 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker- and Text-Independent Estimation of Articulatory Movements and Phoneme Alignments from Speech
Jul 03, 2024This paper introduces a novel combination of two tasks, previously treated separately: acoustic-to-articulatory speech inversion (AAI) and phoneme-to-articulatory (PTA) motion estimation. We refer to this joint task as acoustic phoneme-to-articulatory speech inversion (APTAI) and explore two different approaches, both working speaker- and text-independently during inference. We use a multi-task learning setup, with the end-to-end goal of taking raw speech as input and estimating the corresponding articulatory movements, phoneme sequence, and phoneme alignment. While both proposed approaches share these same requirements, they differ in their way of achieving phoneme-related predictions: one is based on frame classification, the other on a two-staged training procedure and forced alignment. We reach competitive performance of 0.73 mean correlation for the AAI task and achieve up to approximately 87% frame overlap compared to a state-of-the-art text-dependent phoneme force aligner.
Towards Intelligent Speech Assistants in Operating Rooms: A Multimodal Model for Surgical Workflow Analysis
Jun 17, 2024



To develop intelligent speech assistants and integrate them seamlessly with intra-operative decision-support frameworks, accurate and efficient surgical phase recognition is a prerequisite. In this study, we propose a multimodal framework based on Gated Multimodal Units (GMU) and Multi-Stage Temporal Convolutional Networks (MS-TCN) to recognize surgical phases of port-catheter placement operations. Our method merges speech and image models and uses them separately in different surgical phases. Based on the evaluation of 28 operations, we report a frame-wise accuracy of 92.65 $\pm$ 3.52% and an F1-score of 92.30 $\pm$ 3.82%. Our results show approximately 10% improvement in both metrics over previous work and validate the effectiveness of integrating multimodal data for the surgical phase recognition task. We further investigate the contribution of individual data channels by comparing mono-modal models with multimodal models.
The Impact of Speech Anonymization on Pathology and Its Limits
Apr 11, 2024Integration of speech into healthcare has intensified privacy concerns due to its potential as a non-invasive biomarker containing individual biometric information. In response, speaker anonymization aims to conceal personally identifiable information while retaining crucial linguistic content. However, the application of anonymization techniques to pathological speech, a critical area where privacy is especially vital, has not been extensively examined. This study investigates anonymization's impact on pathological speech across over 2,700 speakers from multiple German institutions, focusing on privacy, pathological utility, and demographic fairness. We explore both training-based and signal processing-based anonymization methods, and document substantial privacy improvements across disorders-evidenced by equal error rate increases up to 1933%, with minimal overall impact on utility. Specific disorders such as Dysarthria, Dysphonia, and Cleft Lip and Palate experienced minimal utility changes, while Dysglossia showed slight improvements. Our findings underscore that the impact of anonymization varies substantially across different disorders. This necessitates disorder-specific anonymization strategies to optimally balance privacy with diagnostic utility. Additionally, our fairness analysis revealed consistent anonymization effects across most of the demographics. This study demonstrates the effectiveness of anonymization in pathological speech for enhancing privacy, while also highlighting the importance of customized approaches to account for inversion attacks.
Focus on Content not Noise: Improving Image Generation for Nuclei Segmentation by Suppressing Steganography in CycleGAN
Aug 03, 2023Annotating nuclei in microscopy images for the training of neural networks is a laborious task that requires expert knowledge and suffers from inter- and intra-rater variability, especially in fluorescence microscopy. Generative networks such as CycleGAN can inverse the process and generate synthetic microscopy images for a given mask, thereby building a synthetic dataset. However, past works report content inconsistencies between the mask and generated image, partially due to CycleGAN minimizing its loss by hiding shortcut information for the image reconstruction in high frequencies rather than encoding the desired image content and learning the target task. In this work, we propose to remove the hidden shortcut information, called steganography, from generated images by employing a low pass filtering based on the DCT. We show that this increases coherence between generated images and cycled masks and evaluate synthetic datasets on a downstream nuclei segmentation task. Here we achieve an improvement of 5.4 percentage points in the F1-score compared to a vanilla CycleGAN. Integrating advanced regularization techniques into the CycleGAN architecture may help mitigate steganography-related issues and produce more accurate synthetic datasets for nuclei segmentation.
