 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigher-Order Spectra and their Unbiased Estimation in the GPU-accelerated SignalSnap Library
May 02, 2025The analysis of time-dependent data poses a fundamental challenge in many fields of science and engineering. While concepts for higher-order spectral analysis like Brillinger's polyspectra for stationary processes have long been introduced, their applications have been limited probably due to high computational cost and complexity of implementation. Here we discuss the theoretical background of estimating polyspectra with our open-source GPU-accelerated SignaSnap library and highlight its advantages over previous implementations: (i) The calculation of spectra is unprecedentedly based on unbiased and consistent estimators that suppress the appearance of false structures in fourth-order spectra. (ii) SignalSnap implements cross-correlation spectra for up to four channels. (iii) The spectral estimates of SignalSnap have a clear relation to Brillinger's definition of ideal spectra of continuous stochastic processes in terms of amplitude and spectral resolution. (iv) SignalSnap estimates the variance of each spectral value. We show how polyspectra reveal, e.g., the correlations between different channels or the breaking of time-inversion symmetry and discuss how quasi-polyspectra uncover the non-stationarity of signals.
Filter2Noise: Interpretable Self-Supervised Single-Image Denoising for Low-Dose CT with Attention-Guided Bilateral Filtering
Apr 18, 2025Effective denoising is crucial in low-dose CT to enhance subtle structures and low-contrast lesions while preventing diagnostic errors. Supervised methods struggle with limited paired datasets, and self-supervised approaches often require multiple noisy images and rely on deep networks like U-Net, offering little insight into the denoising mechanism. To address these challenges, we propose an interpretable self-supervised single-image denoising framework -- Filter2Noise (F2N). Our approach introduces an Attention-Guided Bilateral Filter that adapted to each noisy input through a lightweight module that predicts spatially varying filter parameters, which can be visualized and adjusted post-training for user-controlled denoising in specific regions of interest. To enable single-image training, we introduce a novel downsampling shuffle strategy with a new self-supervised loss function that extends the concept of Noise2Noise to a single image and addresses spatially correlated noise. On the Mayo Clinic 2016 low-dose CT dataset, F2N outperforms the leading self-supervised single-image method (ZS-N2N) by 4.59 dB PSNR while improving transparency, user control, and parametric efficiency. These features provide key advantages for medical applications that require precise and interpretable noise reduction. Our code is demonstrated at https://github.com/sypsyp97/Filter2Noise.git .
CyclePose -- Leveraging Cycle-Consistency for Annotation-Free Nuclei Segmentation in Fluorescence Microscopy
Mar 14, 2025In recent years, numerous neural network architectures specifically designed for the instance segmentation of nuclei in microscopic images have been released. These models embed nuclei-specific priors to outperform generic architectures like U-Nets; however, they require large annotated datasets, which are often not available. Generative models (GANs, diffusion models) have been used to compensate for this by synthesizing training data. These two-stage approaches are computationally expensive, as first a generative model and then a segmentation model has to be trained. We propose CyclePose, a hybrid framework integrating synthetic data generation and segmentation training. CyclePose builds on a CycleGAN architecture, which allows unpaired translation between microscopy images and segmentation masks. We embed a segmentation model into CycleGAN and leverage a cycle consistency loss for self-supervision. Without annotated data, CyclePose outperforms other weakly or unsupervised methods on two public datasets. Code is available at https://github.com/jonasutz/CyclePose
DiffRenderGAN: Addressing Training Data Scarcity in Deep Segmentation Networks for Quantitative Nanomaterial Analysis through Differentiable Rendering and Generative Modelling
Feb 13, 2025Nanomaterials exhibit distinctive properties governed by parameters such as size, shape, and surface characteristics, which critically influence their applications and interactions across technological, biological, and environmental contexts. Accurate quantification and understanding of these materials are essential for advancing research and innovation. In this regard, deep learning segmentation networks have emerged as powerful tools that enable automated insights and replace subjective methods with precise quantitative analysis. However, their efficacy depends on representative annotated datasets, which are challenging to obtain due to the costly imaging of nanoparticles and the labor-intensive nature of manual annotations. To overcome these limitations, we introduce DiffRenderGAN, a novel generative model designed to produce annotated synthetic data. By integrating a differentiable renderer into a Generative Adversarial Network (GAN) framework, DiffRenderGAN optimizes textural rendering parameters to generate realistic, annotated nanoparticle images from non-annotated real microscopy images. This approach reduces the need for manual intervention and enhances segmentation performance compared to existing synthetic data methods by generating diverse and realistic data. Tested on multiple ion and electron microscopy cases, including titanium dioxide (TiO$_2$), silicon dioxide (SiO$_2$)), and silver nanowires (AgNW), DiffRenderGAN bridges the gap between synthetic and real data, advancing the quantification and understanding of complex nanomaterial systems.
