 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Influence of Smoothness Constraints in Computed Tomography Motion Compensation
May 29, 2024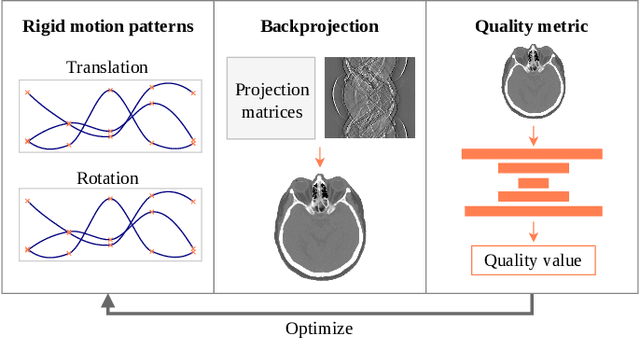
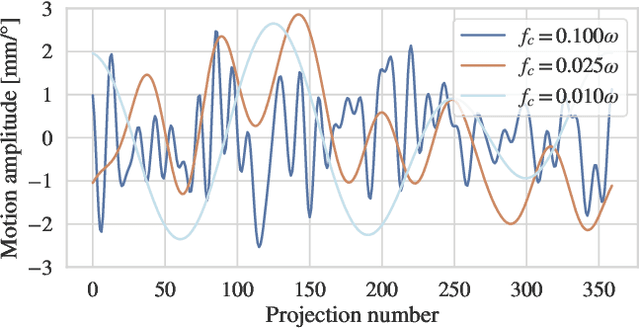
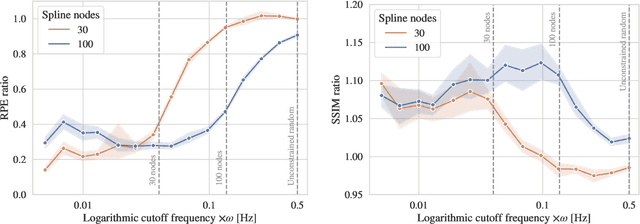
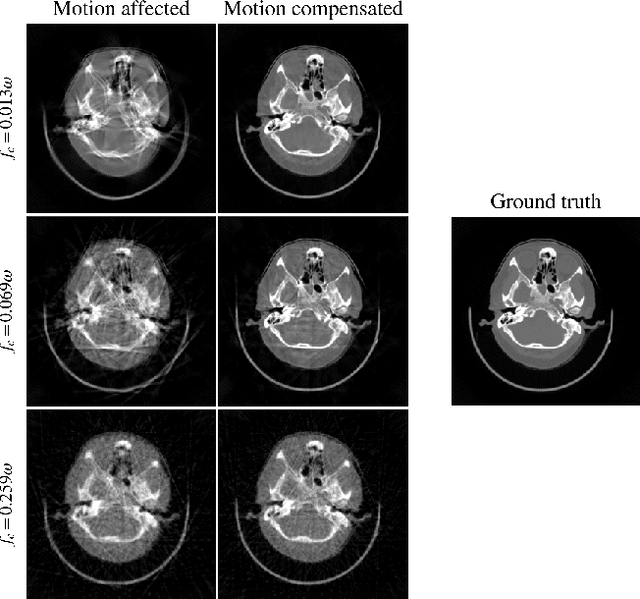
Computed tomography (CT) relies on precise patient immobilization during image acquisition. Nevertheless, motion artifacts in the reconstructed images can persist. Motion compensation methods aim to correct such artifacts post-acquisition, often incorporating temporal smoothness constraints on the estimated motion patterns. This study analyzes the influence of a spline-based motion model within an existing rigid motion compensation algorithm for cone-beam CT on the recoverable motion frequencies. Results demonstrate that the choice of motion model crucially influences recoverable frequencies. The optimization-based motion compensation algorithm is able to accurately fit the spline nodes for frequencies almost up to the node-dependent theoretical limit according to the Nyquist-Shannon theorem. Notably, a higher node count does not compromise reconstruction performance for slow motion patterns, but can extend the range of recoverable high frequencies for the investigated algorithm. Eventually, the optimal motion model is dependent on the imaged anatomy, clinical use case, and scanning protocol and should be tailored carefully to the expected motion frequency spectrum to ensure accurate motion compensation.
