 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbalanced optimal transport for robust longitudinal lesion evolution with registration-aware and appearance-guided priors
Feb 10, 2026Evaluating lesion evolution in longitudinal CT scans of can cer patients is essential for assessing treatment response, yet establishing reliable lesion correspondence across time remains challenging. Standard bipartite matchers, which rely on geometric proximity, struggle when lesions appear, disappear, merge, or split. We propose a registration-aware matcher based on unbalanced optimal transport (UOT) that accommodates unequal lesion mass and adapts priors to patient-level tumor-load changes. Our transport cost blends (i) size-normalized geometry, (ii) local registration trust from the deformation-field Jacobian, and (iii) optional patch-level appearance consistency. The resulting transport plan is sparsified by relative pruning, yielding one-to-one matches as well as new, disappearing, merging, and splitting lesions without retraining or heuristic rules. On longitudinal CT data, our approach achieves consistently higher edge-detection precision and recall, improved lesion-state recall, and superior lesion-graph component F1 scores versus distance-only baselines.
Consistent View Alignment Improves Foundation Models for 3D Medical Image Segmentation
Sep 17, 2025Many recent approaches in representation learning implicitly assume that uncorrelated views of a data point are sufficient to learn meaningful representations for various downstream tasks. In this work, we challenge this assumption and demonstrate that meaningful structure in the latent space does not emerge naturally. Instead, it must be explicitly induced. We propose a method that aligns representations from different views of the data to align complementary information without inducing false positives. Our experiments show that our proposed self-supervised learning method, Consistent View Alignment, improves performance for downstream tasks, highlighting the critical role of structured view alignment in learning effective representations. Our method achieved first and second place in the MICCAI 2025 SSL3D challenge when using a Primus vision transformer and ResEnc convolutional neural network, respectively. The code and pretrained model weights are released at https://github.com/Tenbatsu24/LatentCampus.
Data-Agnostic Augmentations for Unknown Variations: Out-of-Distribution Generalisation in MRI Segmentation
May 15, 2025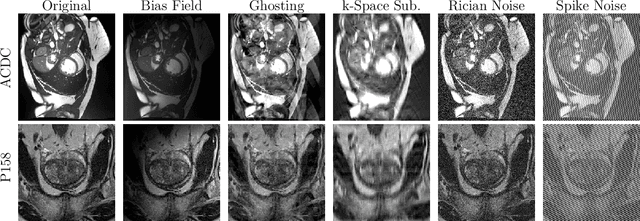
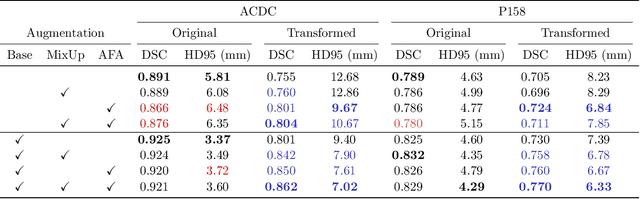
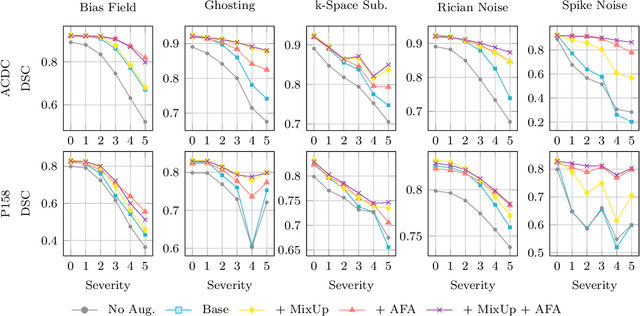
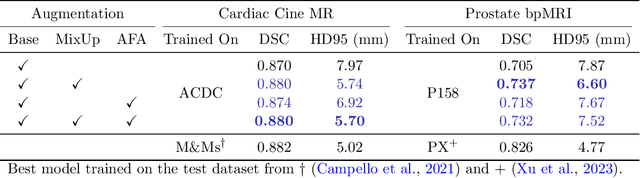
Medical image segmentation models are often trained on curated datasets, leading to performance degradation when deployed in real-world clinical settings due to mismatches between training and test distributions. While data augmentation techniques are widely used to address these challenges, traditional visually consistent augmentation strategies lack the robustness needed for diverse real-world scenarios. In this work, we systematically evaluate alternative augmentation strategies, focusing on MixUp and Auxiliary Fourier Augmentation. These methods mitigate the effects of multiple variations without explicitly targeting specific sources of distribution shifts. We demonstrate how these techniques significantly improve out-of-distribution generalization and robustness to imaging variations across a wide range of transformations in cardiac cine MRI and prostate MRI segmentation. We quantitatively find that these augmentation methods enhance learned feature representations by promoting separability and compactness. Additionally, we highlight how their integration into nnU-Net training pipelines provides an easy-to-implement, effective solution for enhancing the reliability of medical segmentation models in real-world applications.