On the Influence of Smoothness Constraints in Computed Tomography Motion Compensation
May 29, 2024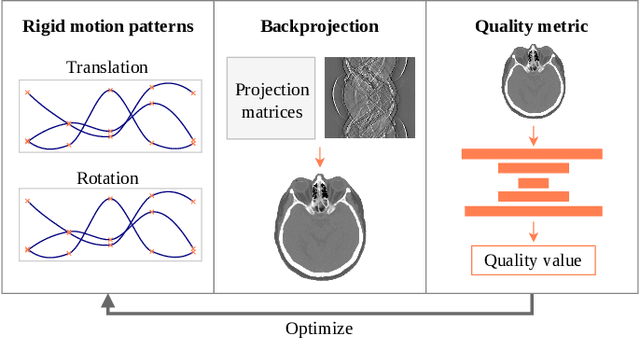
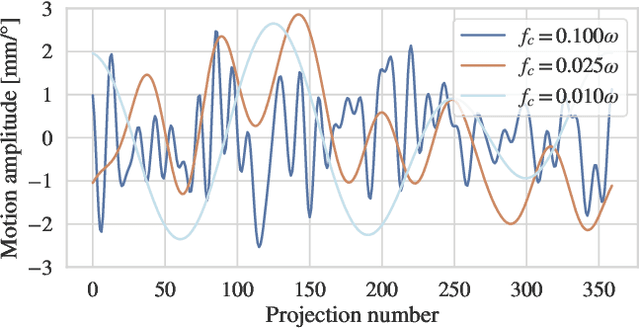
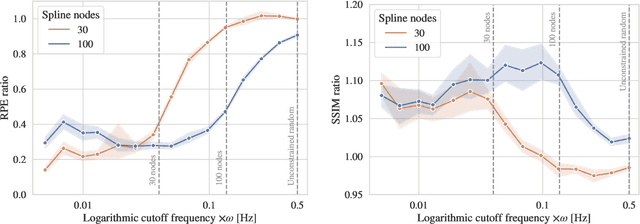
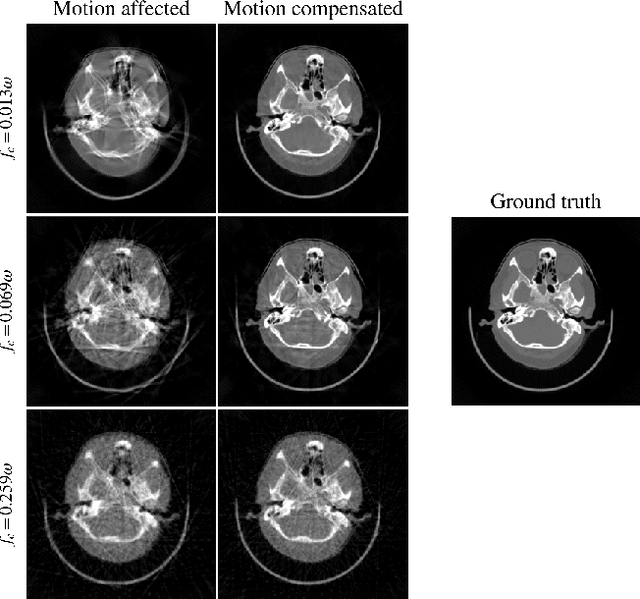
Computed tomography (CT) relies on precise patient immobilization during image acquisition. Nevertheless, motion artifacts in the reconstructed images can persist. Motion compensation methods aim to correct such artifacts post-acquisition, often incorporating temporal smoothness constraints on the estimated motion patterns. This study analyzes the influence of a spline-based motion model within an existing rigid motion compensation algorithm for cone-beam CT on the recoverable motion frequencies. Results demonstrate that the choice of motion model crucially influences recoverable frequencies. The optimization-based motion compensation algorithm is able to accurately fit the spline nodes for frequencies almost up to the node-dependent theoretical limit according to the Nyquist-Shannon theorem. Notably, a higher node count does not compromise reconstruction performance for slow motion patterns, but can extend the range of recoverable high frequencies for the investigated algorithm. Eventually, the optimal motion model is dependent on the imaged anatomy, clinical use case, and scanning protocol and should be tailored carefully to the expected motion frequency spectrum to ensure accurate motion compensation.
