 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposition Sampling for Efficient Region Annotations in Active Learning
Dec 08, 2025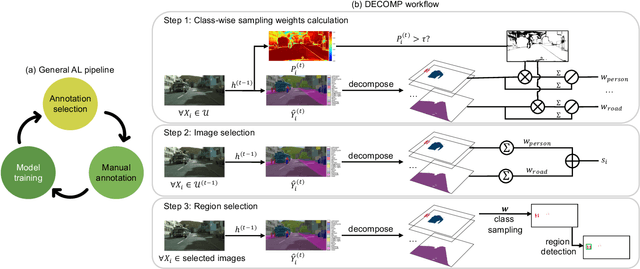
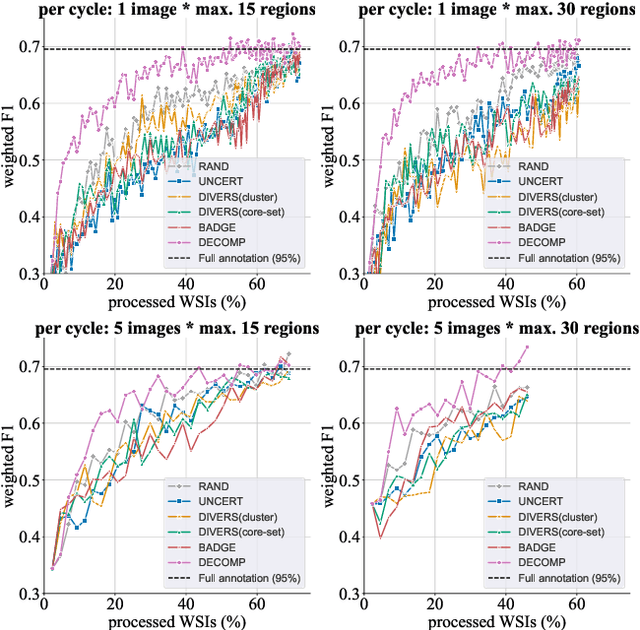
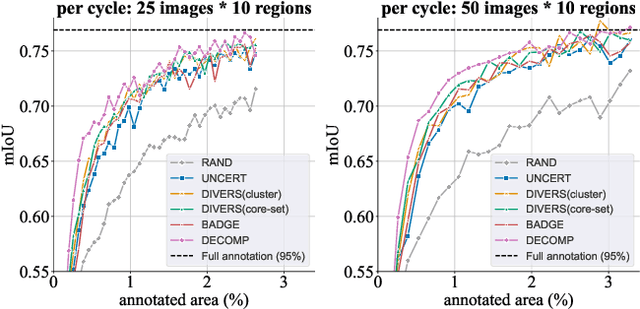
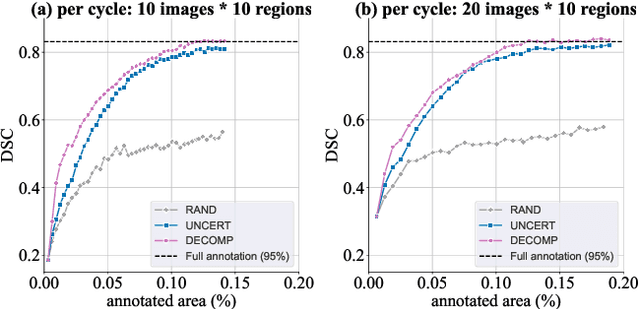
Active learning improves annotation efficiency by selecting the most informative samples for annotation and model training. While most prior work has focused on selecting informative images for classification tasks, we investigate the more challenging setting of dense prediction, where annotations are more costly and time-intensive, especially in medical imaging. Region-level annotation has been shown to be more efficient than image-level annotation for these tasks. However, existing methods for representative annotation region selection suffer from high computational and memory costs, irrelevant region choices, and heavy reliance on uncertainty sampling. We propose decomposition sampling (DECOMP), a new active learning sampling strategy that addresses these limitations. It enhances annotation diversity by decomposing images into class-specific components using pseudo-labels and sampling regions from each class. Class-wise predictive confidence further guides the sampling process, ensuring that difficult classes receive additional annotations. Across ROI classification, 2-D segmentation, and 3-D segmentation, DECOMP consistently surpasses baseline methods by better sampling minority-class regions and boosting performance on these challenging classes. Code is in https://github.com/JingnaQiu/DECOMP.git.
