 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Based Agentic Systems for Software Engineering: Challenges and Opportunities
Jan 14, 2026Despite recent advancements in Large Language Models (LLMs), complex Software Engineering (SE) tasks require more collaborative and specialized approaches. This concept paper systematically reviews the emerging paradigm of LLM-based multi-agent systems, examining their applications across the Software Development Life Cycle (SDLC), from requirements engineering and code generation to static code checking, testing, and debugging. We delve into a wide range of topics such as language model selection, SE evaluation benchmarks, state-of-the-art agentic frameworks and communication protocols. Furthermore, we identify key challenges and outline future research opportunities, with a focus on multi-agent orchestration, human-agent coordination, computational cost optimization, and effective data collection. This work aims to provide researchers and practitioners with valuable insights into the current forefront landscape of agentic systems within the software engineering domain.
The Few-shot Dilemma: Over-prompting Large Language Models
Sep 16, 2025Over-prompting, a phenomenon where excessive examples in prompts lead to diminished performance in Large Language Models (LLMs), challenges the conventional wisdom about in-context few-shot learning. To investigate this few-shot dilemma, we outline a prompting framework that leverages three standard few-shot selection methods - random sampling, semantic embedding, and TF-IDF vectors - and evaluate these methods across multiple LLMs, including GPT-4o, GPT-3.5-turbo, DeepSeek-V3, Gemma-3, LLaMA-3.1, LLaMA-3.2, and Mistral. Our experimental results reveal that incorporating excessive domain-specific examples into prompts can paradoxically degrade performance in certain LLMs, which contradicts the prior empirical conclusion that more relevant few-shot examples universally benefit LLMs. Given the trend of LLM-assisted software engineering and requirement analysis, we experiment with two real-world software requirement classification datasets. By gradually increasing the number of TF-IDF-selected and stratified few-shot examples, we identify their optimal quantity for each LLM. This combined approach achieves superior performance with fewer examples, avoiding the over-prompting problem, thus surpassing the state-of-the-art by 1% in classifying functional and non-functional requirements.
Is Q-learning an Ill-posed Problem?
Feb 21, 2025This paper investigates the instability of Q-learning in continuous environments, a challenge frequently encountered by practitioners. Traditionally, this instability is attributed to bootstrapping and regression model errors. Using a representative reinforcement learning benchmark, we systematically examine the effects of bootstrapping and model inaccuracies by incrementally eliminating these potential error sources. Our findings reveal that even in relatively simple benchmarks, the fundamental task of Q-learning - iteratively learning a Q-function from policy-specific target values - can be inherently ill-posed and prone to failure. These insights cast doubt on the reliability of Q-learning as a universal solution for reinforcement learning problems.
Conceptual In-Context Learning and Chain of Concepts: Solving Complex Conceptual Problems Using Large Language Models
Dec 19, 2024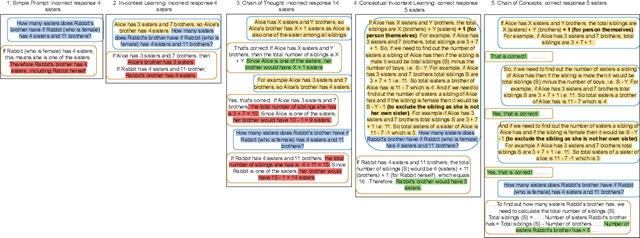
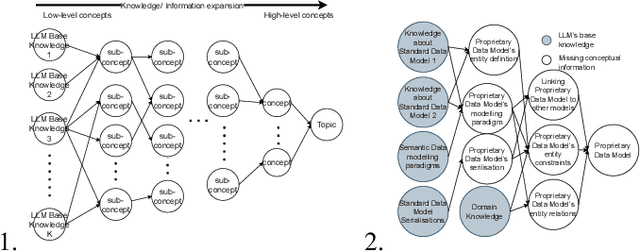