Differentiable Score-Based Likelihoods: Learning CT Motion Compensation From Clean Images
Apr 23, 2024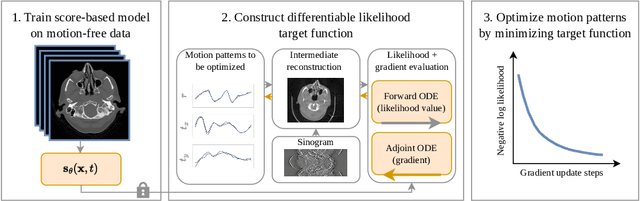
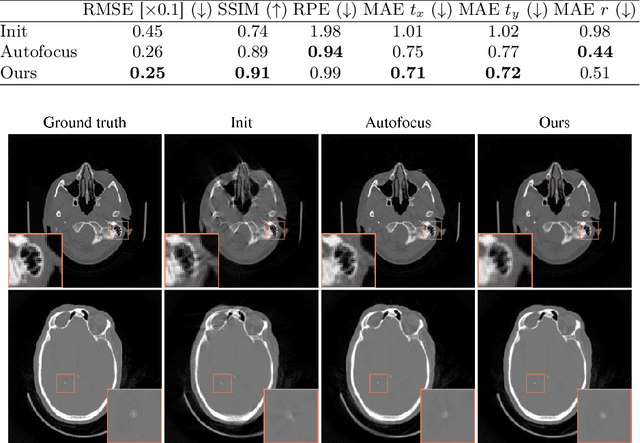
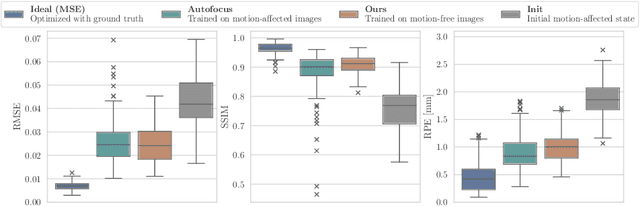
Motion artifacts can compromise the diagnostic value of computed tomography (CT) images. Motion correction approaches require a per-scan estimation of patient-specific motion patterns. In this work, we train a score-based model to act as a probability density estimator for clean head CT images. Given the trained model, we quantify the deviation of a given motion-affected CT image from the ideal distribution through likelihood computation. We demonstrate that the likelihood can be utilized as a surrogate metric for motion artifact severity in the CT image facilitating the application of an iterative, gradient-based motion compensation algorithm. By optimizing the underlying motion parameters to maximize likelihood, our method effectively reduces motion artifacts, bringing the image closer to the distribution of motion-free scans. Our approach achieves comparable performance to state-of-the-art methods while eliminating the need for a representative data set of motion-affected samples. This is particularly advantageous in real-world applications, where patient motion patterns may exhibit unforeseen variability, ensuring robustness without implicit assumptions about recoverable motion types.
