Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavior Constraining in Weight Space for Offline Reinforcement Learning
Paper and Code
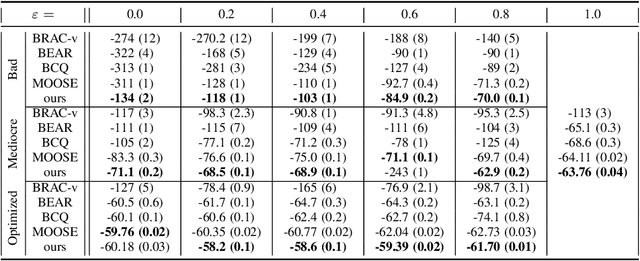

In offline reinforcement learning, a policy needs to be learned from a single pre-collected dataset. Typically, policies are thus regularized during training to behave similarly to the data generating policy, by adding a penalty based on a divergence between action distributions of generating and trained policy. We propose a new algorithm, which constrains the policy directly in its weight space instead, and demonstrate its effectiveness in experiments.
* Accepted at ESANN 2021
View paper on