 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Quantum Circuits in Offline Contextual Bandit Problems
Sep 09, 2025This paper explores the application of variational quantum circuits (VQCs) for solving offline contextual bandit problems in industrial optimization tasks. Using the Industrial Benchmark (IB) environment, we evaluate the performance of quantum regression models against classical models. Our findings demonstrate that quantum models can effectively fit complex reward functions, identify optimal configurations via particle swarm optimization (PSO), and generalize well in noisy and sparse datasets. These results provide a proof of concept for utilizing VQCs in offline contextual bandit problems and highlight their potential in industrial optimization tasks.
TEA: Trajectory Encoding Augmentation for Robust and Transferable Policies in Offline Reinforcement Learning
Nov 28, 2024
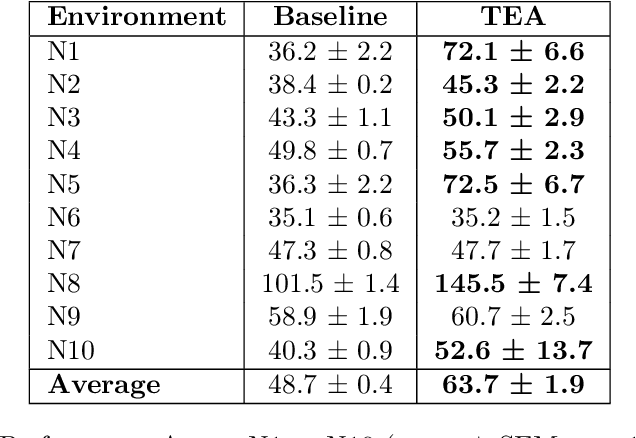
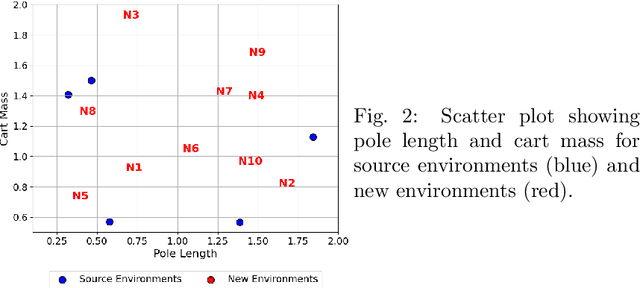
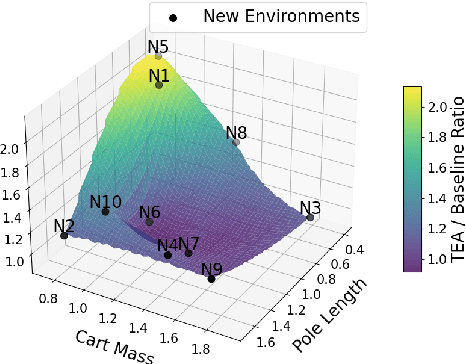
In this paper, we investigate offline reinforcement learning (RL) with the goal of training a single robust policy that generalizes effectively across environments with unseen dynamics. We propose a novel approach, Trajectory Encoding Augmentation (TEA), which extends the state space by integrating latent representations of environmental dynamics obtained from sequence encoders, such as AutoEncoders. Our findings show that incorporating these encodings with TEA improves the transferability of a single policy to novel environments with new dynamics, surpassing methods that rely solely on unmodified states. These results indicate that TEA captures critical, environment-specific characteristics, enabling RL agents to generalize effectively across dynamic conditions.
On-device Online Learning and Semantic Management of TinyML Systems
May 15, 2024Recent advances in Tiny Machine Learning (TinyML) empower low-footprint embedded devices for real-time on-device Machine Learning. While many acknowledge the potential benefits of TinyML, its practical implementation presents unique challenges. This study aims to bridge the gap between prototyping single TinyML models and developing reliable TinyML systems in production: (1) Embedded devices operate in dynamically changing conditions. Existing TinyML solutions primarily focus on inference, with models trained offline on powerful machines and deployed as static objects. However, static models may underperform in the real world due to evolving input data distributions. We propose online learning to enable training on constrained devices, adapting local models towards the latest field conditions. (2) Nevertheless, current on-device learning methods struggle with heterogeneous deployment conditions and the scarcity of labeled data when applied across numerous devices. We introduce federated meta-learning incorporating online learning to enhance model generalization, facilitating rapid learning. This approach ensures optimal performance among distributed devices by knowledge sharing. (3) Moreover, TinyML's pivotal advantage is widespread adoption. Embedded devices and TinyML models prioritize extreme efficiency, leading to diverse characteristics ranging from memory and sensors to model architectures. Given their diversity and non-standardized representations, managing these resources becomes challenging as TinyML systems scale up. We present semantic management for the joint management of models and devices at scale. We demonstrate our methods through a basic regression example and then assess them in three real-world TinyML applications: handwritten character image classification, keyword audio classification, and smart building presence detection, confirming our approaches' effectiveness.