PoCaP Corpus: A Multimodal Dataset for Smart Operating Room Speech Assistant using Interventional Radiology Workflow Analysis
Jun 24, 2022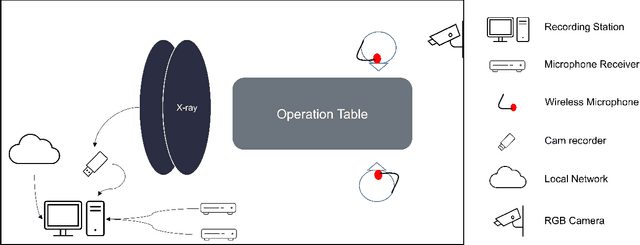
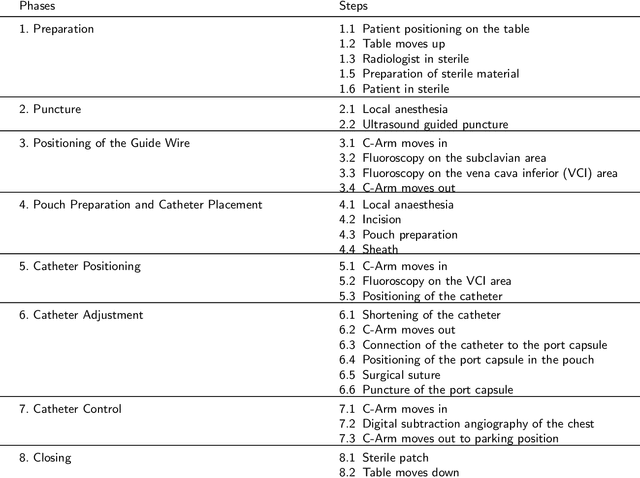
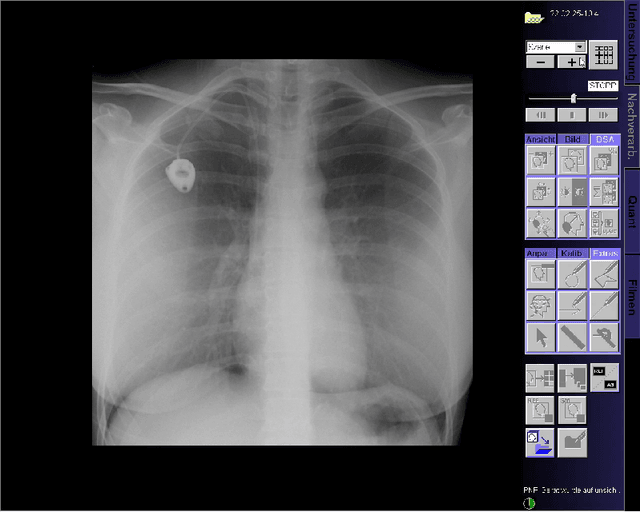

This paper presents a new multimodal interventional radiology dataset, called PoCaP (Port Catheter Placement) Corpus. This corpus consists of speech and audio signals in German, X-ray images, and system commands collected from 31 PoCaP interventions by six surgeons with average duration of 81.4 $\pm$ 41.0 minutes. The corpus aims to provide a resource for developing a smart speech assistant in operating rooms. In particular, it may be used to develop a speech controlled system that enables surgeons to control the operation parameters such as C-arm movements and table positions. In order to record the dataset, we acquired consent by the institutional review board and workers council in the University Hospital Erlangen and by the patients for data privacy. We describe the recording set-up, data structure, workflow and preprocessing steps, and report the first PoCaP Corpus speech recognition analysis results with 11.52 $\%$ word error rate using pretrained models. The findings suggest that the data has the potential to build a robust command recognition system and will allow the development of a novel intervention support systems using speech and image processing in the medical domain.
Is Speech Pathology a Biomarker in Automatic Speaker Verification?
Apr 13, 2022


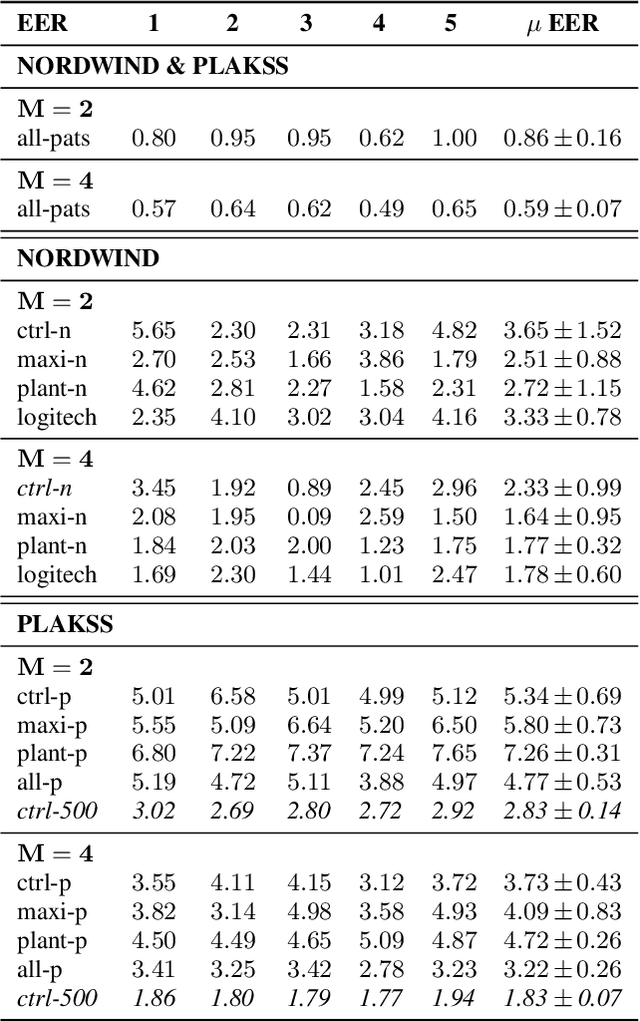
With the advancements in deep learning (DL) and an increasing interest in data-driven speech processing methods, a major challenge for speech data scientists in the healthcare domain is the anonymization of pathological speech, which is a required step to be able to make them accessible as a public training resource. In this paper, we investigate pathological speech data and compare their speaker verifiability with that of healthy individuals. We utilize a large pathological speech corpus of more than 2,000 test subjects with various speech and voice disorders from different ages and apply DL-based automatic speaker verification (ASV) techniques. As a result, we obtained a mean equal error rate (EER) of 0.86% with a standard deviation of 0.16%, which is a factor of three lower than comparable healthy speech databases. We further perform detailed analyses of external influencing factors on ASV such as age, pathology, recording environment, and utterance length, to explore their respective effect. Our findings indicate that speech pathology is a potential biomarker in ASV. This is potentially of high interest for the anonymization of pathological speech data.