Reference-Free Multi-Modality Volume Registration of X-Ray Microscopy and Light-Sheet Fluorescence Microscopy
Apr 23, 2024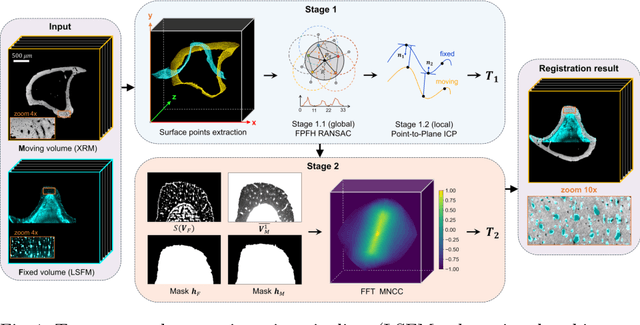
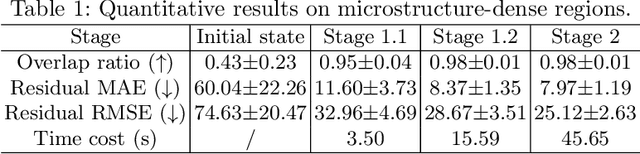
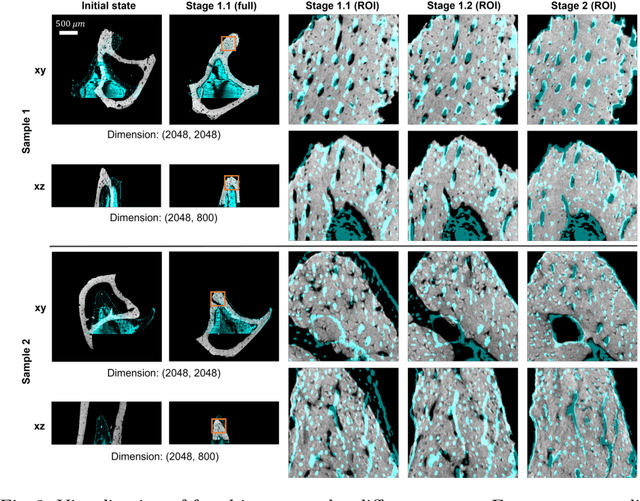
Recently, X-ray microscopy (XRM) and light-sheet fluorescence microscopy (LSFM) have emerged as two pivotal imaging tools in preclinical research on bone remodeling diseases, offering micrometer-level resolution. Integrating these complementary modalities provides a holistic view of bone microstructures, facilitating function-oriented volume analysis across different disease cycles. However, registering such independently acquired large-scale volumes is extremely challenging under real and reference-free scenarios. This paper presents a fast two-stage pipeline for volume registration of XRM and LSFM. The first stage extracts the surface features and employs two successive point cloud-based methods for coarse alignment. The second stage fine-tunes the initial alignment using a modified cross-correlation method, ensuring precise volumetric registration. Moreover, we propose residual similarity as a novel metric to assess the alignment of two complementary modalities. The results imply robust gradual improvement across the stages. In the end, all correlating microstructures, particularly lacunae in XRM and bone cells in LSFM, are precisely matched, enabling new insights into bone diseases like osteoporosis which are a substantial burden in aging societies.
Segmentation-Guided Knee Radiograph Generation using Conditional Diffusion Models
Apr 04, 2024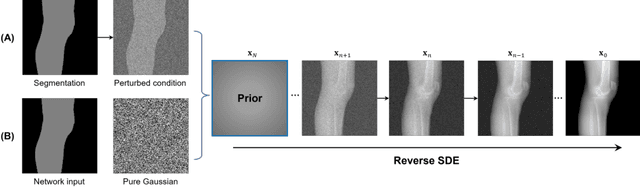
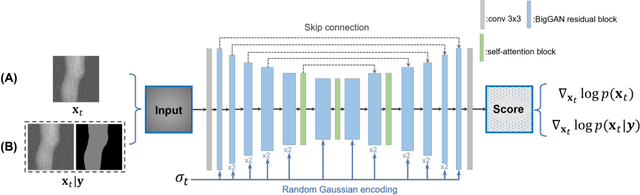
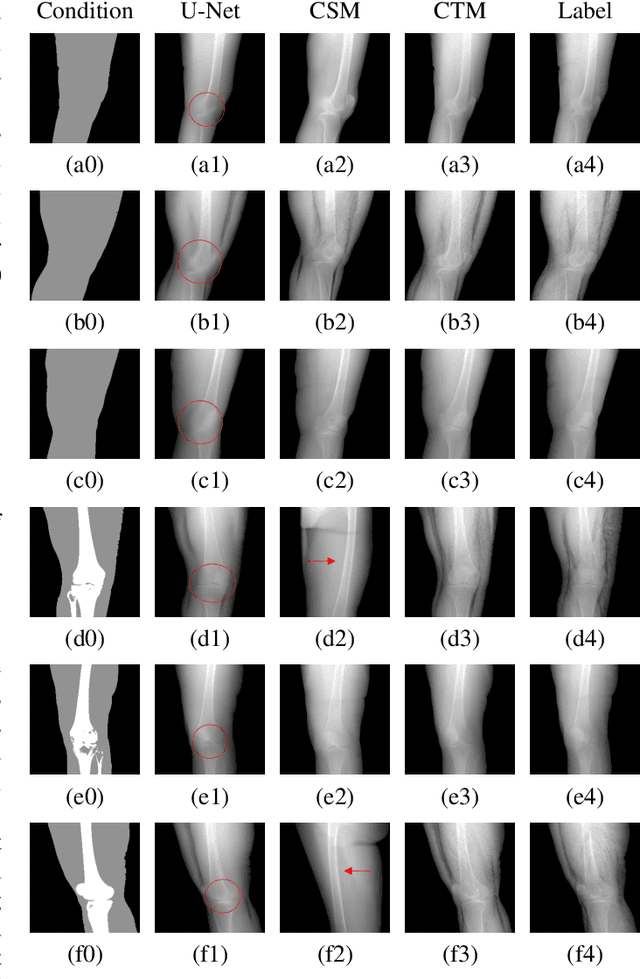
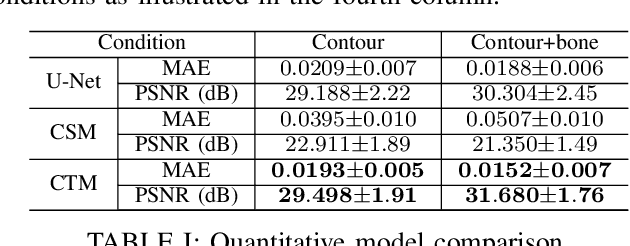