Differentiable Score-Based Likelihoods: Learning CT Motion Compensation From Clean Images
Apr 23, 2024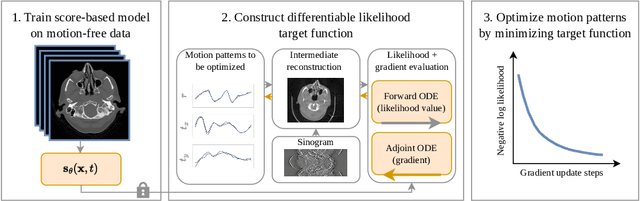
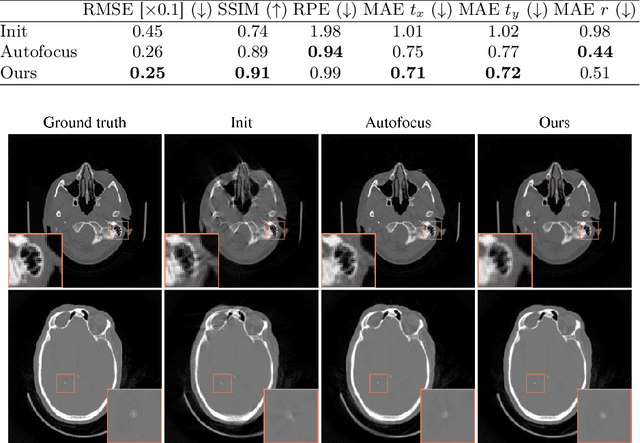
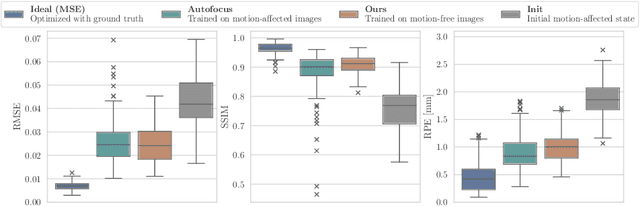
Motion artifacts can compromise the diagnostic value of computed tomography (CT) images. Motion correction approaches require a per-scan estimation of patient-specific motion patterns. In this work, we train a score-based model to act as a probability density estimator for clean head CT images. Given the trained model, we quantify the deviation of a given motion-affected CT image from the ideal distribution through likelihood computation. We demonstrate that the likelihood can be utilized as a surrogate metric for motion artifact severity in the CT image facilitating the application of an iterative, gradient-based motion compensation algorithm. By optimizing the underlying motion parameters to maximize likelihood, our method effectively reduces motion artifacts, bringing the image closer to the distribution of motion-free scans. Our approach achieves comparable performance to state-of-the-art methods while eliminating the need for a representative data set of motion-affected samples. This is particularly advantageous in real-world applications, where patient motion patterns may exhibit unforeseen variability, ensuring robustness without implicit assumptions about recoverable motion types.
Optimizing CT Scan Geometries With and Without Gradients
Feb 13, 2023In computed tomography (CT), the projection geometry used for data acquisition needs to be known precisely to obtain a clear reconstructed image. Rigid patient motion is a cause for misalignment between measured data and employed geometry. Commonly, such motion is compensated by solving an optimization problem that, e.g., maximizes the quality of the reconstructed image with respect to the projection geometry. So far, gradient-free optimization algorithms have been utilized to find the solution for this problem. Here, we show that gradient-based optimization algorithms are a possible alternative and compare the performance to their gradient-free counterparts on a benchmark motion compensation problem. Gradient-based algorithms converge substantially faster while being comparable to gradient-free algorithms in terms of capture range and robustness to the number of free parameters. Hence, gradient-based optimization is a viable alternative for the given type of problems.