Fusion of Domain-Adapted Vision and Language Models for Medical Visual Question Answering
Apr 24, 2024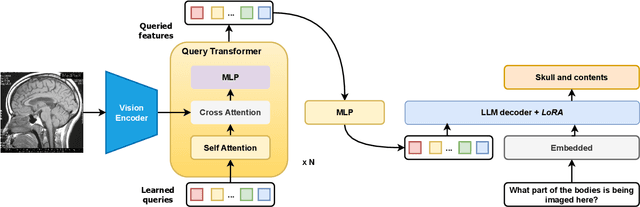



Vision-language models, while effective in general domains and showing strong performance in diverse multi-modal applications like visual question-answering (VQA), struggle to maintain the same level of effectiveness in more specialized domains, e.g., medical. We propose a medical vision-language model that integrates large vision and language models adapted for the medical domain. This model goes through three stages of parameter-efficient training using three separate biomedical and radiology multi-modal visual and text datasets. The proposed model achieves state-of-the-art performance on the SLAKE 1.0 medical VQA (MedVQA) dataset with an overall accuracy of 87.5% and demonstrates strong performance on another MedVQA dataset, VQA-RAD, achieving an overall accuracy of 73.2%.
Adaptive Region Selection for Active Learning in Whole Slide Image Semantic Segmentation
Jul 14, 2023



The process of annotating histological gigapixel-sized whole slide images (WSIs) at the pixel level for the purpose of training a supervised segmentation model is time-consuming. Region-based active learning (AL) involves training the model on a limited number of annotated image regions instead of requesting annotations of the entire images. These annotation regions are iteratively selected, with the goal of optimizing model performance while minimizing the annotated area. The standard method for region selection evaluates the informativeness of all square regions of a specified size and then selects a specific quantity of the most informative regions. We find that the efficiency of this method highly depends on the choice of AL step size (i.e., the combination of region size and the number of selected regions per WSI), and a suboptimal AL step size can result in redundant annotation requests or inflated computation costs. This paper introduces a novel technique for selecting annotation regions adaptively, mitigating the reliance on this AL hyperparameter. Specifically, we dynamically determine each region by first identifying an informative area and then detecting its optimal bounding box, as opposed to selecting regions of a uniform predefined shape and size as in the standard method. We evaluate our method using the task of breast cancer metastases segmentation on the public CAMELYON16 dataset and show that it consistently achieves higher sampling efficiency than the standard method across various AL step sizes. With only 2.6\% of tissue area annotated, we achieve full annotation performance and thereby substantially reduce the costs of annotating a WSI dataset. The source code is available at https://github.com/DeepMicroscopy/AdaptiveRegionSelection.
End-to-end Learning for Image-based Detection of Molecular Alterations in Digital Pathology
Jun 30, 2022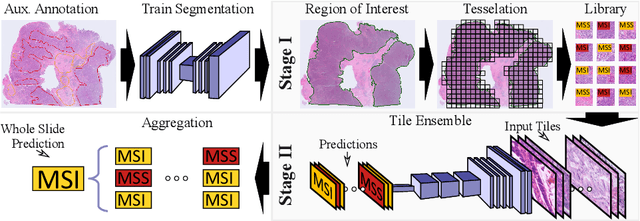
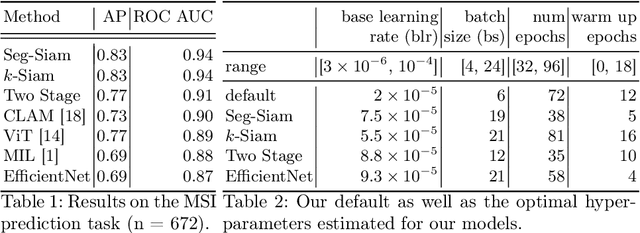
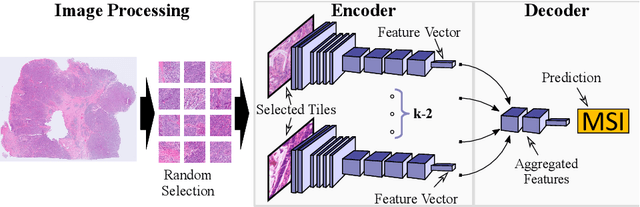
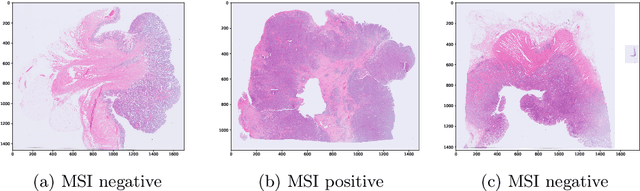
Current approaches for classification of whole slide images (WSI) in digital pathology predominantly utilize a two-stage learning pipeline. The first stage identifies areas of interest (e.g. tumor tissue), while the second stage processes cropped tiles from these areas in a supervised fashion. During inference, a large number of tiles are combined into a unified prediction for the entire slide. A major drawback of such approaches is the requirement for task-specific auxiliary labels which are not acquired in clinical routine. We propose a novel learning pipeline for WSI classification that is trainable end-to-end and does not require any auxiliary annotations. We apply our approach to predict molecular alterations for a number of different use-cases, including detection of microsatellite instability in colorectal tumors and prediction of specific mutations for colon, lung, and breast cancer cases from The Cancer Genome Atlas. Results reach AUC scores of up to 94% and are shown to be competitive with state of the art two-stage pipelines. We believe our approach can facilitate future research in digital pathology and contribute to solve a large range of problems around the prediction of cancer phenotypes, hopefully enabling personalized therapies for more patients in future.