 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCut to the Mix: Simple Data Augmentation Outperforms Elaborate Ones in Limited Organ Segmentation Datasets
Feb 03, 2026Multi-organ segmentation is a widely applied clinical routine and automated organ segmentation tools dramatically improve the pipeline of the radiologists. Recently, deep learning (DL) based segmentation models have shown the capacity to accomplish such a task. However, the training of the segmentation networks requires large amount of data with manual annotations, which is a major concern due to the data scarcity from clinic. Working with limited data is still common for researches on novel imaging modalities. To enhance the effectiveness of DL models trained with limited data, data augmentation (DA) is a crucial regularization technique. Traditional DA (TDA) strategies focus on basic intra-image operations, i.e. generating images with different orientations and intensity distributions. In contrast, the interimage and object-level DA operations are able to create new images from separate individuals. However, such DA strategies are not well explored on the task of multi-organ segmentation. In this paper, we investigated four possible inter-image DA strategies: CutMix, CarveMix, ObjectAug and AnatoMix, on two organ segmentation datasets. The result shows that CutMix, CarveMix and AnatoMix can improve the average dice score by 4.9, 2.0 and 1.9, compared with the state-of-the-art nnUNet without DA strategies. These results can be further improved by adding TDA strategies. It is revealed in our experiments that Cut-Mix is a robust but simple DA strategy to drive up the segmentation performance for multi-organ segmentation, even when CutMix produces intuitively 'wrong' images. Our implementation is publicly available for future benchmarks.
GANeXt: A Fully ConvNeXt-Enhanced Generative Adversarial Network for MRI- and CBCT-to-CT Synthesis
Dec 22, 2025The synthesis of computed tomography (CT) from magnetic resonance imaging (MRI) and cone-beam CT (CBCT) plays a critical role in clinical treatment planning by enabling accurate anatomical representation in adaptive radiotherapy. In this work, we propose GANeXt, a 3D patch-based, fully ConvNeXt-powered generative adversarial network for unified CT synthesis across different modalities and anatomical regions. Specifically, GANeXt employs an efficient U-shaped generator constructed from stacked 3D ConvNeXt blocks with compact convolution kernels, while the discriminator adopts a conditional PatchGAN. To improve synthesis quality, we incorporate a combination of loss functions, including mean absolute error (MAE), perceptual loss, segmentation-based masked MAE, and adversarial loss and a combination of Dice loss and cross-entropy for multi-head segmentation discriminator. For both tasks, training is performed with a batch size of 8 using two separate AdamW optimizers for the generator and discriminator, each equipped with a warmup and cosine decay scheduler, with learning rates of $5\times10^{-4}$ and $1\times10^{-3}$, respectively. Data preprocessing includes deformable registration, foreground cropping, percentile normalization for the input modality, and linear normalization of the CT to the range $[-1024, 1000]$. Data augmentation involves random zooming within $(0.8, 1.3)$ (for MRI-to-CT only), fixed-size cropping to $32\times160\times192$ for MRI-to-CT and $32\times128\times128$ for CBCT-to-CT, and random flipping. During inference, we apply a sliding-window approach with $0.8$ overlap and average folding to reconstruct the full-size sCT, followed by inversion of the CT normalization. After joint training on all regions without any fine-tuning, the final models are selected at the end of 3000 epochs for MRI-to-CT and 1000 epochs for CBCT-to-CT using the full training dataset.
Novel-view X-ray Projection Synthesis through Geometry-Integrated Deep Learning
Apr 16, 2025X-ray imaging plays a crucial role in the medical field, providing essential insights into the internal anatomy of patients for diagnostics, image-guided procedures, and clinical decision-making. Traditional techniques often require multiple X-ray projections from various angles to obtain a comprehensive view, leading to increased radiation exposure and more complex clinical processes. This paper explores an innovative approach using the DL-GIPS model, which synthesizes X-ray projections from new viewpoints by leveraging a single existing projection. The model strategically manipulates geometry and texture features extracted from an initial projection to match new viewing angles. It then synthesizes the final projection by merging these modified geometry features with consistent texture information through an advanced image generation process. We demonstrate the effectiveness and broad applicability of the DL-GIPS framework through lung imaging examples, highlighting its potential to revolutionize stereoscopic and volumetric imaging by minimizing the need for extensive data acquisition.
