 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposition Sampling for Efficient Region Annotations in Active Learning
Dec 08, 2025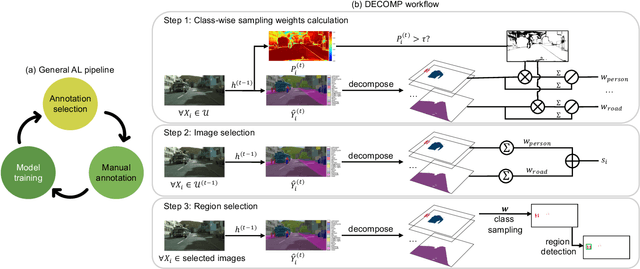
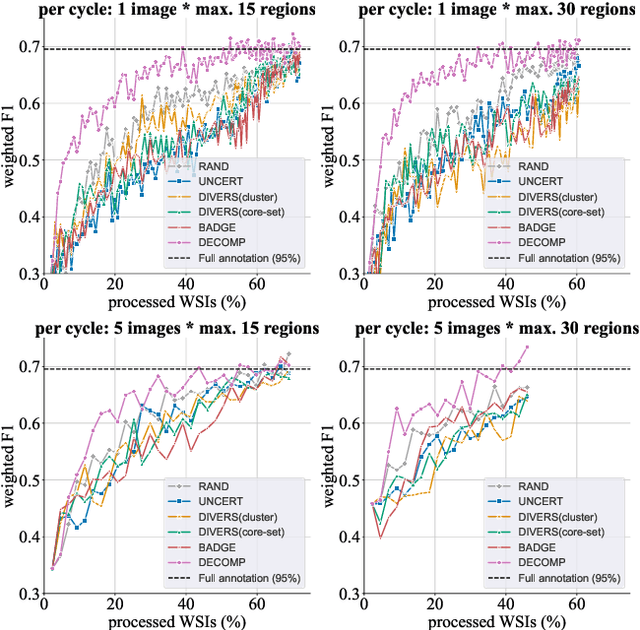
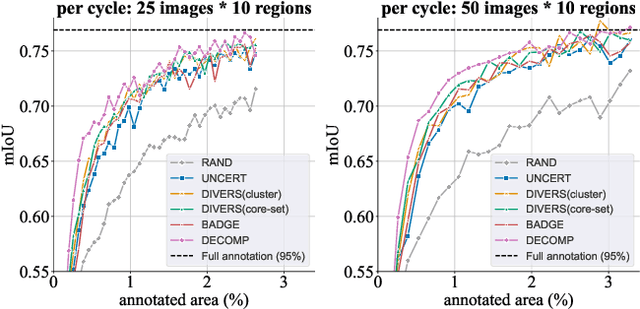
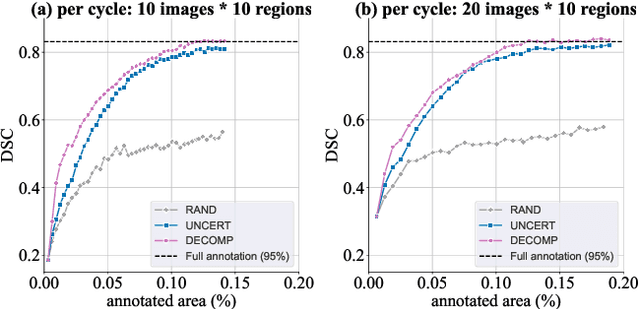
Active learning improves annotation efficiency by selecting the most informative samples for annotation and model training. While most prior work has focused on selecting informative images for classification tasks, we investigate the more challenging setting of dense prediction, where annotations are more costly and time-intensive, especially in medical imaging. Region-level annotation has been shown to be more efficient than image-level annotation for these tasks. However, existing methods for representative annotation region selection suffer from high computational and memory costs, irrelevant region choices, and heavy reliance on uncertainty sampling. We propose decomposition sampling (DECOMP), a new active learning sampling strategy that addresses these limitations. It enhances annotation diversity by decomposing images into class-specific components using pseudo-labels and sampling regions from each class. Class-wise predictive confidence further guides the sampling process, ensuring that difficult classes receive additional annotations. Across ROI classification, 2-D segmentation, and 3-D segmentation, DECOMP consistently surpasses baseline methods by better sampling minority-class regions and boosting performance on these challenging classes. Code is in https://github.com/JingnaQiu/DECOMP.git.
