 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker- and Text-Independent Estimation of Articulatory Movements and Phoneme Alignments from Speech
Jul 03, 2024This paper introduces a novel combination of two tasks, previously treated separately: acoustic-to-articulatory speech inversion (AAI) and phoneme-to-articulatory (PTA) motion estimation. We refer to this joint task as acoustic phoneme-to-articulatory speech inversion (APTAI) and explore two different approaches, both working speaker- and text-independently during inference. We use a multi-task learning setup, with the end-to-end goal of taking raw speech as input and estimating the corresponding articulatory movements, phoneme sequence, and phoneme alignment. While both proposed approaches share these same requirements, they differ in their way of achieving phoneme-related predictions: one is based on frame classification, the other on a two-staged training procedure and forced alignment. We reach competitive performance of 0.73 mean correlation for the AAI task and achieve up to approximately 87% frame overlap compared to a state-of-the-art text-dependent phoneme force aligner.
Towards Intelligent Speech Assistants in Operating Rooms: A Multimodal Model for Surgical Workflow Analysis
Jun 17, 2024



To develop intelligent speech assistants and integrate them seamlessly with intra-operative decision-support frameworks, accurate and efficient surgical phase recognition is a prerequisite. In this study, we propose a multimodal framework based on Gated Multimodal Units (GMU) and Multi-Stage Temporal Convolutional Networks (MS-TCN) to recognize surgical phases of port-catheter placement operations. Our method merges speech and image models and uses them separately in different surgical phases. Based on the evaluation of 28 operations, we report a frame-wise accuracy of 92.65 $\pm$ 3.52% and an F1-score of 92.30 $\pm$ 3.82%. Our results show approximately 10% improvement in both metrics over previous work and validate the effectiveness of integrating multimodal data for the surgical phase recognition task. We further investigate the contribution of individual data channels by comparing mono-modal models with multimodal models.
PoCaP Corpus: A Multimodal Dataset for Smart Operating Room Speech Assistant using Interventional Radiology Workflow Analysis
Jun 24, 2022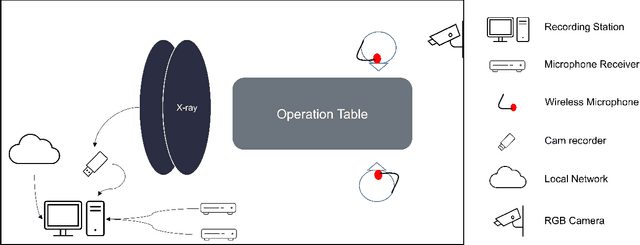
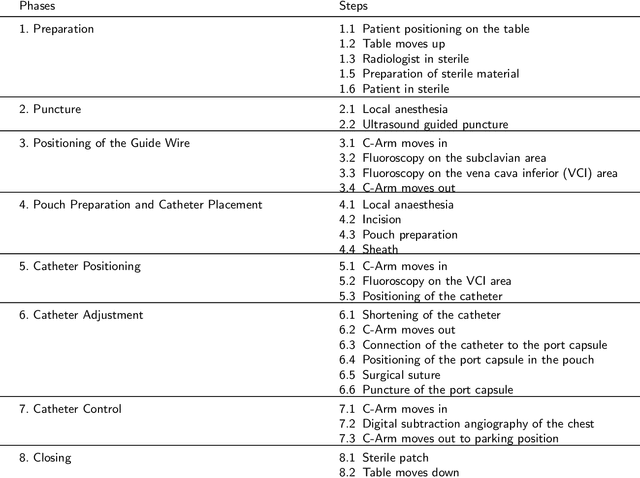
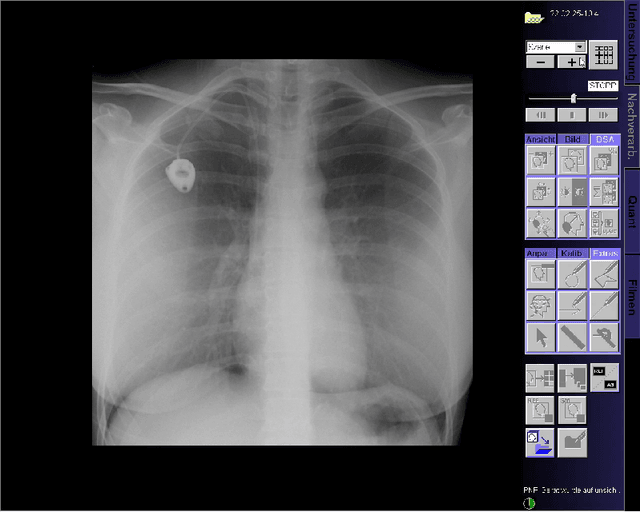

This paper presents a new multimodal interventional radiology dataset, called PoCaP (Port Catheter Placement) Corpus. This corpus consists of speech and audio signals in German, X-ray images, and system commands collected from 31 PoCaP interventions by six surgeons with average duration of 81.4 $\pm$ 41.0 minutes. The corpus aims to provide a resource for developing a smart speech assistant in operating rooms. In particular, it may be used to develop a speech controlled system that enables surgeons to control the operation parameters such as C-arm movements and table positions. In order to record the dataset, we acquired consent by the institutional review board and workers council in the University Hospital Erlangen and by the patients for data privacy. We describe the recording set-up, data structure, workflow and preprocessing steps, and report the first PoCaP Corpus speech recognition analysis results with 11.52 $\%$ word error rate using pretrained models. The findings suggest that the data has the potential to build a robust command recognition system and will allow the development of a novel intervention support systems using speech and image processing in the medical domain.
Inference of the Selective Auditory Attention using Sequential LMMSE Estimation
Feb 02, 2021



Attentive listening in a multispeaker environment such as a cocktail party requires suppression of the interfering speakers and the noise around. People with normal hearing perform remarkably well in such situations. Analysis of the cortical signals using electroencephalography (EEG) has revealed that the EEG signals track the envelope of the attended speech stronger than that of the interfering speech. This has enabled the development of algorithms that can decode the selective attention of a listener in controlled experimental settings. However, often these algorithms require longer trial duration and computationally expensive calibration to obtain a reliable inference of attention. In this paper, we present a novel framework to decode the attention of a listener within trial durations of the order of two seconds. It comprises of three modules: 1) Dynamic estimation of the temporal response functions (TRF) in every trial using a sequential linear minimum mean squared error (LMMSE) estimator, 2) Extract the N1-P2 peak of the estimated TRF that serves as a marker related to the attentional state and 3) Obtain a probabilistic measure of the attentional state using a support vector machine followed by a logistic regression. The efficacy of the proposed decoding framework was evaluated using EEG data collected from 27 subjects. The total number of electrodes required to infer the attention was four: One for the signal estimation, one for the noise estimation and the other two being the reference and the ground electrodes. Our results make further progress towards the realization of neuro-steered hearing aids.