 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the MEDIQA-OE 2025 Shared Task on Medical Order Extraction from Doctor-Patient Consultations
Oct 30, 2025Clinical documentation increasingly uses automatic speech recognition and summarization, yet converting conversations into actionable medical orders for Electronic Health Records remains unexplored. A solution to this problem can significantly reduce the documentation burden of clinicians and directly impact downstream patient care. We introduce the MEDIQA-OE 2025 shared task, the first challenge on extracting medical orders from doctor-patient conversations. Six teams participated in the shared task and experimented with a broad range of approaches, and both closed- and open-weight large language models (LLMs). In this paper, we describe the MEDIQA-OE task, dataset, final leaderboard ranking, and participants' solutions.
TEA: Trajectory Encoding Augmentation for Robust and Transferable Policies in Offline Reinforcement Learning
Nov 28, 2024
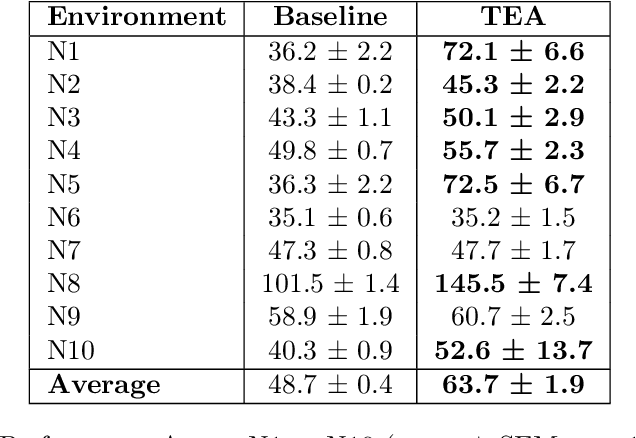
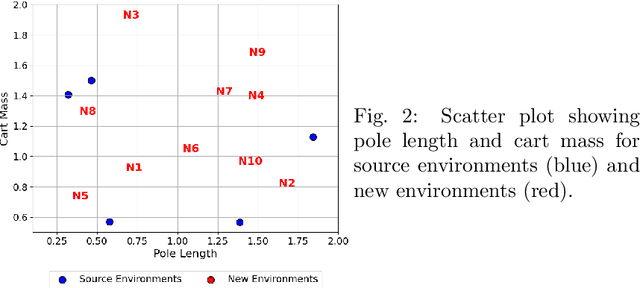
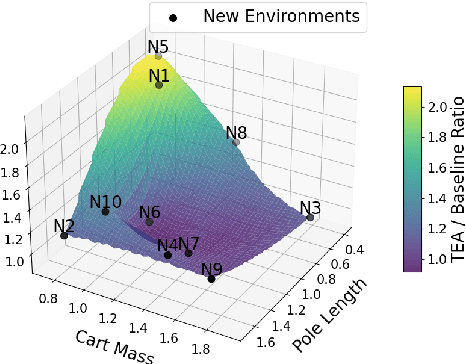
In this paper, we investigate offline reinforcement learning (RL) with the goal of training a single robust policy that generalizes effectively across environments with unseen dynamics. We propose a novel approach, Trajectory Encoding Augmentation (TEA), which extends the state space by integrating latent representations of environmental dynamics obtained from sequence encoders, such as AutoEncoders. Our findings show that incorporating these encodings with TEA improves the transferability of a single policy to novel environments with new dynamics, surpassing methods that rely solely on unmodified states. These results indicate that TEA captures critical, environment-specific characteristics, enabling RL agents to generalize effectively across dynamic conditions.
Iterative Batch Reinforcement Learning via Safe Diversified Model-based Policy Search
Nov 14, 2024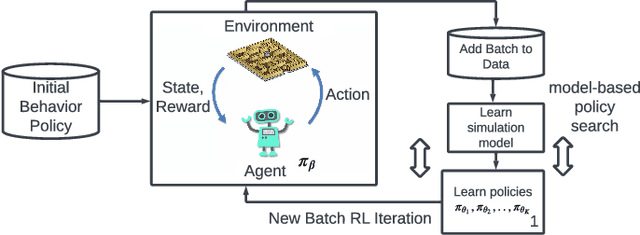
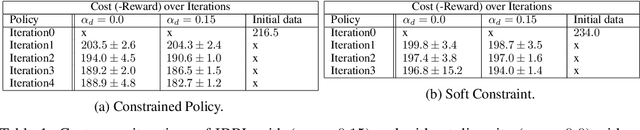
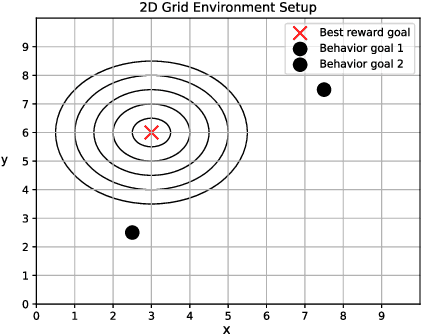