Geometric Constraints Enable Self-Supervised Sinogram Inpainting in Sparse-View Tomography
Feb 13, 2023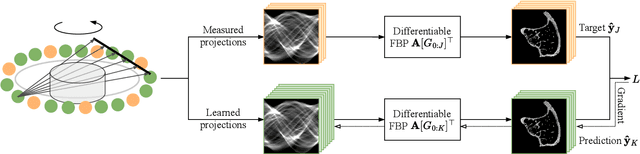
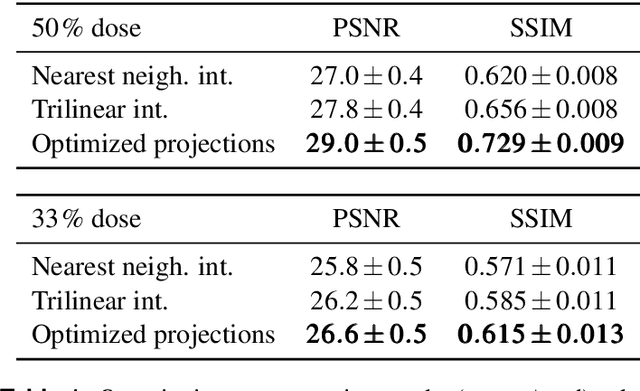
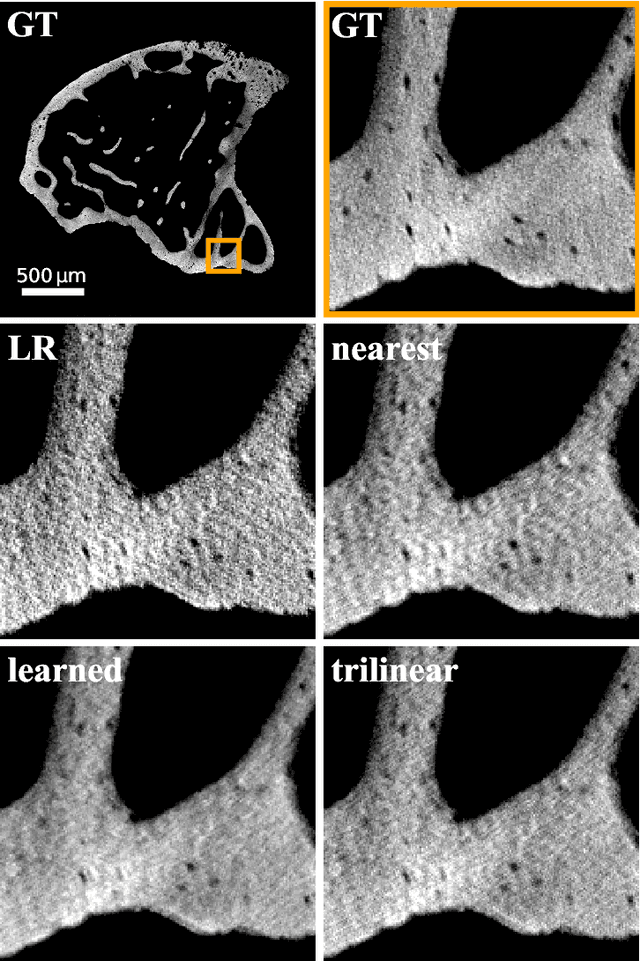
The diagnostic quality of computed tomography (CT) scans is usually restricted by the induced patient dose, scan speed, and image quality. Sparse-angle tomographic scans reduce radiation exposure and accelerate data acquisition, but suffer from image artifacts and noise. Existing image processing algorithms can restore CT reconstruction quality but often require large training data sets or can not be used for truncated objects. This work presents a self-supervised projection inpainting method that allows learning missing projective views via gradient-based optimization. By reconstructing independent stacks of projection data, a self-supervised loss is calculated in the CT image domain and used to directly optimize projection image intensities to match the missing tomographic views constrained by the projection geometry. Our experiments on real X-ray microscope (XRM) tomographic mouse tibia bone scans show that our method improves reconstructions by 3.1-7.4%/7.7-17.6% in terms of PSNR/SSIM with respect to the interpolation baseline. Our approach is applicable as a flexible self-supervised projection inpainting tool for tomographic applications.