Model-based Offline Quantum Reinforcement Learning
Apr 14, 2024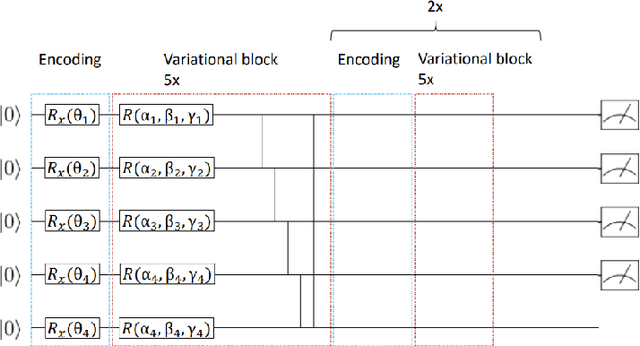
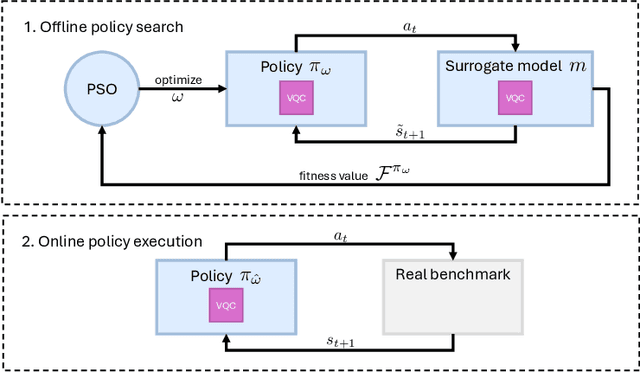
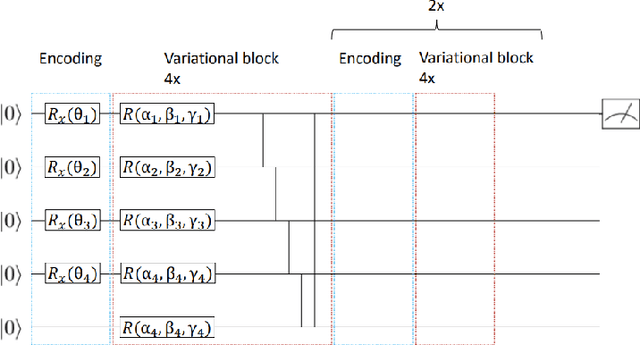
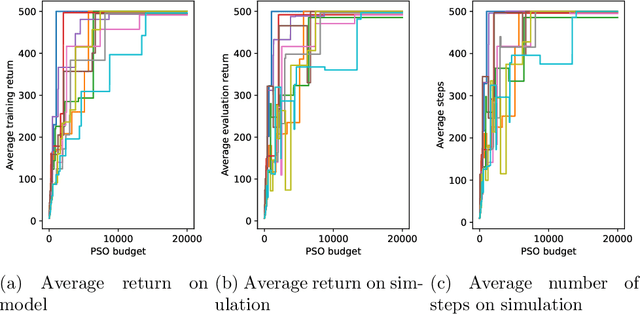
This paper presents the first algorithm for model-based offline quantum reinforcement learning and demonstrates its functionality on the cart-pole benchmark. The model and the policy to be optimized are each implemented as variational quantum circuits. The model is trained by gradient descent to fit a pre-recorded data set. The policy is optimized with a gradient-free optimization scheme using the return estimate given by the model as the fitness function. This model-based approach allows, in principle, full realization on a quantum computer during the optimization phase and gives hope that a quantum advantage can be achieved as soon as sufficiently powerful quantum computers are available.