A Category-Fragment Segmentation Framework for Pelvic Fracture Segmentation in X-ray Images
Apr 16, 2025Pelvic fractures, often caused by high-impact trauma, frequently require surgical intervention. Imaging techniques such as CT and 2D X-ray imaging are used to transfer the surgical plan to the operating room through image registration, enabling quick intraoperative adjustments. Specifically, segmenting pelvic fractures from 2D X-ray imaging can assist in accurately positioning bone fragments and guiding the placement of screws or metal plates. In this study, we propose a novel deep learning-based category and fragment segmentation (CFS) framework for the automatic segmentation of pelvic bone fragments in 2D X-ray images. The framework consists of three consecutive steps: category segmentation, fragment segmentation, and post-processing. Our best model achieves an IoU of 0.91 for anatomical structures and 0.78 for fracture segmentation. Results demonstrate that the CFS framework is effective and accurate.
Benchmark of Segmentation Techniques for Pelvic Fracture in CT and X-ray: Summary of the PENGWIN 2024 Challenge
Apr 03, 2025The segmentation of pelvic fracture fragments in CT and X-ray images is crucial for trauma diagnosis, surgical planning, and intraoperative guidance. However, accurately and efficiently delineating the bone fragments remains a significant challenge due to complex anatomy and imaging limitations. The PENGWIN challenge, organized as a MICCAI 2024 satellite event, aimed to advance automated fracture segmentation by benchmarking state-of-the-art algorithms on these complex tasks. A diverse dataset of 150 CT scans was collected from multiple clinical centers, and a large set of simulated X-ray images was generated using the DeepDRR method. Final submissions from 16 teams worldwide were evaluated under a rigorous multi-metric testing scheme. The top-performing CT algorithm achieved an average fragment-wise intersection over union (IoU) of 0.930, demonstrating satisfactory accuracy. However, in the X-ray task, the best algorithm attained an IoU of 0.774, highlighting the greater challenges posed by overlapping anatomical structures. Beyond the quantitative evaluation, the challenge revealed methodological diversity in algorithm design. Variations in instance representation, such as primary-secondary classification versus boundary-core separation, led to differing segmentation strategies. Despite promising results, the challenge also exposed inherent uncertainties in fragment definition, particularly in cases of incomplete fractures. These findings suggest that interactive segmentation approaches, integrating human decision-making with task-relevant information, may be essential for improving model reliability and clinical applicability.