CyclePose -- Leveraging Cycle-Consistency for Annotation-Free Nuclei Segmentation in Fluorescence Microscopy
Mar 14, 2025In recent years, numerous neural network architectures specifically designed for the instance segmentation of nuclei in microscopic images have been released. These models embed nuclei-specific priors to outperform generic architectures like U-Nets; however, they require large annotated datasets, which are often not available. Generative models (GANs, diffusion models) have been used to compensate for this by synthesizing training data. These two-stage approaches are computationally expensive, as first a generative model and then a segmentation model has to be trained. We propose CyclePose, a hybrid framework integrating synthetic data generation and segmentation training. CyclePose builds on a CycleGAN architecture, which allows unpaired translation between microscopy images and segmentation masks. We embed a segmentation model into CycleGAN and leverage a cycle consistency loss for self-supervision. Without annotated data, CyclePose outperforms other weakly or unsupervised methods on two public datasets. Code is available at https://github.com/jonasutz/CyclePose
DiffRenderGAN: Addressing Training Data Scarcity in Deep Segmentation Networks for Quantitative Nanomaterial Analysis through Differentiable Rendering and Generative Modelling
Feb 13, 2025Nanomaterials exhibit distinctive properties governed by parameters such as size, shape, and surface characteristics, which critically influence their applications and interactions across technological, biological, and environmental contexts. Accurate quantification and understanding of these materials are essential for advancing research and innovation. In this regard, deep learning segmentation networks have emerged as powerful tools that enable automated insights and replace subjective methods with precise quantitative analysis. However, their efficacy depends on representative annotated datasets, which are challenging to obtain due to the costly imaging of nanoparticles and the labor-intensive nature of manual annotations. To overcome these limitations, we introduce DiffRenderGAN, a novel generative model designed to produce annotated synthetic data. By integrating a differentiable renderer into a Generative Adversarial Network (GAN) framework, DiffRenderGAN optimizes textural rendering parameters to generate realistic, annotated nanoparticle images from non-annotated real microscopy images. This approach reduces the need for manual intervention and enhances segmentation performance compared to existing synthetic data methods by generating diverse and realistic data. Tested on multiple ion and electron microscopy cases, including titanium dioxide (TiO$_2$), silicon dioxide (SiO$_2$)), and silver nanowires (AgNW), DiffRenderGAN bridges the gap between synthetic and real data, advancing the quantification and understanding of complex nanomaterial systems.
Leveraging image captions for selective whole slide image annotation
Jul 08, 2024


Acquiring annotations for whole slide images (WSIs)-based deep learning tasks, such as creating tissue segmentation masks or detecting mitotic figures, is a laborious process due to the extensive image size and the significant manual work involved in the annotation. This paper focuses on identifying and annotating specific image regions that optimize model training, given a limited annotation budget. While random sampling helps capture data variance by collecting annotation regions throughout the WSIs, insufficient data curation may result in an inadequate representation of minority classes. Recent studies proposed diversity sampling to select a set of regions that maximally represent unique characteristics of the WSIs. This is done by pretraining on unlabeled data through self-supervised learning and then clustering all regions in the latent space. However, establishing the optimal number of clusters can be difficult and not all clusters are task-relevant. This paper presents prototype sampling, a new method for annotation region selection. It discovers regions exhibiting typical characteristics of each task-specific class. The process entails recognizing class prototypes from extensive histopathology image-caption databases and detecting unlabeled image regions that resemble these prototypes. Our results show that prototype sampling is more effective than random and diversity sampling in identifying annotation regions with valuable training information, resulting in improved model performance in semantic segmentation and mitotic figure detection tasks. Code is available at https://github.com/DeepMicroscopy/Prototype-sampling.
Differentiable Score-Based Likelihoods: Learning CT Motion Compensation From Clean Images
Apr 23, 2024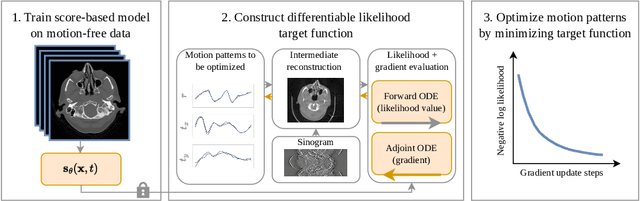
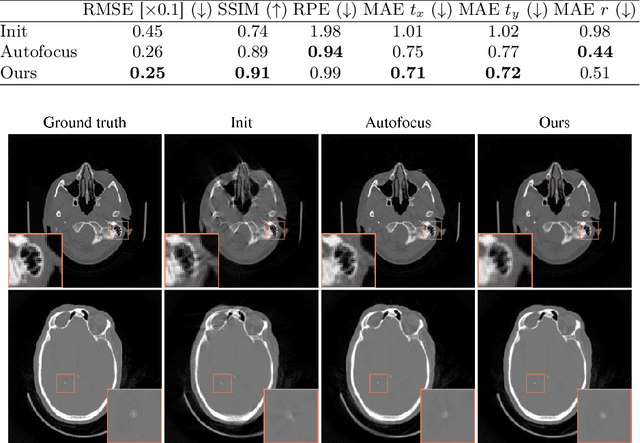
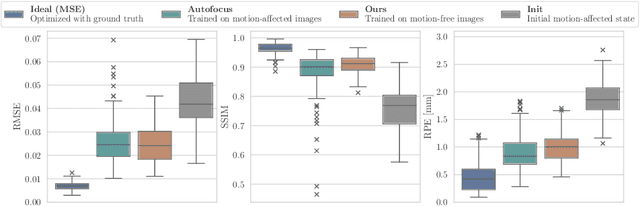
Motion artifacts can compromise the diagnostic value of computed tomography (CT) images. Motion correction approaches require a per-scan estimation of patient-specific motion patterns. In this work, we train a score-based model to act as a probability density estimator for clean head CT images. Given the trained model, we quantify the deviation of a given motion-affected CT image from the ideal distribution through likelihood computation. We demonstrate that the likelihood can be utilized as a surrogate metric for motion artifact severity in the CT image facilitating the application of an iterative, gradient-based motion compensation algorithm. By optimizing the underlying motion parameters to maximize likelihood, our method effectively reduces motion artifacts, bringing the image closer to the distribution of motion-free scans. Our approach achieves comparable performance to state-of-the-art methods while eliminating the need for a representative data set of motion-affected samples. This is particularly advantageous in real-world applications, where patient motion patterns may exhibit unforeseen variability, ensuring robustness without implicit assumptions about recoverable motion types.