TinyMetaFed: Efficient Federated Meta-Learning for TinyML
Jul 13, 2023The field of Tiny Machine Learning (TinyML) has made substantial advancements in democratizing machine learning on low-footprint devices, such as microcontrollers. The prevalence of these miniature devices raises the question of whether aggregating their knowledge can benefit TinyML applications. Federated meta-learning is a promising answer to this question, as it addresses the scarcity of labeled data and heterogeneous data distribution across devices in the real world. However, deploying TinyML hardware faces unique resource constraints, making existing methods impractical due to energy, privacy, and communication limitations. We introduce TinyMetaFed, a model-agnostic meta-learning framework suitable for TinyML. TinyMetaFed facilitates collaborative training of a neural network initialization that can be quickly fine-tuned on new devices. It offers communication savings and privacy protection through partial local reconstruction and Top-P% selective communication, computational efficiency via online learning, and robustness to client heterogeneity through few-shot learning. The evaluations on three TinyML use cases demonstrate that TinyMetaFed can significantly reduce energy consumption and communication overhead, accelerate convergence, and stabilize the training process.
TinyReptile: TinyML with Federated Meta-Learning
Apr 11, 2023Tiny machine learning (TinyML) is a rapidly growing field aiming to democratize machine learning (ML) for resource-constrained microcontrollers (MCUs). Given the pervasiveness of these tiny devices, it is inherent to ask whether TinyML applications can benefit from aggregating their knowledge. Federated learning (FL) enables decentralized agents to jointly learn a global model without sharing sensitive local data. However, a common global model may not work for all devices due to the complexity of the actual deployment environment and the heterogeneity of the data available on each device. In addition, the deployment of TinyML hardware has significant computational and communication constraints, which traditional ML fails to address. Considering these challenges, we propose TinyReptile, a simple but efficient algorithm inspired by meta-learning and online learning, to collaboratively learn a solid initialization for a neural network (NN) across tiny devices that can be quickly adapted to a new device with respect to its data. We demonstrate TinyReptile on Raspberry Pi 4 and Cortex-M4 MCU with only 256-KB RAM. The evaluations on various TinyML use cases confirm a resource reduction and training time saving by at least two factors compared with baseline algorithms with comparable performance.
SeLoC-ML: Semantic Low-Code Engineering for Machine Learning Applications in Industrial IoT
Jul 18, 2022



Internet of Things (IoT) is transforming the industry by bridging the gap between Information Technology (IT) and Operational Technology (OT). Machines are being integrated with connected sensors and managed by intelligent analytics applications, accelerating digital transformation and business operations. Bringing Machine Learning (ML) to industrial devices is an advancement aiming to promote the convergence of IT and OT. However, developing an ML application in industrial IoT (IIoT) presents various challenges, including hardware heterogeneity, non-standardized representations of ML models, device and ML model compatibility issues, and slow application development. Successful deployment in this area requires a deep understanding of hardware, algorithms, software tools, and applications. Therefore, this paper presents a framework called Semantic Low-Code Engineering for ML Applications (SeLoC-ML), built on a low-code platform to support the rapid development of ML applications in IIoT by leveraging Semantic Web technologies. SeLoC-ML enables non-experts to easily model, discover, reuse, and matchmake ML models and devices at scale. The project code can be automatically generated for deployment on hardware based on the matching results. Developers can benefit from semantic application templates, called recipes, to fast prototype end-user applications. The evaluations confirm an engineering effort reduction by a factor of at least three compared to traditional approaches on an industrial ML classification case study, showing the efficiency and usefulness of SeLoC-ML. We share the code and welcome any contributions.