Deep learning-based medical image processing algorithms require representative data during development. In particular, surgical data might be difficult to obtain, and high-quality public datasets are limited. To overcome this limitation and augment datasets, a widely adopted solution is the generation of synthetic images. In this work, we employ conditional diffusion models to generate knee radiographs from contour and bone segmentations. Remarkably, two distinct strategies are presented by incorporating the segmentation as a condition into the sampling and training process, namely, conditional sampling and conditional training. The results demonstrate that both methods can generate realistic images while adhering to the conditioning segmentation. The conditional training method outperforms the conditional sampling method and the conventional U-Net.
Physics-Informed Learning for Time-Resolved Angiographic Contrast Agent Concentration Reconstruction
Mar 04, 2024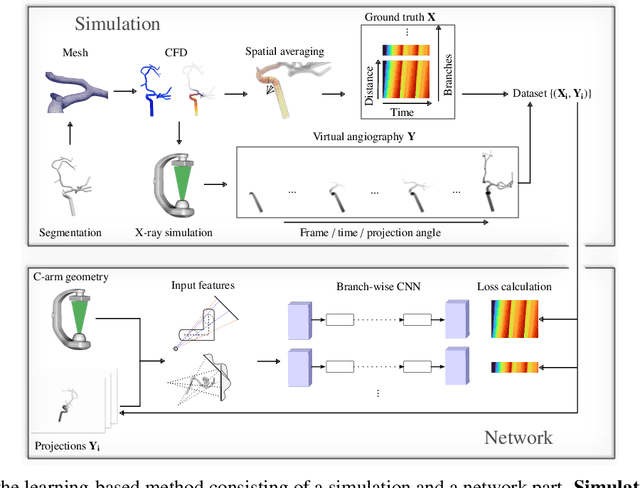
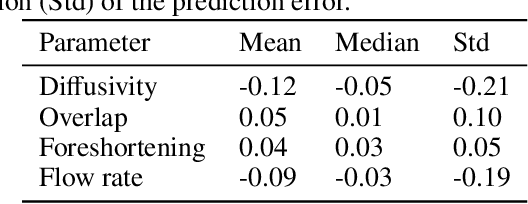
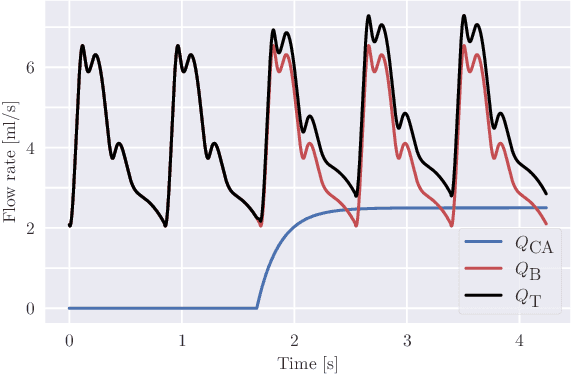
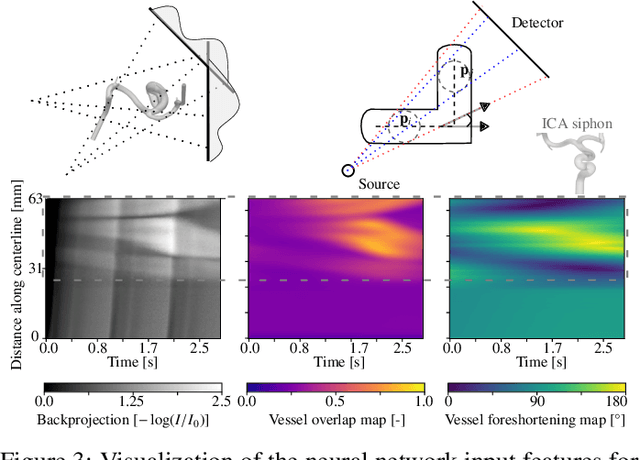
Three-dimensional Digital Subtraction Angiography (3D-DSA) is a well-established X-ray-based technique for visualizing vascular anatomy. Recently, four-dimensional DSA (4D-DSA) reconstruction algorithms have been developed to enable the visualization of volumetric contrast flow dynamics through time-series of volumes. . This reconstruction problem is ill-posed mainly due to vessel overlap in the projection direction and geometric vessel foreshortening, which leads to information loss in the recorded projection images. However, knowledge about the underlying fluid dynamics can be leveraged to constrain the solution space. In our work, we implicitly include this information in a neural network-based model that is trained on a dataset of image-based blood flow simulations. The model predicts the spatially averaged contrast agent concentration for each centerline point of the vasculature over time, lowering the overall computational demand. The trained network enables the reconstruction of relative contrast agent concentrations with a mean absolute error of 0.02 $\pm$ 0.02 and a mean absolute percentage error of 5.31 % $\pm$ 9.25 %. Moreover, the network is robust to varying degrees of vessel overlap and vessel foreshortening. Our approach demonstrates the potential of the integration of machine learning and blood flow simulations in time-resolved angiographic flow reconstruction.