Effortless Vision-Language Model Specialization in Histopathology without Annotation
Aug 11, 2025Recent advances in Vision-Language Models (VLMs) in histopathology, such as CONCH and QuiltNet, have demonstrated impressive zero-shot classification capabilities across various tasks. However, their general-purpose design may lead to suboptimal performance in specific downstream applications. While supervised fine-tuning methods address this issue, they require manually labeled samples for adaptation. This paper investigates annotation-free adaptation of VLMs through continued pretraining on domain- and task-relevant image-caption pairs extracted from existing databases. Our experiments on two VLMs, CONCH and QuiltNet, across three downstream tasks reveal that these pairs substantially enhance both zero-shot and few-shot performance. Notably, with larger training sizes, continued pretraining matches the performance of few-shot methods while eliminating manual labeling. Its effectiveness, task-agnostic design, and annotation-free workflow make it a promising pathway for adapting VLMs to new histopathology tasks. Code is available at https://github.com/DeepMicroscopy/Annotation-free-VLM-specialization.
Enhancing Cross-Modality Synthesis: Subvolume Merging for MRI-to-CT Conversion
Sep 09, 2024



Providing more precise tissue attenuation information, synthetic computed tomography (sCT) generated from magnetic resonance imaging (MRI) contributes to improved radiation therapy treatment planning. In our study, we employ the advanced SwinUNETR framework for synthesizing CT from MRI images. Additionally, we introduce a three-dimensional subvolume merging technique in the prediction process. By selecting an optimal overlap percentage for adjacent subvolumes, stitching artifacts are effectively mitigated, leading to a decrease in the mean absolute error (MAE) between sCT and the labels from 52.65 HU to 47.75 HU. Furthermore, implementing a weight function with a gamma value of 0.9 results in the lowest MAE within the same overlap area. By setting the overlap percentage between 50% and 70%, we achieve a balance between image quality and computational efficiency.
Leveraging image captions for selective whole slide image annotation
Jul 08, 2024


Acquiring annotations for whole slide images (WSIs)-based deep learning tasks, such as creating tissue segmentation masks or detecting mitotic figures, is a laborious process due to the extensive image size and the significant manual work involved in the annotation. This paper focuses on identifying and annotating specific image regions that optimize model training, given a limited annotation budget. While random sampling helps capture data variance by collecting annotation regions throughout the WSIs, insufficient data curation may result in an inadequate representation of minority classes. Recent studies proposed diversity sampling to select a set of regions that maximally represent unique characteristics of the WSIs. This is done by pretraining on unlabeled data through self-supervised learning and then clustering all regions in the latent space. However, establishing the optimal number of clusters can be difficult and not all clusters are task-relevant. This paper presents prototype sampling, a new method for annotation region selection. It discovers regions exhibiting typical characteristics of each task-specific class. The process entails recognizing class prototypes from extensive histopathology image-caption databases and detecting unlabeled image regions that resemble these prototypes. Our results show that prototype sampling is more effective than random and diversity sampling in identifying annotation regions with valuable training information, resulting in improved model performance in semantic segmentation and mitotic figure detection tasks. Code is available at https://github.com/DeepMicroscopy/Prototype-sampling.
Style-Extracting Diffusion Models for Semi-Supervised Histopathology Segmentation
Mar 21, 2024Deep learning-based image generation has seen significant advancements with diffusion models, notably improving the quality of generated images. Despite these developments, generating images with unseen characteristics beneficial for downstream tasks has received limited attention. To bridge this gap, we propose Style-Extracting Diffusion Models, featuring two conditioning mechanisms. Specifically, we utilize 1) a style conditioning mechanism which allows to inject style information of previously unseen images during image generation and 2) a content conditioning which can be targeted to a downstream task, e.g., layout for segmentation. We introduce a trainable style encoder to extract style information from images, and an aggregation block that merges style information from multiple style inputs. This architecture enables the generation of images with unseen styles in a zero-shot manner, by leveraging styles from unseen images, resulting in more diverse generations. In this work, we use the image layout as target condition and first show the capability of our method on a natural image dataset as a proof-of-concept. We further demonstrate its versatility in histopathology, where we combine prior knowledge about tissue composition and unannotated data to create diverse synthetic images with known layouts. This allows us to generate additional synthetic data to train a segmentation network in a semi-supervised fashion. We verify the added value of the generated images by showing improved segmentation results and lower performance variability between patients when synthetic images are included during segmentation training. Our code will be made publicly available at [LINK].
