 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Quantum Circuits in Offline Contextual Bandit Problems
Sep 09, 2025This paper explores the application of variational quantum circuits (VQCs) for solving offline contextual bandit problems in industrial optimization tasks. Using the Industrial Benchmark (IB) environment, we evaluate the performance of quantum regression models against classical models. Our findings demonstrate that quantum models can effectively fit complex reward functions, identify optimal configurations via particle swarm optimization (PSO), and generalize well in noisy and sparse datasets. These results provide a proof of concept for utilizing VQCs in offline contextual bandit problems and highlight their potential in industrial optimization tasks.
From Classical Data to Quantum Advantage -- Quantum Policy Evaluation on Quantum Hardware
Sep 09, 2025Quantum policy evaluation (QPE) is a reinforcement learning (RL) algorithm which is quadratically more efficient than an analogous classical Monte Carlo estimation. It makes use of a direct quantum mechanical realization of a finite Markov decision process, in which the agent and the environment are modeled by unitary operators and exchange states, actions, and rewards in superposition. Previously, the quantum environment has been implemented and parametrized manually for an illustrative benchmark using a quantum simulator. In this paper, we demonstrate how these environment parameters can be learned from a batch of classical observational data through quantum machine learning (QML) on quantum hardware. The learned quantum environment is then applied in QPE to also compute policy evaluations on quantum hardware. Our experiments reveal that, despite challenges such as noise and short coherence times, the integration of QML and QPE shows promising potential for achieving quantum advantage in RL.
Is Q-learning an Ill-posed Problem?
Feb 21, 2025This paper investigates the instability of Q-learning in continuous environments, a challenge frequently encountered by practitioners. Traditionally, this instability is attributed to bootstrapping and regression model errors. Using a representative reinforcement learning benchmark, we systematically examine the effects of bootstrapping and model inaccuracies by incrementally eliminating these potential error sources. Our findings reveal that even in relatively simple benchmarks, the fundamental task of Q-learning - iteratively learning a Q-function from policy-specific target values - can be inherently ill-posed and prone to failure. These insights cast doubt on the reliability of Q-learning as a universal solution for reinforcement learning problems.
Why long model-based rollouts are no reason for bad Q-value estimates
Jul 16, 2024This paper explores the use of model-based offline reinforcement learning with long model rollouts. While some literature criticizes this approach due to compounding errors, many practitioners have found success in real-world applications. The paper aims to demonstrate that long rollouts do not necessarily result in exponentially growing errors and can actually produce better Q-value estimates than model-free methods. These findings can potentially enhance reinforcement learning techniques.
Model-based Offline Quantum Reinforcement Learning
Apr 14, 2024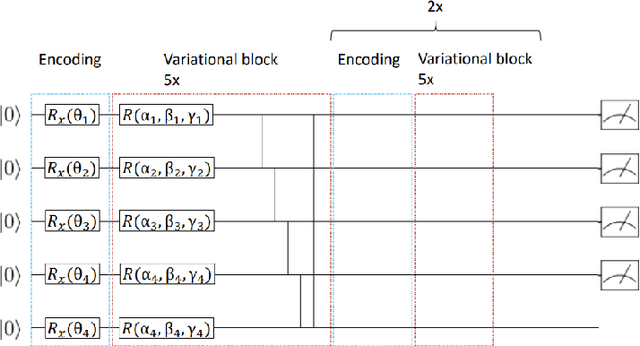
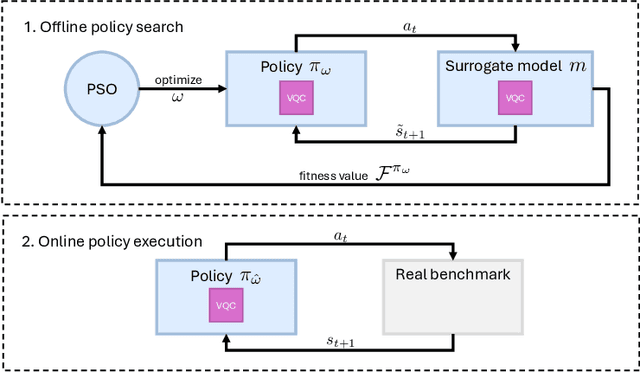
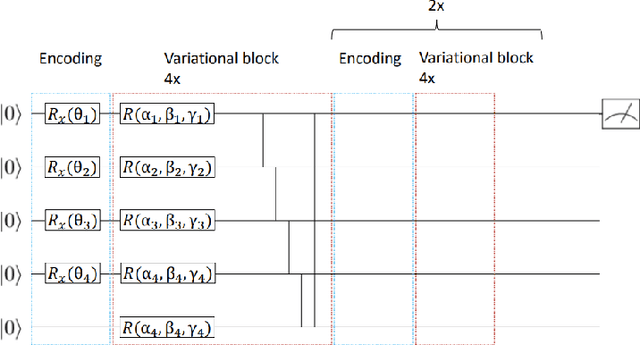
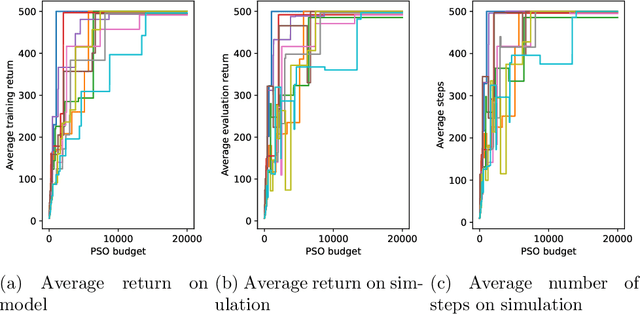
This paper presents the first algorithm for model-based offline quantum reinforcement learning and demonstrates its functionality on the cart-pole benchmark. The model and the policy to be optimized are each implemented as variational quantum circuits. The model is trained by gradient descent to fit a pre-recorded data set. The policy is optimized with a gradient-free optimization scheme using the return estimate given by the model as the fitness function. This model-based approach allows, in principle, full realization on a quantum computer during the optimization phase and gives hope that a quantum advantage can be achieved as soon as sufficiently powerful quantum computers are available.