Batch reinforcement learning enables policy learning without direct interaction with the environment during training, relying exclusively on previously collected sets of interactions. This approach is, therefore, well-suited for high-risk and cost-intensive applications, such as industrial control. Learned policies are commonly restricted to act in a similar fashion as observed in the batch. In a real-world scenario, learned policies are deployed in the industrial system, inevitably leading to the collection of new data that can subsequently be added to the existing recording. The process of learning and deployment can thus take place multiple times throughout the lifespan of a system. In this work, we propose to exploit this iterative nature of applying offline reinforcement learning to guide learned policies towards efficient and informative data collection during deployment, leading to continuous improvement of learned policies while remaining within the support of collected data. We present an algorithmic methodology for iterative batch reinforcement learning based on ensemble-based model-based policy search, augmented with safety and, importantly, a diversity criterion.
Learning Control Policies for Variable Objectives from Offline Data
Aug 11, 2023



Offline reinforcement learning provides a viable approach to obtain advanced control strategies for dynamical systems, in particular when direct interaction with the environment is not available. In this paper, we introduce a conceptual extension for model-based policy search methods, called variable objective policy (VOP). With this approach, policies are trained to generalize efficiently over a variety of objectives, which parameterize the reward function. We demonstrate that by altering the objectives passed as input to the policy, users gain the freedom to adjust its behavior or re-balance optimization targets at runtime, without need for collecting additional observation batches or re-training.
Automatic Trade-off Adaptation in Offline RL
Jun 16, 2023Recently, offline RL algorithms have been proposed that remain adaptive at runtime. For example, the LION algorithm \cite{lion} provides the user with an interface to set the trade-off between behavior cloning and optimality w.r.t. the estimated return at runtime. Experts can then use this interface to adapt the policy behavior according to their preferences and find a good trade-off between conservatism and performance optimization. Since expert time is precious, we extend the methodology with an autopilot that automatically finds the correct parameterization of the trade-off, yielding a new algorithm which we term AutoLION.
User-Interactive Offline Reinforcement Learning
May 21, 2022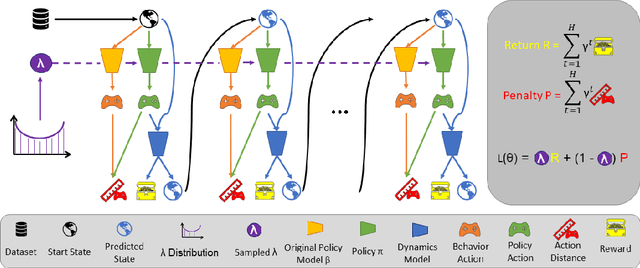



Offline reinforcement learning algorithms still lack trust in practice due to the risk that the learned policy performs worse than the original policy that generated the dataset or behaves in an unexpected way that is unfamiliar to the user. At the same time, offline RL algorithms are not able to tune their most important hyperparameter - the proximity of the learned policy to the original policy. We propose an algorithm that allows the user to tune this hyperparameter at runtime, thereby overcoming both of the above mentioned issues simultaneously. This allows users to start with the original behavior and grant successively greater deviation, as well as stopping at any time when the policy deteriorates or the behavior is too far from the familiar one.
Comparing Model-free and Model-based Algorithms for Offline Reinforcement Learning
Jan 14, 2022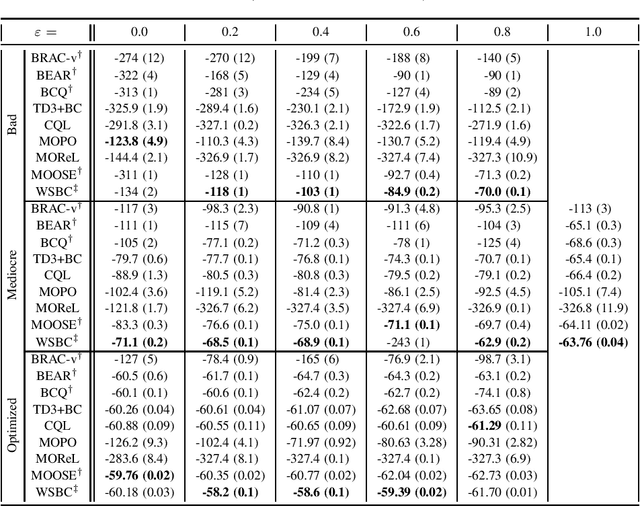
Offline reinforcement learning (RL) Algorithms are often designed with environments such as MuJoCo in mind, in which the planning horizon is extremely long and no noise exists. We compare model-free, model-based, as well as hybrid offline RL approaches on various industrial benchmark (IB) datasets to test the algorithms in settings closer to real world problems, including complex noise and partially observable states. We find that on the IB, hybrid approaches face severe difficulties and that simpler algorithms, such as rollout based algorithms or model-free algorithms with simpler regularizers perform best on the datasets.
Measuring Data Quality for Dataset Selection in Offline Reinforcement Learning
Nov 26, 2021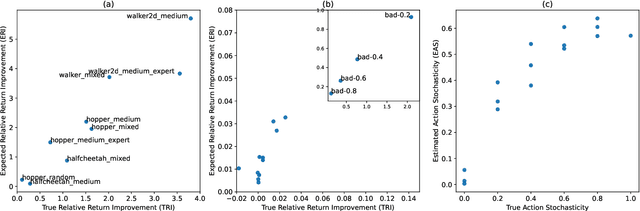
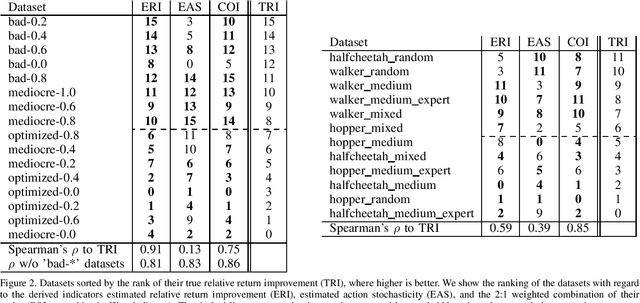
Recently developed offline reinforcement learning algorithms have made it possible to learn policies directly from pre-collected datasets, giving rise to a new dilemma for practitioners: Since the performance the algorithms are able to deliver depends greatly on the dataset that is presented to them, practitioners need to pick the right dataset among the available ones. This problem has so far not been discussed in the corresponding literature. We discuss ideas how to select promising datasets and propose three very simple indicators: Estimated relative return improvement (ERI) and estimated action stochasticity (EAS), as well as a combination of the two (COI), and empirically show that despite their simplicity they can be very effectively used for dataset selection.
Behavior Constraining in Weight Space for Offline Reinforcement Learning
Jul 12, 2021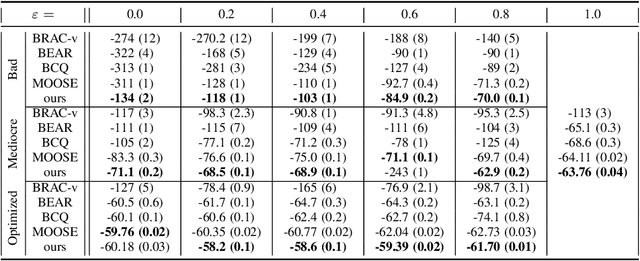

