 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEA: Trajectory Encoding Augmentation for Robust and Transferable Policies in Offline Reinforcement Learning
Nov 28, 2024
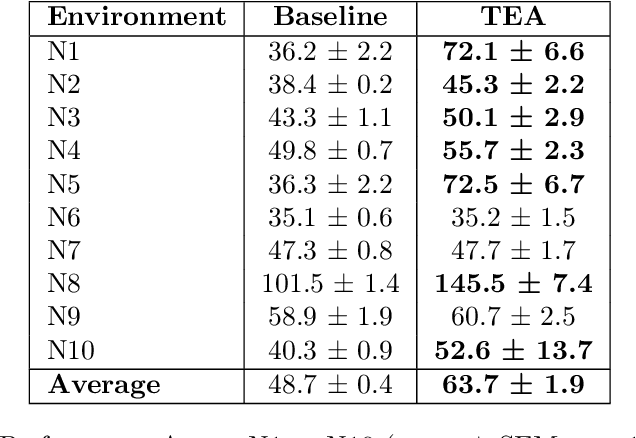
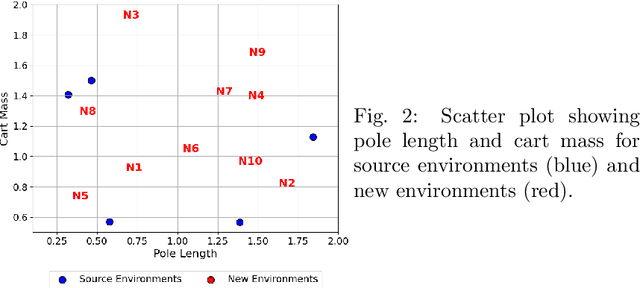
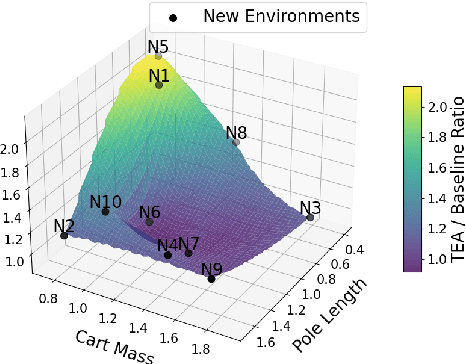
In this paper, we investigate offline reinforcement learning (RL) with the goal of training a single robust policy that generalizes effectively across environments with unseen dynamics. We propose a novel approach, Trajectory Encoding Augmentation (TEA), which extends the state space by integrating latent representations of environmental dynamics obtained from sequence encoders, such as AutoEncoders. Our findings show that incorporating these encodings with TEA improves the transferability of a single policy to novel environments with new dynamics, surpassing methods that rely solely on unmodified states. These results indicate that TEA captures critical, environment-specific characteristics, enabling RL agents to generalize effectively across dynamic conditions.