A gradient-based approach to fast and accurate head motion compensation in cone-beam CT
Jan 17, 2024Cone-beam computed tomography (CBCT) systems, with their portability, present a promising avenue for direct point-of-care medical imaging, particularly in critical scenarios such as acute stroke assessment. However, the integration of CBCT into clinical workflows faces challenges, primarily linked to long scan duration resulting in patient motion during scanning and leading to image quality degradation in the reconstructed volumes. This paper introduces a novel approach to CBCT motion estimation using a gradient-based optimization algorithm, which leverages generalized derivatives of the backprojection operator for cone-beam CT geometries. Building on that, a fully differentiable target function is formulated which grades the quality of the current motion estimate in reconstruction space. We drastically accelerate motion estimation yielding a 19-fold speed-up compared to existing methods. Additionally, we investigate the architecture of networks used for quality metric regression and propose predicting voxel-wise quality maps, favoring autoencoder-like architectures over contracting ones. This modification improves gradient flow, leading to more accurate motion estimation. The presented method is evaluated through realistic experiments on head anatomy. It achieves a reduction in reprojection error from an initial average of 3mm to 0.61mm after motion compensation and consistently demonstrates superior performance compared to existing approaches. The analytic Jacobian for the backprojection operation, which is at the core of the proposed method, is made publicly available. In summary, this paper contributes to the advancement of CBCT integration into clinical workflows by proposing a robust motion estimation approach that enhances efficiency and accuracy, addressing critical challenges in time-sensitive scenarios.