Task-Specific Data Preparation for Deep Learning to Reconstruct Structures of Interest from Severely Truncated CBCT Data
Sep 13, 2024
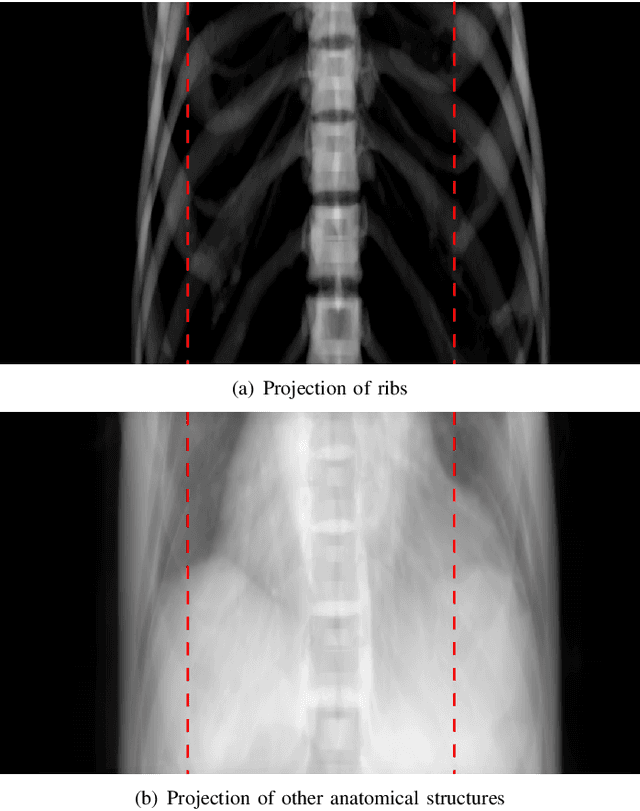
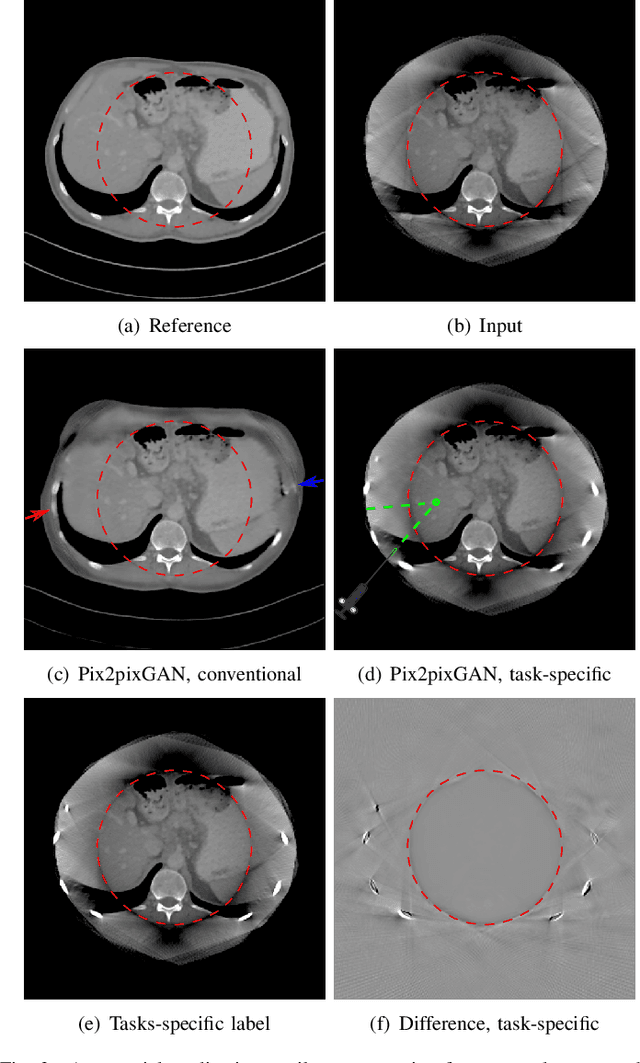
Cone-beam computed tomography (CBCT) is widely used in interventional surgeries and radiation oncology. Due to the limited size of flat-panel detectors, anatomical structures might be missing outside the limited field-of-view (FOV), which restricts the clinical applications of CBCT systems. Recently, deep learning methods have been proposed to extend the FOV for multi-slice CT systems. However, in mobile CBCT system with a smaller FOV size, projection data is severely truncated and it is challenging for a network to restore all missing structures outside the FOV. In some applications, only certain structures outside the FOV are of interest, e.g., ribs in needle path planning for liver/lung cancer diagnosis. Therefore, a task-specific data preparation method is proposed in this work, which automatically let the network focus on structures of interest instead of all the structures. Our preliminary experiment shows that Pix2pixGAN with a conventional training has the risk to reconstruct false positive and false negative rib structures from severely truncated CBCT data, whereas Pix2pixGAN with the proposed task-specific training can reconstruct all the ribs reliably. The proposed method is promising to empower CBCT with more clinical applications.
Enhancing Cross-Modality Synthesis: Subvolume Merging for MRI-to-CT Conversion
Sep 09, 2024



Providing more precise tissue attenuation information, synthetic computed tomography (sCT) generated from magnetic resonance imaging (MRI) contributes to improved radiation therapy treatment planning. In our study, we employ the advanced SwinUNETR framework for synthesizing CT from MRI images. Additionally, we introduce a three-dimensional subvolume merging technique in the prediction process. By selecting an optimal overlap percentage for adjacent subvolumes, stitching artifacts are effectively mitigated, leading to a decrease in the mean absolute error (MAE) between sCT and the labels from 52.65 HU to 47.75 HU. Furthermore, implementing a weight function with a gamma value of 0.9 results in the lowest MAE within the same overlap area. By setting the overlap percentage between 50% and 70%, we achieve a balance between image quality and computational efficiency.