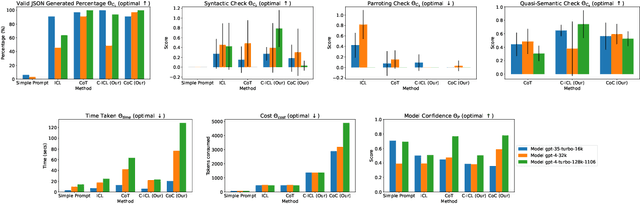
Science and engineering problems fall in the category of complex conceptual problems that require specific conceptual information (CI) like math/logic -related know-how, process information, or engineering guidelines to solve them. Large Language Models (LLMs) are promising agents to solve such complex conceptual problems due to their implications in advancing engineering and science tasks like assisted problem-solving. But vanilla LLMs, trained on open-world data, lack the necessary CI. In this work, we specifically explore shallow customization methods (SCMs) of LLMs for solving complex conceptual problems. We propose two novel SCM algorithms for LLM, to augment LLMs with CI and enable LLMs to solve complex conceptual problems: Conceptual In-Context Learning (C-ICL) and Chain of Concepts (CoC). The problem tackled in this paper is generation of proprietary data models in the engineering/industry domain based on conceptual information in data modelling guidelines. We evaluate our algorithms on varied sizes of the OpenAI LLMs against four evaluation metrics related to syntactic and semantic correctness, time and cost incurred. The proposed algorithms perform better than currently popular LLM SCMs like In-context Learning (ICL) and Chain of Thoughts (CoT). It was observed that as compared to CoT, response correctness increased by 30.6% and 29.88% for the new SCMs C-ICL and CoC respectively. Qualitative analysis suggests that the proposed new SCMs activate emergent capabilities in LLMs, previously unobserved in the existing SCMs. They make problem-solving processes more transparent and reduce hallucinations and the tendency of model responses to copy examples from prompts (parroting).
FsPONER: Few-shot Prompt Optimization for Named Entity Recognition in Domain-specific Scenarios
Jul 10, 2024

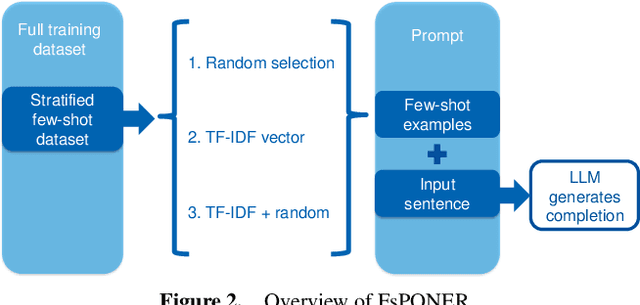

Large Language Models (LLMs) have provided a new pathway for Named Entity Recognition (NER) tasks. Compared with fine-tuning, LLM-powered prompting methods avoid the need for training, conserve substantial computational resources, and rely on minimal annotated data. Previous studies have achieved comparable performance to fully supervised BERT-based fine-tuning approaches on general NER benchmarks. However, none of the previous approaches has investigated the efficiency of LLM-based few-shot learning in domain-specific scenarios. To address this gap, we introduce FsPONER, a novel approach for optimizing few-shot prompts, and evaluate its performance on domain-specific NER datasets, with a focus on industrial manufacturing and maintenance, while using multiple LLMs -- GPT-4-32K, GPT-3.5-Turbo, LLaMA 2-chat, and Vicuna. FsPONER consists of three few-shot selection methods based on random sampling, TF-IDF vectors, and a combination of both. We compare these methods with a general-purpose GPT-NER method as the number of few-shot examples increases and evaluate their optimal NER performance against fine-tuned BERT and LLaMA 2-chat. In the considered real-world scenarios with data scarcity, FsPONER with TF-IDF surpasses fine-tuned models by approximately 10% in F1 score.
Fusion of Domain-Adapted Vision and Language Models for Medical Visual Question Answering
Apr 24, 2024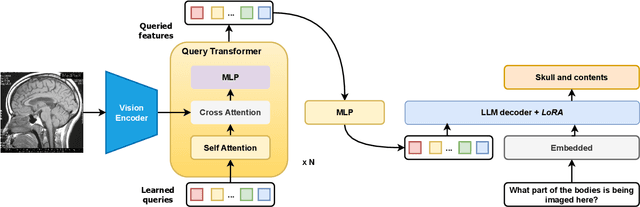