Transient Hemodynamics Prediction Using an Efficient Octree-Based Deep Learning Model
Feb 13, 2023
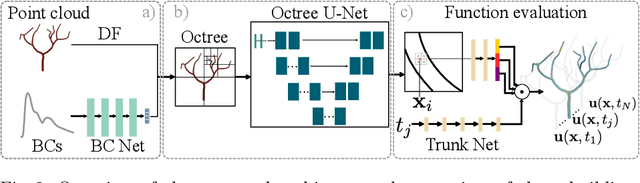
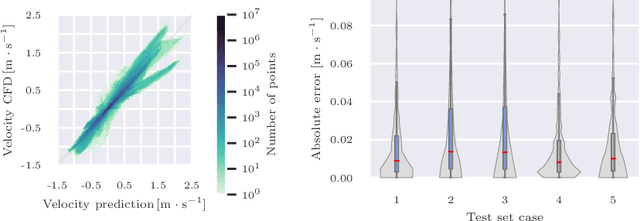
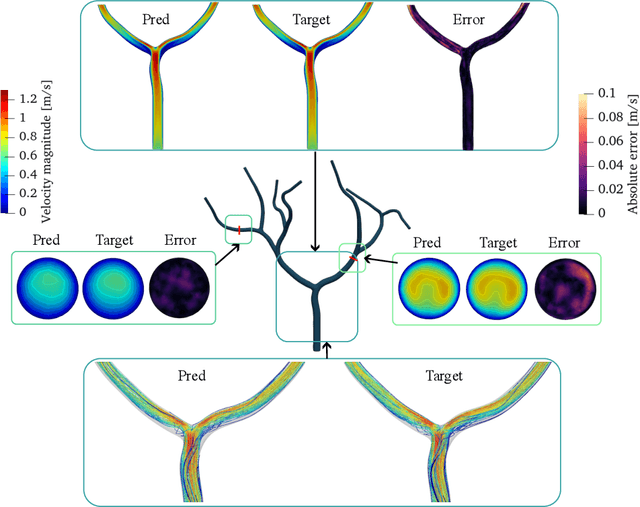
Patient-specific hemodynamics assessment could support diagnosis and treatment of neurovascular diseases. Currently, conventional medical imaging modalities are not able to accurately acquire high-resolution hemodynamic information that would be required to assess complex neurovascular pathologies. Therefore, computational fluid dynamics (CFD) simulations can be applied to tomographic reconstructions to obtain clinically relevant information. However, three-dimensional (3D) CFD simulations require enormous computational resources and simulation-related expert knowledge that are usually not available in clinical environments. Recently, deep-learning-based methods have been proposed as CFD surrogates to improve computational efficiency. Nevertheless, the prediction of high-resolution transient CFD simulations for complex vascular geometries poses a challenge to conventional deep learning models. In this work, we present an architecture that is tailored to predict high-resolution (spatial and temporal) velocity fields for complex synthetic vascular geometries. For this, an octree-based spatial discretization is combined with an implicit neural function representation to efficiently handle the prediction of the 3D velocity field for each time step. The presented method is evaluated for the task of cerebral hemodynamics prediction before and during the injection of contrast agent in the internal carotid artery (ICA). Compared to CFD simulations, the velocity field can be estimated with a mean absolute error of 0.024 m/s, whereas the run time reduces from several hours on a high-performance cluster to a few seconds on a consumer graphical processing unit.