Reference-Free Multi-Modality Volume Registration of X-Ray Microscopy and Light-Sheet Fluorescence Microscopy
Apr 23, 2024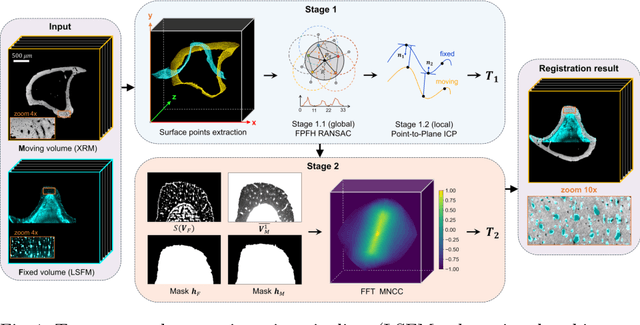
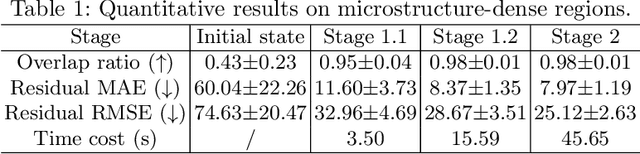
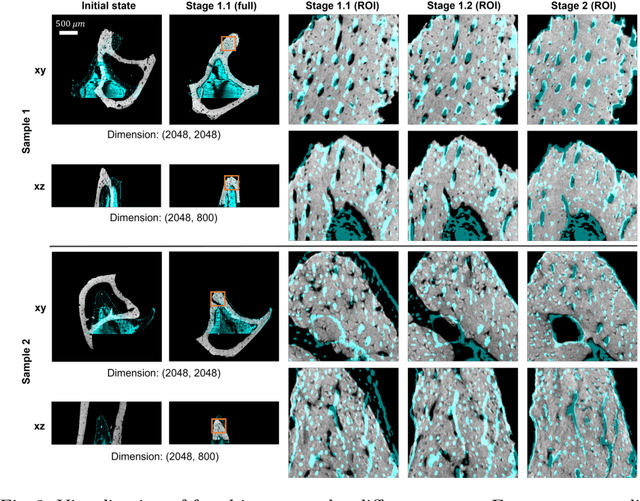
Recently, X-ray microscopy (XRM) and light-sheet fluorescence microscopy (LSFM) have emerged as two pivotal imaging tools in preclinical research on bone remodeling diseases, offering micrometer-level resolution. Integrating these complementary modalities provides a holistic view of bone microstructures, facilitating function-oriented volume analysis across different disease cycles. However, registering such independently acquired large-scale volumes is extremely challenging under real and reference-free scenarios. This paper presents a fast two-stage pipeline for volume registration of XRM and LSFM. The first stage extracts the surface features and employs two successive point cloud-based methods for coarse alignment. The second stage fine-tunes the initial alignment using a modified cross-correlation method, ensuring precise volumetric registration. Moreover, we propose residual similarity as a novel metric to assess the alignment of two complementary modalities. The results imply robust gradual improvement across the stages. In the end, all correlating microstructures, particularly lacunae in XRM and bone cells in LSFM, are precisely matched, enabling new insights into bone diseases like osteoporosis which are a substantial burden in aging societies.