Focus on Content not Noise: Improving Image Generation for Nuclei Segmentation by Suppressing Steganography in CycleGAN
Aug 03, 2023Annotating nuclei in microscopy images for the training of neural networks is a laborious task that requires expert knowledge and suffers from inter- and intra-rater variability, especially in fluorescence microscopy. Generative networks such as CycleGAN can inverse the process and generate synthetic microscopy images for a given mask, thereby building a synthetic dataset. However, past works report content inconsistencies between the mask and generated image, partially due to CycleGAN minimizing its loss by hiding shortcut information for the image reconstruction in high frequencies rather than encoding the desired image content and learning the target task. In this work, we propose to remove the hidden shortcut information, called steganography, from generated images by employing a low pass filtering based on the DCT. We show that this increases coherence between generated images and cycled masks and evaluate synthetic datasets on a downstream nuclei segmentation task. Here we achieve an improvement of 5.4 percentage points in the F1-score compared to a vanilla CycleGAN. Integrating advanced regularization techniques into the CycleGAN architecture may help mitigate steganography-related issues and produce more accurate synthetic datasets for nuclei segmentation.
Noise2Contrast: Multi-Contrast Fusion Enables Self-Supervised Tomographic Image Denoising
Dec 09, 2022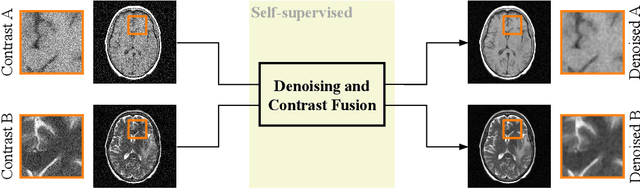
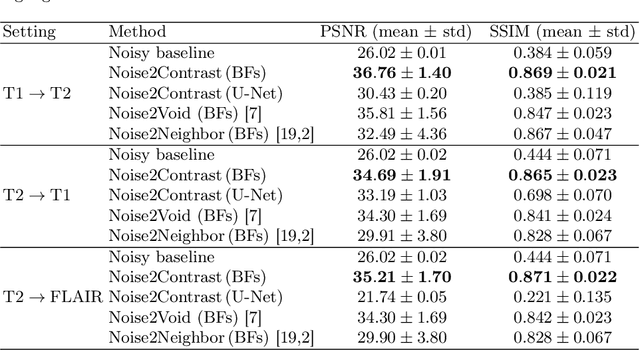
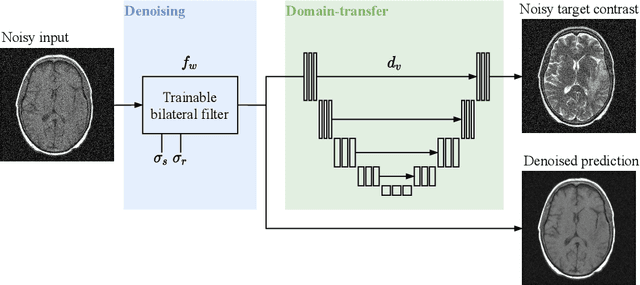

Self-supervised image denoising techniques emerged as convenient methods that allow training denoising models without requiring ground-truth noise-free data. Existing methods usually optimize loss metrics that are calculated from multiple noisy realizations of similar images, e.g., from neighboring tomographic slices. However, those approaches fail to utilize the multiple contrasts that are routinely acquired in medical imaging modalities like MRI or dual-energy CT. In this work, we propose the new self-supervised training scheme Noise2Contrast that combines information from multiple measured image contrasts to train a denoising model. We stack denoising with domain-transfer operators to utilize the independent noise realizations of different image contrasts to derive a self-supervised loss. The trained denoising operator achieves convincing quantitative and qualitative results, outperforming state-of-the-art self-supervised methods by 4.7-11.0%/4.8-7.3% (PSNR/SSIM) on brain MRI data and by 43.6-50.5%/57.1-77.1% (PSNR/SSIM) on dual-energy CT X-ray microscopy data with respect to the noisy baseline. Our experiments on different real measured data sets indicate that Noise2Contrast training generalizes to other multi-contrast imaging modalities.