Noise2Contrast: Multi-Contrast Fusion Enables Self-Supervised Tomographic Image Denoising
Dec 09, 2022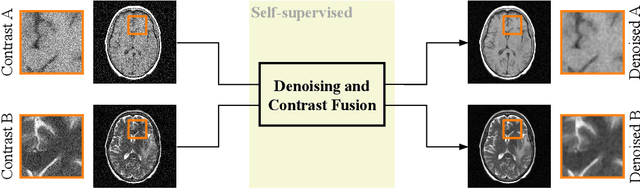
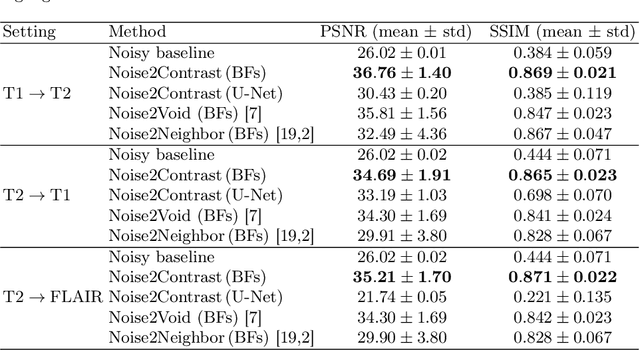
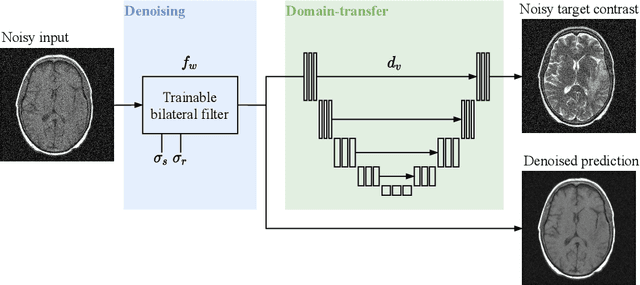

Self-supervised image denoising techniques emerged as convenient methods that allow training denoising models without requiring ground-truth noise-free data. Existing methods usually optimize loss metrics that are calculated from multiple noisy realizations of similar images, e.g., from neighboring tomographic slices. However, those approaches fail to utilize the multiple contrasts that are routinely acquired in medical imaging modalities like MRI or dual-energy CT. In this work, we propose the new self-supervised training scheme Noise2Contrast that combines information from multiple measured image contrasts to train a denoising model. We stack denoising with domain-transfer operators to utilize the independent noise realizations of different image contrasts to derive a self-supervised loss. The trained denoising operator achieves convincing quantitative and qualitative results, outperforming state-of-the-art self-supervised methods by 4.7-11.0%/4.8-7.3% (PSNR/SSIM) on brain MRI data and by 43.6-50.5%/57.1-77.1% (PSNR/SSIM) on dual-energy CT X-ray microscopy data with respect to the noisy baseline. Our experiments on different real measured data sets indicate that Noise2Contrast training generalizes to other multi-contrast imaging modalities.
Gradient-Based Geometry Learning for Fan-Beam CT Reconstruction
Dec 05, 2022Incorporating computed tomography (CT) reconstruction operators into differentiable pipelines has proven beneficial in many applications. Such approaches usually focus on the projection data and keep the acquisition geometry fixed. However, precise knowledge of the acquisition geometry is essential for high quality reconstruction results. In this paper, the differentiable formulation of fan-beam CT reconstruction is extended to the acquisition geometry. This allows to propagate gradient information from a loss function on the reconstructed image into the geometry parameters. As a proof-of-concept experiment, this idea is applied to rigid motion compensation. The cost function is parameterized by a trained neural network which regresses an image quality metric from the motion affected reconstruction alone. Using the proposed method, we are the first to optimize such an autofocus-inspired algorithm based on analytical gradients. The algorithm achieves a reduction in MSE by 35.5 % and an improvement in SSIM by 12.6 % over the motion affected reconstruction. Next to motion compensation, we see further use cases of our differentiable method for scanner calibration or hybrid techniques employing deep models.