In offline reinforcement learning, a policy needs to be learned from a single pre-collected dataset. Typically, policies are thus regularized during training to behave similarly to the data generating policy, by adding a penalty based on a divergence between action distributions of generating and trained policy. We propose a new algorithm, which constrains the policy directly in its weight space instead, and demonstrate its effectiveness in experiments.
Overcoming Model Bias for Robust Offline Deep Reinforcement Learning
Sep 09, 2020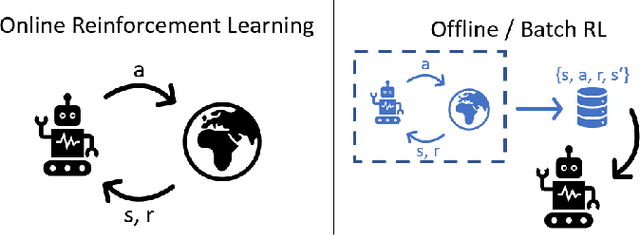

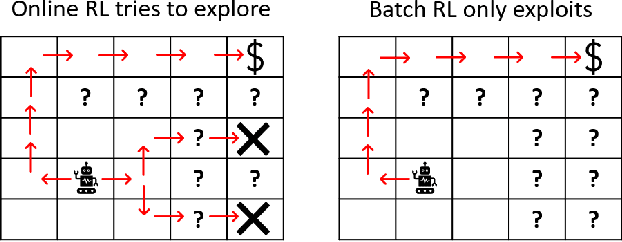
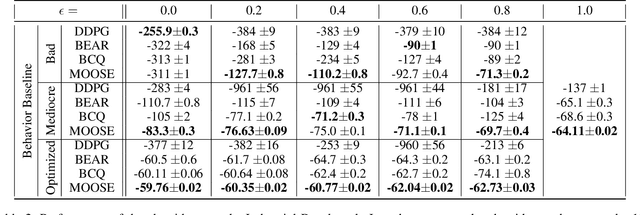
State-of-the-art reinforcement learning algorithms mostly rely on being allowed to directly interact with their environment to collect millions of observations. This makes it hard to transfer their success to industrial control problems, where simulations are often very costly or do not exist, and exploring in the real environment can potentially lead to catastrophic events. Recently developed, model-free, offline algorithms, can learn from a single dataset by mitigating extrapolation error in value functions. However, the robustness of the training process is still comparatively low, a problem known from methods using value functions. To improve robustness and stability of the learning process, we use dynamics models to assess policy performance instead of value functions, resulting in MOOSE (MOdel-based Offline policy Search with Ensembles), an algorithm which ensures low model bias by keeping the policy within the support of the data. We compare MOOSE with state-of-the-art model-free, offline RL algorithms BEAR and BCQ on the Industrial Benchmark and Mujoco continuous control tasks in terms of robust performance, and find that MOOSE outperforms its model-free counterparts in almost all considered cases, often even by far.