Gradient-Based Geometry Learning for Fan-Beam CT Reconstruction
Dec 05, 2022Incorporating computed tomography (CT) reconstruction operators into differentiable pipelines has proven beneficial in many applications. Such approaches usually focus on the projection data and keep the acquisition geometry fixed. However, precise knowledge of the acquisition geometry is essential for high quality reconstruction results. In this paper, the differentiable formulation of fan-beam CT reconstruction is extended to the acquisition geometry. This allows to propagate gradient information from a loss function on the reconstructed image into the geometry parameters. As a proof-of-concept experiment, this idea is applied to rigid motion compensation. The cost function is parameterized by a trained neural network which regresses an image quality metric from the motion affected reconstruction alone. Using the proposed method, we are the first to optimize such an autofocus-inspired algorithm based on analytical gradients. The algorithm achieves a reduction in MSE by 35.5 % and an improvement in SSIM by 12.6 % over the motion affected reconstruction. Next to motion compensation, we see further use cases of our differentiable method for scanner calibration or hybrid techniques employing deep models.
On the Benefit of Dual-domain Denoising in a Self-supervised Low-dose CT Setting
Nov 03, 2022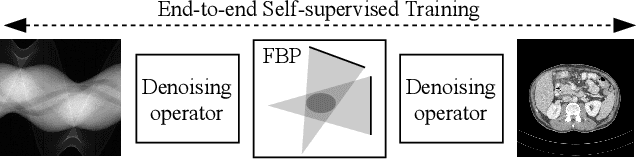
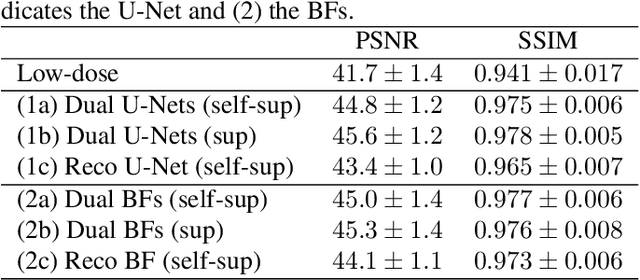
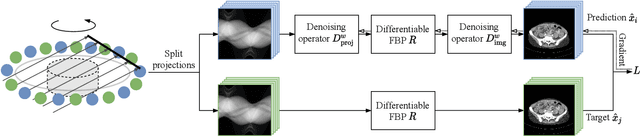
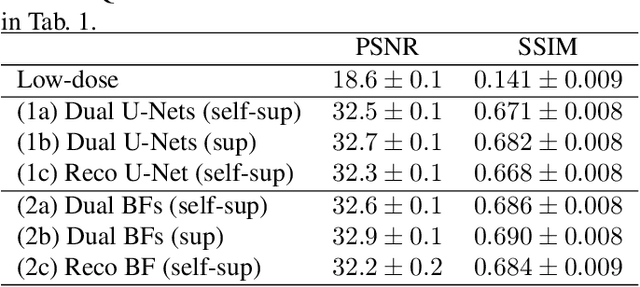
Computed tomography (CT) is routinely used for three-dimensional non-invasive imaging. Numerous data-driven image denoising algorithms were proposed to restore image quality in low-dose acquisitions. However, considerably less research investigates methods already intervening in the raw detector data due to limited access to suitable projection data or correct reconstruction algorithms. In this work, we present an end-to-end trainable CT reconstruction pipeline that contains denoising operators in both the projection and the image domain and that are optimized simultaneously without requiring ground-truth high-dose CT data. Our experiments demonstrate that including an additional projection denoising operator improved the overall denoising performance by 82.4-94.1%/12.5-41.7% (PSNR/SSIM) on abdomen CT and 1.5-2.9%/0.4-0.5% (PSNR/SSIM) on XRM data relative to the low-dose baseline. We make our entire helical CT reconstruction framework publicly available that contains a raw projection rebinning step to render helical projection data suitable for differentiable fan-beam reconstruction operators and end-to-end learning.