 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSFM in-context learning for time-series classification of bearing-health status
Nov 19, 2025This paper introduces a classification method using in-context learning in time-series foundation models (TSFM). We show how data, which was not part of the TSFM training data corpus, can be classified without the need of finetuning the model. Examples are represented in the form of targets (class id) and covariates (data matrix) within the prompt of the model, which enables to classify an unknown covariate data pattern alongside the forecast axis through in-context learning. We apply this method to vibration data for assessing the health state of a bearing within a servo-press motor. The method transforms frequency domain reference signals into pseudo time-series patterns, generates aligned covariate and target signals, and uses the TSFM to predict probabilities how classified data corresponds to predefined labels. Leveraging the scalability of pre-trained models this method demonstrates efficacy across varied operational conditions. This marks significant progress beyond custom narrow AI solutions towards broader, AI-driven maintenance systems.
Modeling System Dynamics with Physics-Informed Neural Networks Based on Lagrangian Mechanics
May 29, 2020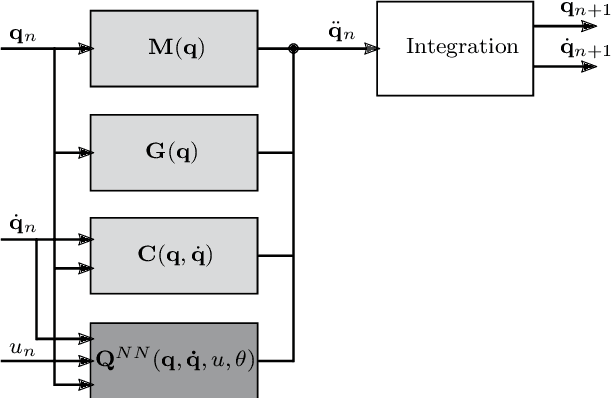
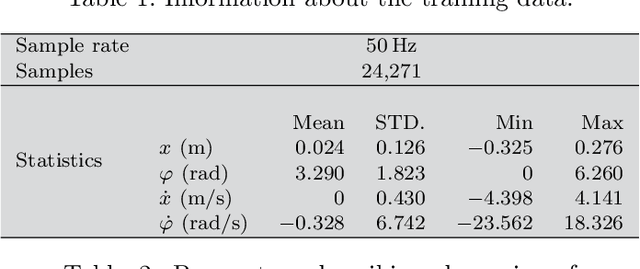
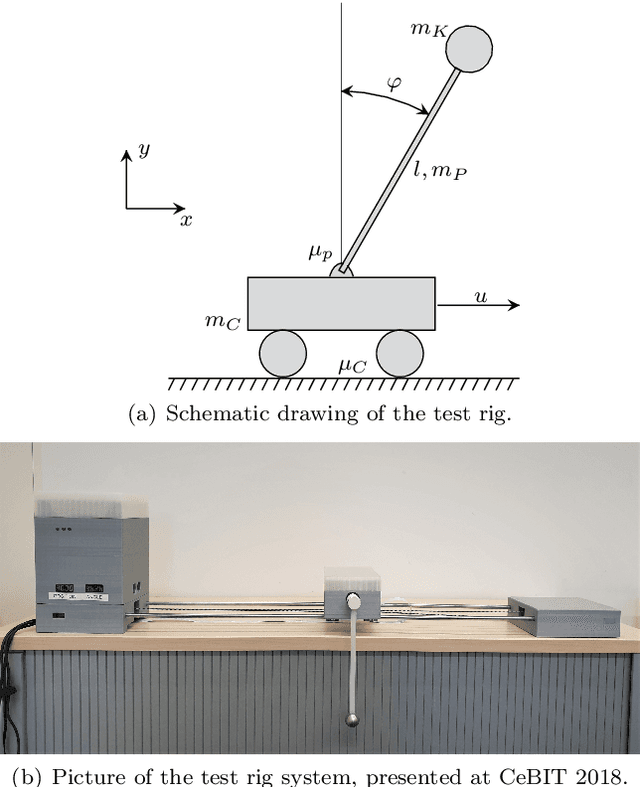
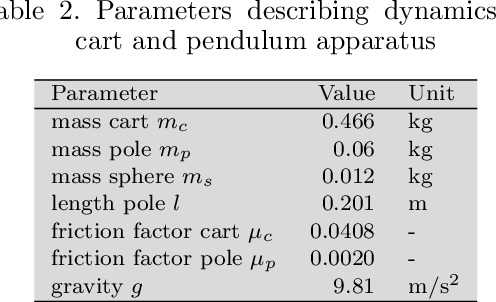
Identifying accurate dynamic models is required for the simulation and control of various technical systems. In many important real-world applications, however, the two main modeling approaches often fail to meet requirements: first principles methods suffer from high bias, whereas data-driven modeling tends to have high variance. Additionally, purely data-based models often require large amounts of data and are often difficult to interpret. In this paper, we present physics-informed neural ordinary differential equations (PINODE), a hybrid model that combines the two modeling techniques to overcome the aforementioned problems. This new approach directly incorporates the equations of motion originating from the Lagrange Mechanics into a deep neural network structure. Thus, we can integrate prior physics knowledge where it is available and use function approximation--e. g., neural networks--where it is not. The method is tested with a forward model of a real-world physical system with large uncertainties. The resulting model is accurate and data-efficient while ensuring physical plausibility. With this, we demonstrate a method that beneficially merges physical insight with real data. Our findings are of interest for model-based control and system identification of mechanical systems.