Adaptive Region Selection for Active Learning in Whole Slide Image Semantic Segmentation
Jul 14, 2023



The process of annotating histological gigapixel-sized whole slide images (WSIs) at the pixel level for the purpose of training a supervised segmentation model is time-consuming. Region-based active learning (AL) involves training the model on a limited number of annotated image regions instead of requesting annotations of the entire images. These annotation regions are iteratively selected, with the goal of optimizing model performance while minimizing the annotated area. The standard method for region selection evaluates the informativeness of all square regions of a specified size and then selects a specific quantity of the most informative regions. We find that the efficiency of this method highly depends on the choice of AL step size (i.e., the combination of region size and the number of selected regions per WSI), and a suboptimal AL step size can result in redundant annotation requests or inflated computation costs. This paper introduces a novel technique for selecting annotation regions adaptively, mitigating the reliance on this AL hyperparameter. Specifically, we dynamically determine each region by first identifying an informative area and then detecting its optimal bounding box, as opposed to selecting regions of a uniform predefined shape and size as in the standard method. We evaluate our method using the task of breast cancer metastases segmentation on the public CAMELYON16 dataset and show that it consistently achieves higher sampling efficiency than the standard method across various AL step sizes. With only 2.6\% of tissue area annotated, we achieve full annotation performance and thereby substantially reduce the costs of annotating a WSI dataset. The source code is available at https://github.com/DeepMicroscopy/AdaptiveRegionSelection.
Multi-Scanner Canine Cutaneous Squamous Cell Carcinoma Histopathology Dataset
Jan 11, 2023

In histopathology, scanner-induced domain shifts are known to impede the performance of trained neural networks when tested on unseen data. Multi-domain pre-training or dedicated domain-generalization techniques can help to develop domain-agnostic algorithms. For this, multi-scanner datasets with a high variety of slide scanning systems are highly desirable. We present a publicly available multi-scanner dataset of canine cutaneous squamous cell carcinoma histopathology images, composed of 44 samples digitized with five slide scanners. This dataset provides local correspondences between images and thereby isolates the scanner-induced domain shift from other inherent, e.g. morphology-induced domain shifts. To highlight scanner differences, we present a detailed evaluation of color distributions, sharpness, and contrast of the individual scanner subsets. Additionally, to quantify the inherent scanner-induced domain shift, we train a tumor segmentation network on each scanner subset and evaluate the performance both in- and cross-domain. We achieve a class-averaged in-domain intersection over union coefficient of up to 0.86 and observe a cross-domain performance decrease of up to 0.38, which confirms the inherent domain shift of the presented dataset and its negative impact on the performance of deep neural networks.
Mind the Gap: Scanner-induced domain shifts pose challenges for representation learning in histopathology
Nov 29, 2022
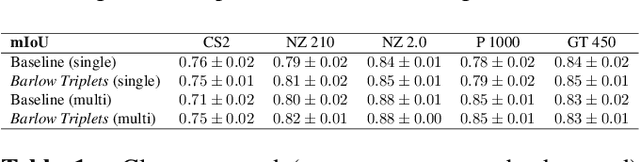
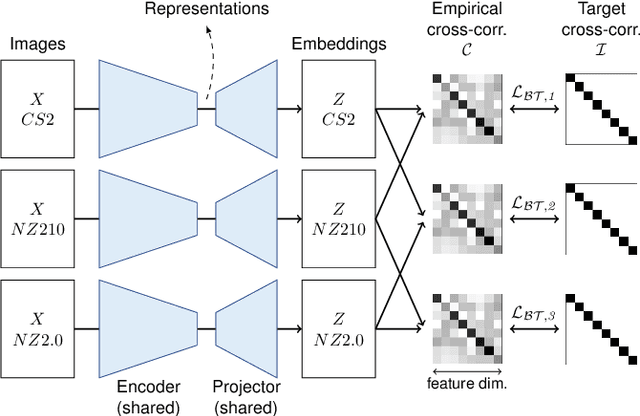
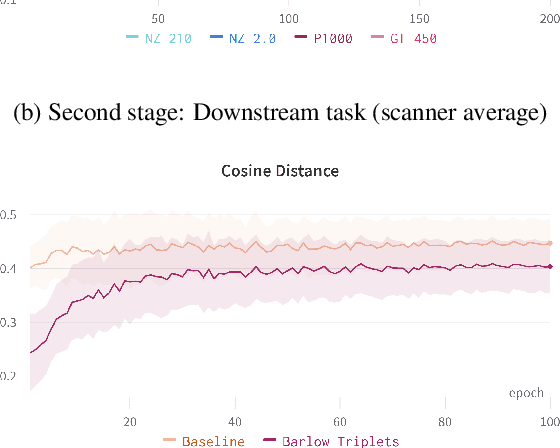
Computer-aided systems in histopathology are often challenged by various sources of domain shift that impact the performance of these algorithms considerably. We investigated the potential of using self-supervised pre-training to overcome scanner-induced domain shifts for the downstream task of tumor segmentation. For this, we present the Barlow Triplets to learn scanner-invariant representations from a multi-scanner dataset with local image correspondences. We show that self-supervised pre-training successfully aligned different scanner representations, which, interestingly only results in a limited benefit for our downstream task. We thereby provide insights into the influence of scanner characteristics for downstream applications and contribute to a better understanding of why established self-supervised methods have not yet shown the same success on histopathology data as they have for natural images.
