenges in time-sensitive scenarios.