Disentangled Latent Speech Representation for Automatic Pathological Intelligibility Assessment
Apr 08, 2022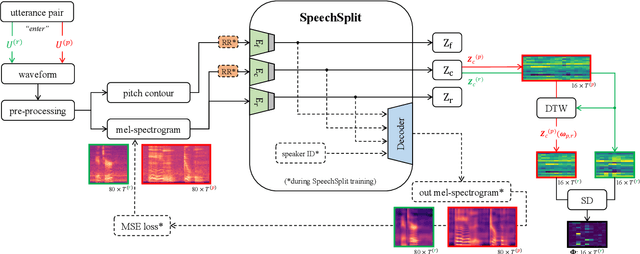
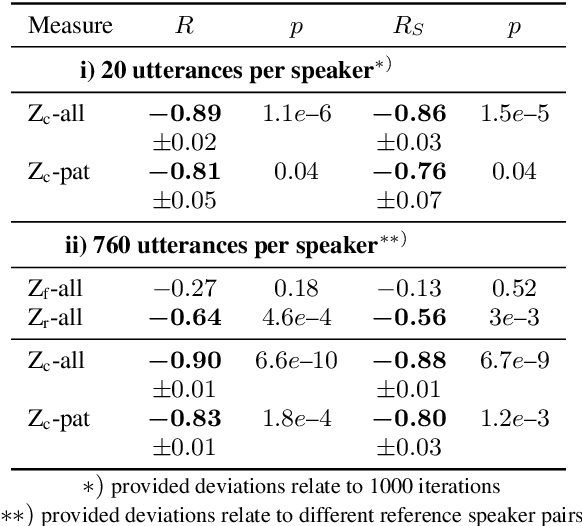
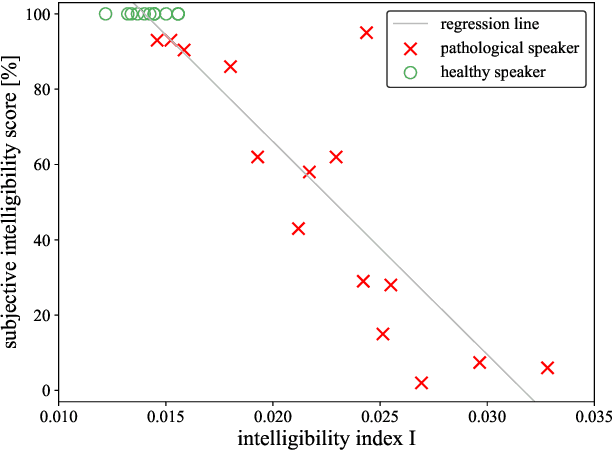
Speech intelligibility assessment plays an important role in the therapy of patients suffering from pathological speech disorders. Automatic and objective measures are desirable to assist therapists in their traditionally subjective and labor-intensive assessments. In this work, we investigate a novel approach for obtaining such a measure using the divergence in disentangled latent speech representations of a parallel utterance pair, obtained from a healthy reference and a pathological speaker. Experiments on an English database of Cerebral Palsy patients, using all available utterances per speaker, show high and significant correlation values (R = -0.9) with subjective intelligibility measures, while having only minimal deviation (+-0.01) across four different reference speaker pairs. We also demonstrate the robustness of the proposed method (R = -0.89 deviating +-0.02 over 1000 iterations) by considering a significantly smaller amount of utterances per speaker. Our results are among the first to show that disentangled speech representations can be used for automatic pathological speech intelligibility assessment, resulting in a reference speaker pair invariant method, applicable in scenarios with only few utterances available.