Improved HER2 Tumor Segmentation with Subtype Balancing using Deep Generative Networks
Nov 11, 2022



Tumor segmentation in histopathology images is often complicated by its composition of different histological subtypes and class imbalance. Oversampling subtypes with low prevalence features is not a satisfactory solution since it eventually leads to overfitting. We propose to create synthetic images with semantically-conditioned deep generative networks and to combine subtype-balanced synthetic images with the original dataset to achieve better segmentation performance. We show the suitability of Generative Adversarial Networks (GANs) and especially diffusion models to create realistic images based on subtype-conditioning for the use case of HER2-stained histopathology. Additionally, we show the capability of diffusion models to conditionally inpaint HER2 tumor areas with modified subtypes. Combining the original dataset with the same amount of diffusion-generated images increased the tumor Dice score from 0.833 to 0.854 and almost halved the variance between the HER2 subtype recalls. These results create the basis for more reliable automatic HER2 analysis with lower performance variance between individual HER2 subtypes.
Pan-Tumor CAnine cuTaneous Cancer Histology (CATCH) Dataset
Jan 27, 2022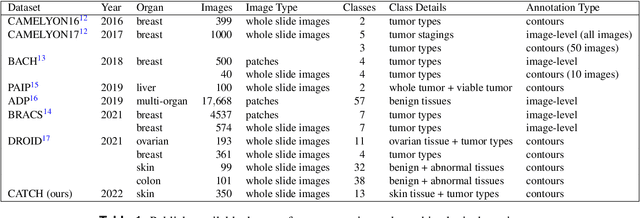
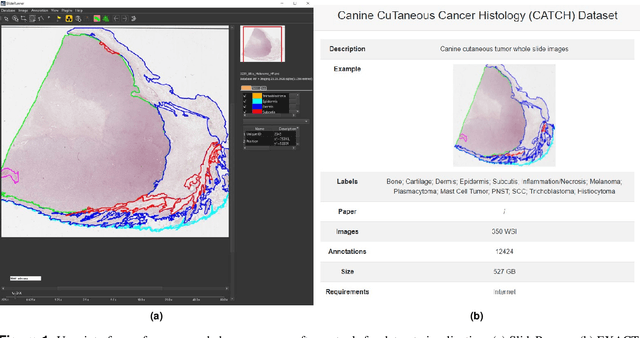
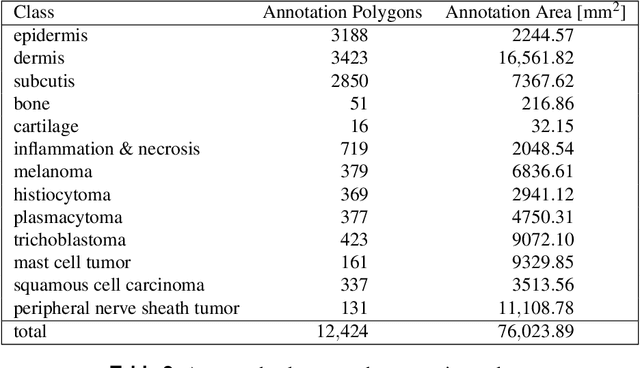

Due to morphological similarities, the differentiation of histologic sections of cutaneous tumors into individual subtypes can be challenging. Recently, deep learning-based approaches have proven their potential for supporting pathologists in this regard. However, many of these supervised algorithms require a large amount of annotated data for robust development. We present a publicly available dataset consisting of 350 whole slide images of seven different canine cutaneous tumors complemented by 12,424 polygon annotations for 13 histologic classes including seven cutaneous tumor subtypes. Regarding sample size and annotation extent, this exceeds most publicly available datasets which are oftentimes limited to the tumor area or merely provide patch-level annotations. We validated our model for tissue segmentation, achieving a class-averaged Jaccard coefficient of 0.7047, and 0.9044 for tumor in particular. For tumor subtype classification, we achieve a slide-level accuracy of 0.9857. Since canine cutaneous tumors possess various histologic homologies to human tumors, we believe that the added value of this dataset is not limited to veterinary pathology but extends to more general fields of application.