Learning Control Policies for Variable Objectives from Offline Data
Aug 11, 2023



Offline reinforcement learning provides a viable approach to obtain advanced control strategies for dynamical systems, in particular when direct interaction with the environment is not available. In this paper, we introduce a conceptual extension for model-based policy search methods, called variable objective policy (VOP). With this approach, policies are trained to generalize efficiently over a variety of objectives, which parameterize the reward function. We demonstrate that by altering the objectives passed as input to the policy, users gain the freedom to adjust its behavior or re-balance optimization targets at runtime, without need for collecting additional observation batches or re-training.
Quantum Policy Iteration via Amplitude Estimation and Grover Search -- Towards Quantum Advantage for Reinforcement Learning
Jun 09, 2022
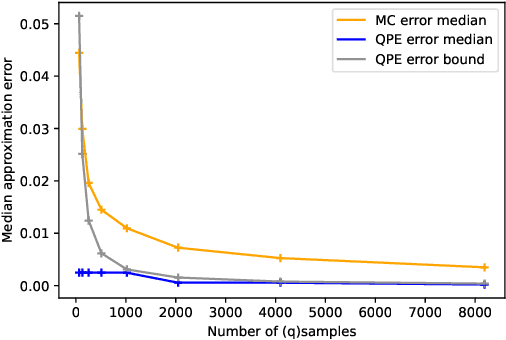
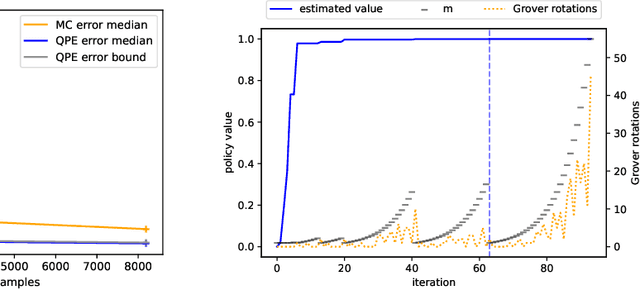
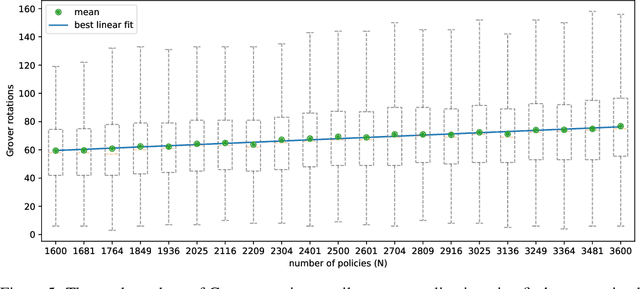
We present a full implementation and simulation of a novel quantum reinforcement learning (RL) method and mathematically prove a quantum advantage. Our approach shows in detail how to combine amplitude estimation and Grover search into a policy evaluation and improvement scheme. We first develop quantum policy evaluation (QPE) which is quadratically more efficient compared to an analogous classical Monte Carlo estimation and is based on a quantum mechanical realization of a finite Markov decision process (MDP). Building on QPE, we derive a quantum policy iteration that repeatedly improves an initial policy using Grover search until the optimum is reached. Finally, we present an implementation of our algorithm for a two-armed bandit MDP which we then simulate. The results confirm that QPE provides a quantum advantage in RL problems.