Interpretable Control by Reinforcement Learning
Jul 20, 2020

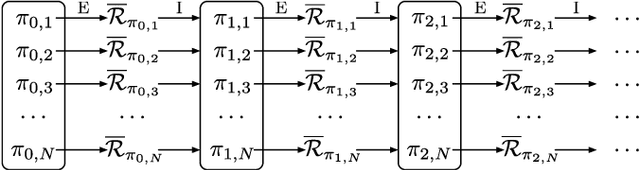
In this paper, three recently introduced reinforcement learning (RL) methods are used to generate human-interpretable policies for the cart-pole balancing benchmark. The novel RL methods learn human-interpretable policies in the form of compact fuzzy controllers and simple algebraic equations. The representations as well as the achieved control performances are compared with two classical controller design methods and three non-interpretable RL methods. All eight methods utilize the same previously generated data batch and produce their controller offline - without interaction with the real benchmark dynamics. The experiments show that the novel RL methods are able to automatically generate well-performing policies which are at the same time human-interpretable. Furthermore, one of the methods is applied to automatically learn an equation-based policy for a hardware cart-pole demonstrator by using only human-player-generated batch data. The solution generated in the first attempt already represents a successful balancing policy, which demonstrates the methods applicability to real-world problems.
Modeling System Dynamics with Physics-Informed Neural Networks Based on Lagrangian Mechanics
May 29, 2020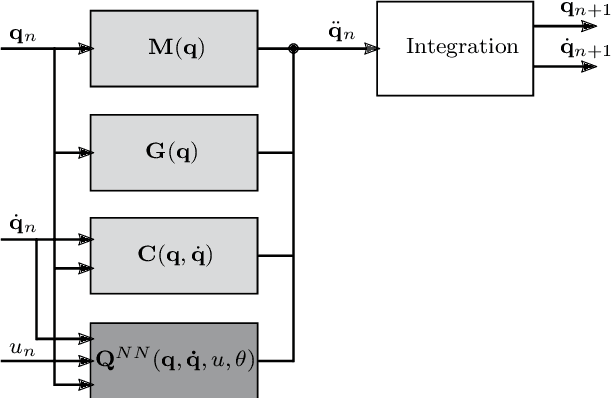
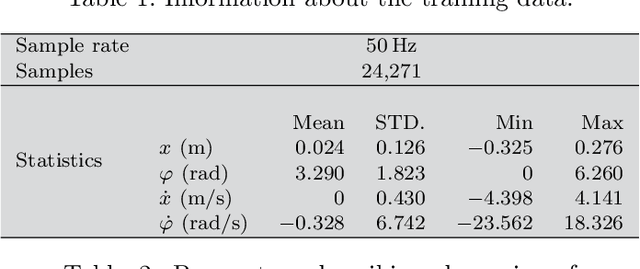
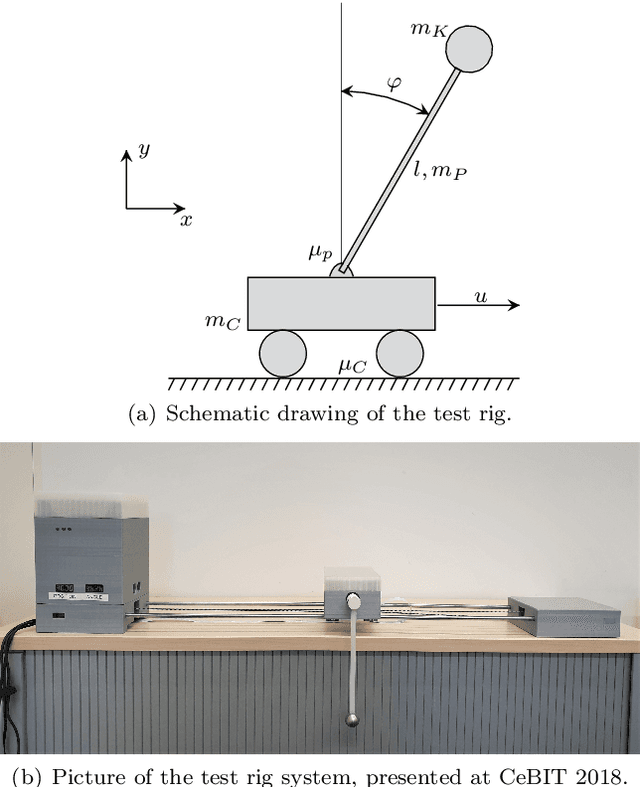
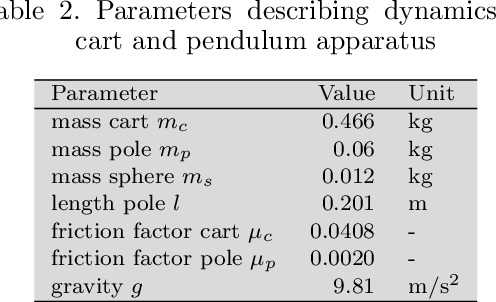
Identifying accurate dynamic models is required for the simulation and control of various technical systems. In many important real-world applications, however, the two main modeling approaches often fail to meet requirements: first principles methods suffer from high bias, whereas data-driven modeling tends to have high variance. Additionally, purely data-based models often require large amounts of data and are often difficult to interpret. In this paper, we present physics-informed neural ordinary differential equations (PINODE), a hybrid model that combines the two modeling techniques to overcome the aforementioned problems. This new approach directly incorporates the equations of motion originating from the Lagrange Mechanics into a deep neural network structure. Thus, we can integrate prior physics knowledge where it is available and use function approximation--e. g., neural networks--where it is not. The method is tested with a forward model of a real-world physical system with large uncertainties. The resulting model is accurate and data-efficient while ensuring physical plausibility. With this, we demonstrate a method that beneficially merges physical insight with real data. Our findings are of interest for model-based control and system identification of mechanical systems.