Vision-language models, while effective in general domains and showing strong performance in diverse multi-modal applications like visual question-answering (VQA), struggle to maintain the same level of effectiveness in more specialized domains, e.g., medical. We propose a medical vision-language model that integrates large vision and language models adapted for the medical domain. This model goes through three stages of parameter-efficient training using three separate biomedical and radiology multi-modal visual and text datasets. The proposed model achieves state-of-the-art performance on the SLAKE 1.0 medical VQA (MedVQA) dataset with an overall accuracy of 87.5% and demonstrates strong performance on another MedVQA dataset, VQA-RAD, achieving an overall accuracy of 73.2%.
Wiki-TabNER:Advancing Table Interpretation Through Named Entity Recognition
Mar 07, 2024



Web tables contain a large amount of valuable knowledge and have inspired tabular language models aimed at tackling table interpretation (TI) tasks. In this paper, we analyse a widely used benchmark dataset for evaluation of TI tasks, particularly focusing on the entity linking task. Our analysis reveals that this dataset is overly simplified, potentially reducing its effectiveness for thorough evaluation and failing to accurately represent tables as they appear in the real-world. To overcome this drawback, we construct and annotate a new more challenging dataset. In addition to introducing the new dataset, we also introduce a novel problem aimed at addressing the entity linking task: named entity recognition within cells. Finally, we propose a prompting framework for evaluating the newly developed large language models (LLMs) on this novel TI task. We conduct experiments on prompting LLMs under various settings, where we use both random and similarity-based selection to choose the examples presented to the models. Our ablation study helps us gain insights into the impact of the few-shot examples. Additionally, we perform qualitative analysis to gain insights into the challenges encountered by the models and to understand the limitations of the proposed dataset.
Automatic Trade-off Adaptation in Offline RL
Jun 16, 2023Recently, offline RL algorithms have been proposed that remain adaptive at runtime. For example, the LION algorithm \cite{lion} provides the user with an interface to set the trade-off between behavior cloning and optimality w.r.t. the estimated return at runtime. Experts can then use this interface to adapt the policy behavior according to their preferences and find a good trade-off between conservatism and performance optimization. Since expert time is precious, we extend the methodology with an autopilot that automatically finds the correct parameterization of the trade-off, yielding a new algorithm which we term AutoLION.
Detection, Explanation and Filtering of Cyber Attacks Combining Symbolic and Sub-Symbolic Methods
Dec 23, 2022



Machine learning (ML) on graph-structured data has recently received deepened interest in the context of intrusion detection in the cybersecurity domain. Due to the increasing amounts of data generated by monitoring tools as well as more and more sophisticated attacks, these ML methods are gaining traction. Knowledge graphs and their corresponding learning techniques such as Graph Neural Networks (GNNs) with their ability to seamlessly integrate data from multiple domains using human-understandable vocabularies, are finding application in the cybersecurity domain. However, similar to other connectionist models, GNNs are lacking transparency in their decision making. This is especially important as there tend to be a high number of false positive alerts in the cybersecurity domain, such that triage needs to be done by domain experts, requiring a lot of man power. Therefore, we are addressing Explainable AI (XAI) for GNNs to enhance trust management by exploring combining symbolic and sub-symbolic methods in the area of cybersecurity that incorporate domain knowledge. We experimented with this approach by generating explanations in an industrial demonstrator system. The proposed method is shown to produce intuitive explanations for alerts for a diverse range of scenarios. Not only do the explanations provide deeper insights into the alerts, but they also lead to a reduction of false positive alerts by 66% and by 93% when including the fidelity metric.
A Metaheuristic Approach for Mining Gradual Patterns
Nov 15, 2022



Swarm intelligence is a discipline that studies the collective behavior that is produced by local interactions of a group of individuals with each other and with their environment. In Computer Science domain, numerous swarm intelligence techniques are applied to optimization problems that seek to efficiently find best solutions within a search space. Gradual pattern mining is another Computer Science field that could benefit from the efficiency of swarm based optimization techniques in the task of finding gradual patterns from a huge search space. A gradual pattern is a rule-based correlation that describes the gradual relationship among the attributes of a data set. For example, given attributes {G,H} of a data set a gradual pattern may take the form: "the less G, the more H". In this paper, we propose a numeric encoding for gradual pattern candidates that we use to define an effective search space. In addition, we present a systematic study of several meta-heuristic optimization techniques as efficient solutions to the problem of finding gradual patterns using our search space.