On the Benefit of Dual-domain Denoising in a Self-supervised Low-dose CT Setting
Nov 03, 2022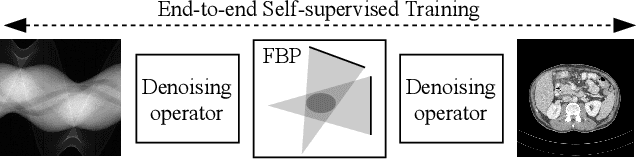
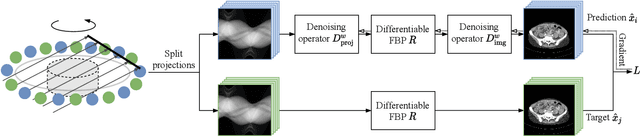
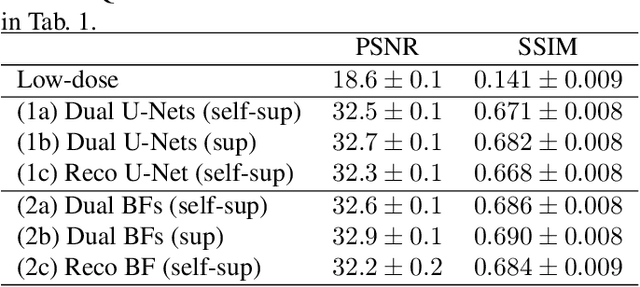
Computed tomography (CT) is routinely used for three-dimensional non-invasive imaging. Numerous data-driven image denoising algorithms were proposed to restore image quality in low-dose acquisitions. However, considerably less research investigates methods already intervening in the raw detector data due to limited access to suitable projection data or correct reconstruction algorithms. In this work, we present an end-to-end trainable CT reconstruction pipeline that contains denoising operators in both the projection and the image domain and that are optimized simultaneously without requiring ground-truth high-dose CT data. Our experiments demonstrate that including an additional projection denoising operator improved the overall denoising performance by 82.4-94.1%/12.5-41.7% (PSNR/SSIM) on abdomen CT and 1.5-2.9%/0.4-0.5% (PSNR/SSIM) on XRM data relative to the low-dose baseline. We make our entire helical CT reconstruction framework publicly available that contains a raw projection rebinning step to render helical projection data suitable for differentiable fan-beam reconstruction operators and end-to-end learning.
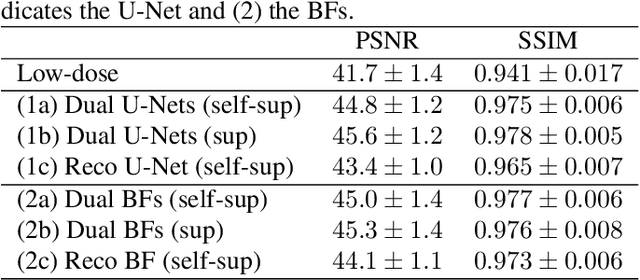
Trainable Joint Bilateral Filters for Enhanced Prediction Stability in Low-dose CT
Jul 15, 2022
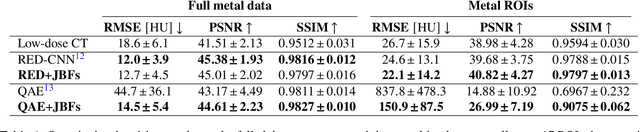

Low-dose computed tomography (CT) denoising algorithms aim to enable reduced patient dose in routine CT acquisitions while maintaining high image quality. Recently, deep learning~(DL)-based methods were introduced, outperforming conventional denoising algorithms on this task due to their high model capacity. However, for the transition of DL-based denoising to clinical practice, these data-driven approaches must generalize robustly beyond the seen training data. We, therefore, propose a hybrid denoising approach consisting of a set of trainable joint bilateral filters (JBFs) combined with a convolutional DL-based denoising network to predict the guidance image. Our proposed denoising pipeline combines the high model capacity enabled by DL-based feature extraction with the reliability of the conventional JBF. The pipeline's ability to generalize is demonstrated by training on abdomen CT scans without metal implants and testing on abdomen scans with metal implants as well as on head CT data. When embedding two well-established DL-based denoisers (RED-CNN/QAE) in our pipeline, the denoising performance is improved by $10\,\%$/$82\,\%$ (RMSE) and $3\,\%$/$81\,\%$ (PSNR) in regions containing metal and by $6\,\%$/$78\,\%$ (RMSE) and $2\,\%$/$4\,\%$ (PSNR) on head CT data, compared to the respective vanilla model. Concluding, the proposed trainable JBFs limit the error bound of deep neural networks to facilitate the applicability of DL-based denoisers in low-dose CT pipelines.