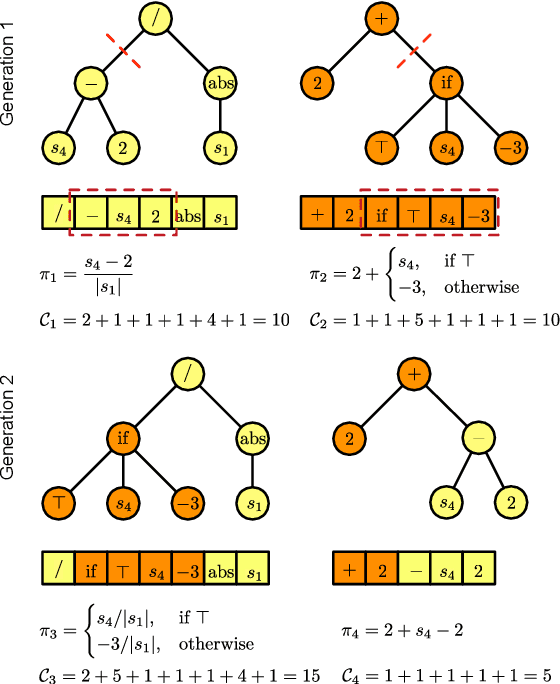
Generating Interpretable Fuzzy Controllers using Particle Swarm Optimization and Genetic Programming
Apr 29, 2018


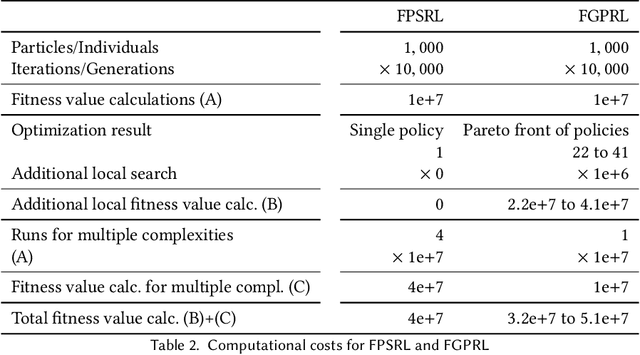
Autonomously training interpretable control strategies, called policies, using pre-existing plant trajectory data is of great interest in industrial applications. Fuzzy controllers have been used in industry for decades as interpretable and efficient system controllers. In this study, we introduce a fuzzy genetic programming (GP) approach called fuzzy GP reinforcement learning (FGPRL) that can select the relevant state features, determine the size of the required fuzzy rule set, and automatically adjust all the controller parameters simultaneously. Each GP individual's fitness is computed using model-based batch reinforcement learning (RL), which first trains a model using available system samples and subsequently performs Monte Carlo rollouts to predict each policy candidate's performance. We compare FGPRL to an extended version of a related method called fuzzy particle swarm reinforcement learning (FPSRL), which uses swarm intelligence to tune the fuzzy policy parameters. Experiments using an industrial benchmark show that FGPRL is able to autonomously learn interpretable fuzzy policies with high control performance.