Comparing Model-free and Model-based Algorithms for Offline Reinforcement Learning
Jan 14, 2022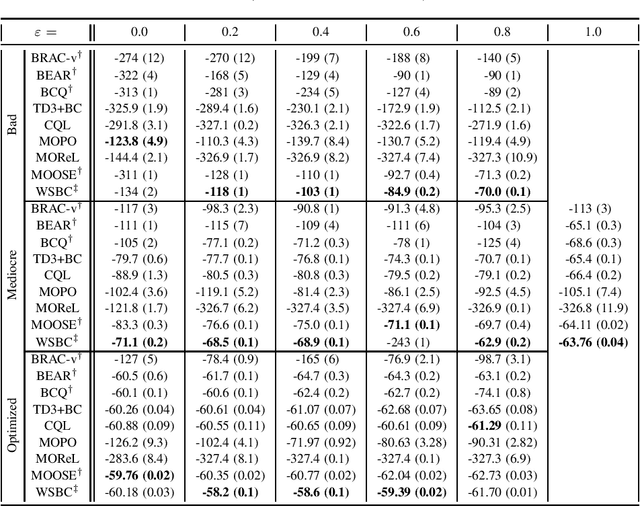
Offline reinforcement learning (RL) Algorithms are often designed with environments such as MuJoCo in mind, in which the planning horizon is extremely long and no noise exists. We compare model-free, model-based, as well as hybrid offline RL approaches on various industrial benchmark (IB) datasets to test the algorithms in settings closer to real world problems, including complex noise and partially observable states. We find that on the IB, hybrid approaches face severe difficulties and that simpler algorithms, such as rollout based algorithms or model-free algorithms with simpler regularizers perform best on the datasets.
Trustworthy AI for Process Automation on a Chylla-Haase Polymerization Reactor
Aug 30, 2021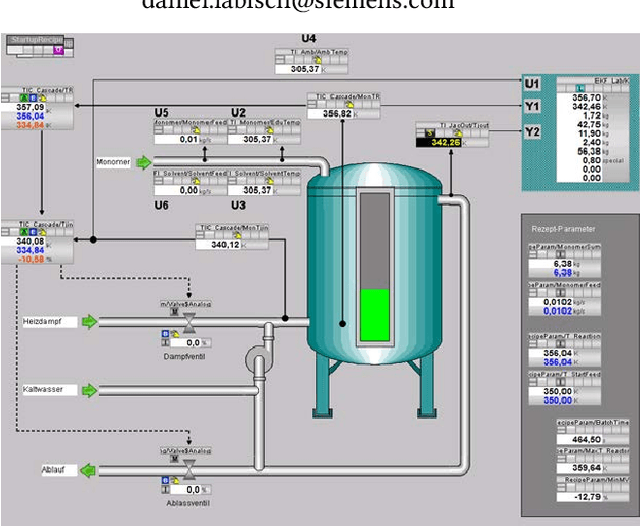
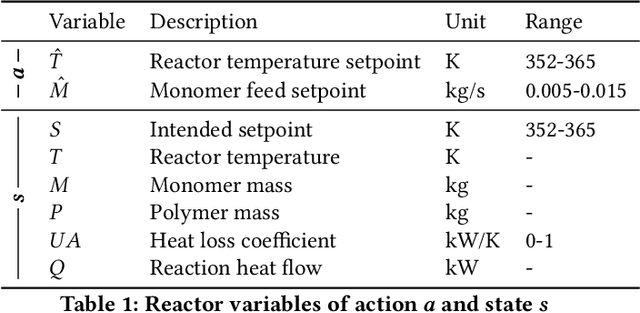

In this paper, genetic programming reinforcement learning (GPRL) is utilized to generate human-interpretable control policies for a Chylla-Haase polymerization reactor. Such continuously stirred tank reactors (CSTRs) with jacket cooling are widely used in the chemical industry, in the production of fine chemicals, pigments, polymers, and medical products. Despite appearing rather simple, controlling CSTRs in real-world applications is quite a challenging problem to tackle. GPRL utilizes already existing data from the reactor and generates fully automatically a set of optimized simplistic control strategies, so-called policies, the domain expert can choose from. Note that these policies are white-box models of low complexity, which makes them easy to validate and implement in the target control system, e.g., SIMATIC PCS 7. However, despite its low complexity the automatically-generated policy yields a high performance in terms of reactor temperature control deviation, which we empirically evaluate on the original reactor template.
Behavior Constraining in Weight Space for Offline Reinforcement Learning
Jul 12, 2021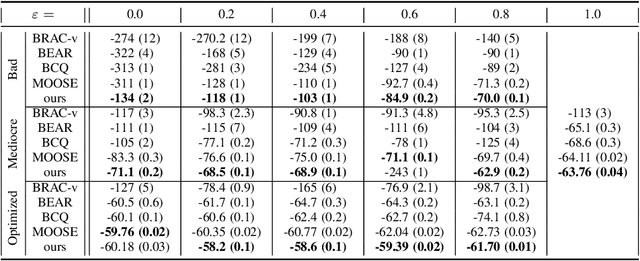

In offline reinforcement learning, a policy needs to be learned from a single pre-collected dataset. Typically, policies are thus regularized during training to behave similarly to the data generating policy, by adding a penalty based on a divergence between action distributions of generating and trained policy. We propose a new algorithm, which constrains the policy directly in its weight space instead, and demonstrate its effectiveness in experiments.