Segmentation-Guided Knee Radiograph Generation using Conditional Diffusion Models
Apr 04, 2024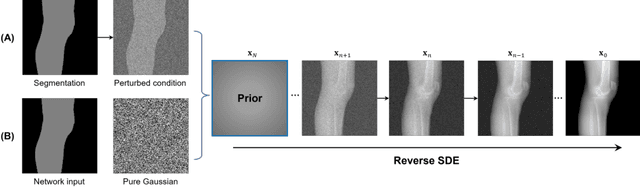
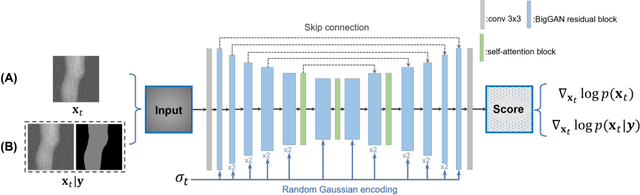
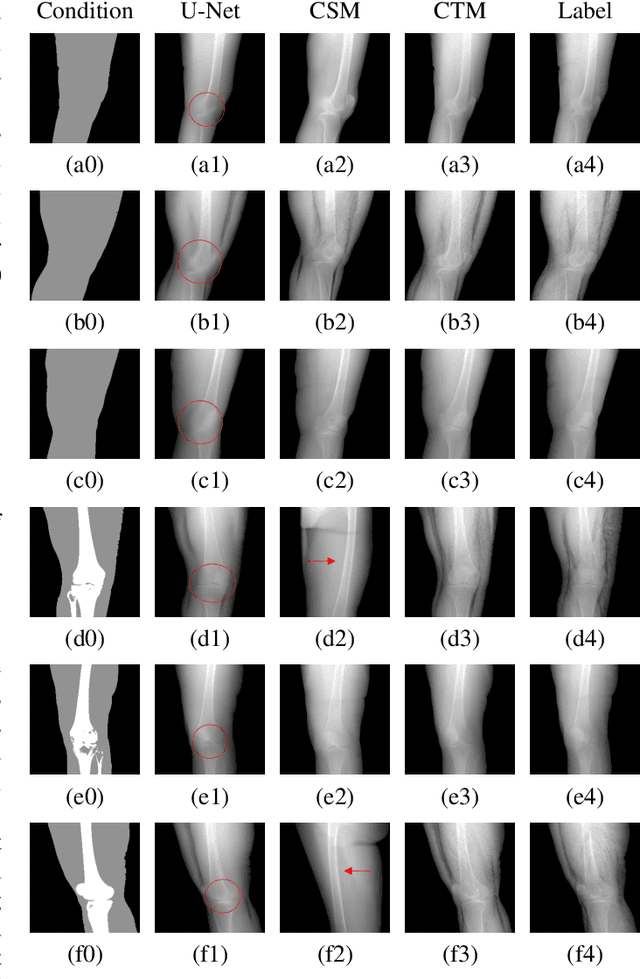
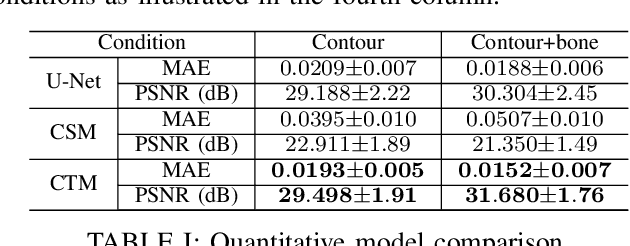
Deep learning-based medical image processing algorithms require representative data during development. In particular, surgical data might be difficult to obtain, and high-quality public datasets are limited. To overcome this limitation and augment datasets, a widely adopted solution is the generation of synthetic images. In this work, we employ conditional diffusion models to generate knee radiographs from contour and bone segmentations. Remarkably, two distinct strategies are presented by incorporating the segmentation as a condition into the sampling and training process, namely, conditional sampling and conditional training. The results demonstrate that both methods can generate realistic images while adhering to the conditioning segmentation. The conditional training method outperforms the conditional sampling method and the conventional U-Net.
AnatoMix: Anatomy-aware Data Augmentation for Multi-organ Segmentation
Mar 05, 2024


Multi-organ segmentation in medical images is a widely researched task and can save much manual efforts of clinicians in daily routines. Automating the organ segmentation process using deep learning (DL) is a promising solution and state-of-the-art segmentation models are achieving promising accuracy. In this work, We proposed a novel data augmentation strategy for increasing the generalizibility of multi-organ segmentation datasets, namely AnatoMix. By object-level matching and manipulation, our method is able to generate new images with correct anatomy, i.e. organ segmentation mask, exponentially increasing the size of the segmentation dataset. Initial experiments have been done to investigate the segmentation performance influenced by our method on a public CT dataset. Our augmentation method can lead to mean dice of 76.1, compared with 74.8 of the baseline method.