A Benchmark Environment Motivated by Industrial Control Problems
Feb 06, 2018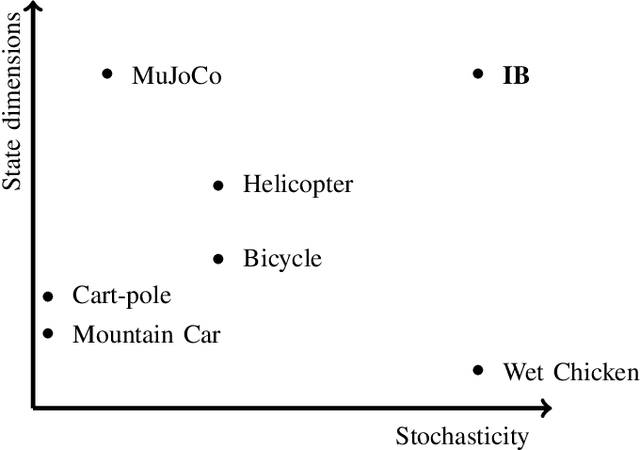
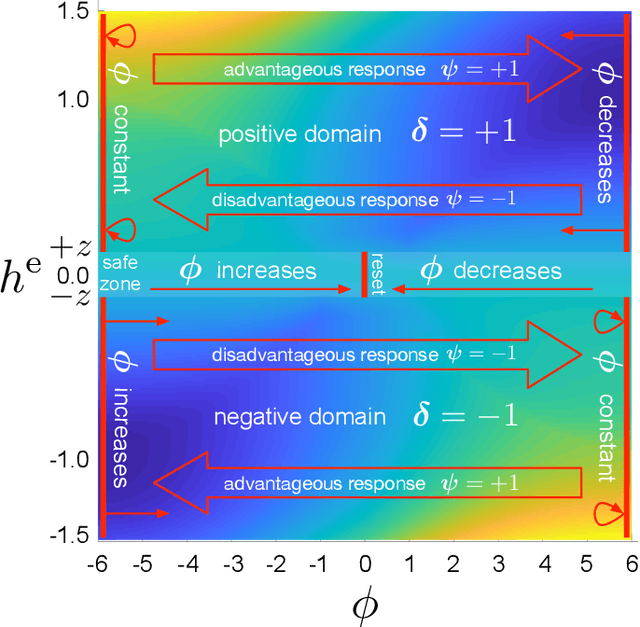
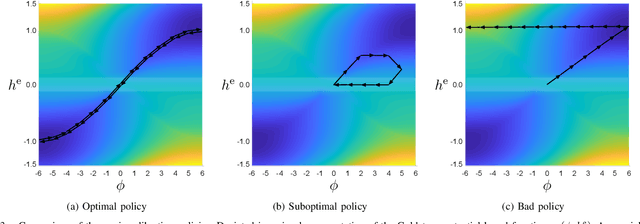
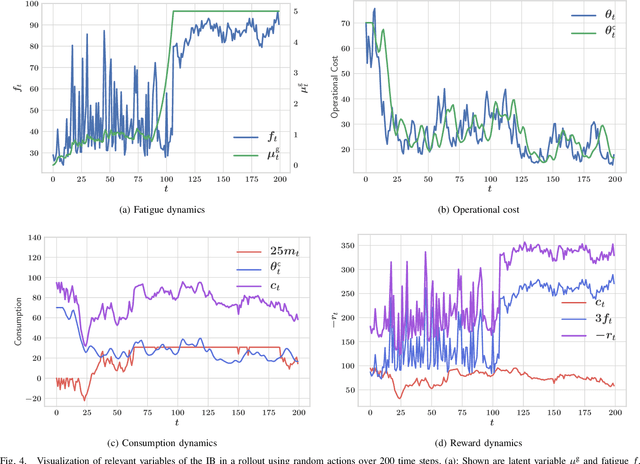
In the research area of reinforcement learning (RL), frequently novel and promising methods are developed and introduced to the RL community. However, although many researchers are keen to apply their methods on real-world problems, implementing such methods in real industry environments often is a frustrating and tedious process. Generally, academic research groups have only limited access to real industrial data and applications. For this reason, new methods are usually developed, evaluated and compared by using artificial software benchmarks. On one hand, these benchmarks are designed to provide interpretable RL training scenarios and detailed insight into the learning process of the method on hand. On the other hand, they usually do not share much similarity with industrial real-world applications. For this reason we used our industry experience to design a benchmark which bridges the gap between freely available, documented, and motivated artificial benchmarks and properties of real industrial problems. The resulting industrial benchmark (IB) has been made publicly available to the RL community by publishing its Java and Python code, including an OpenAI Gym wrapper, on Github. In this paper we motivate and describe in detail the IB's dynamics and identify prototypic experimental settings that capture common situations in real-world industry control problems.
Introduction to the "Industrial Benchmark"
Sep 28, 2017
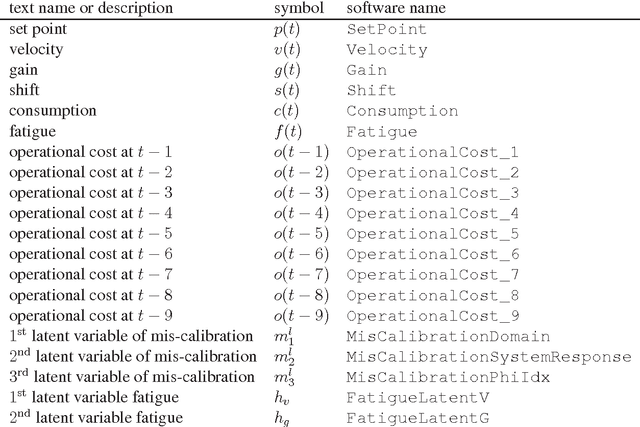
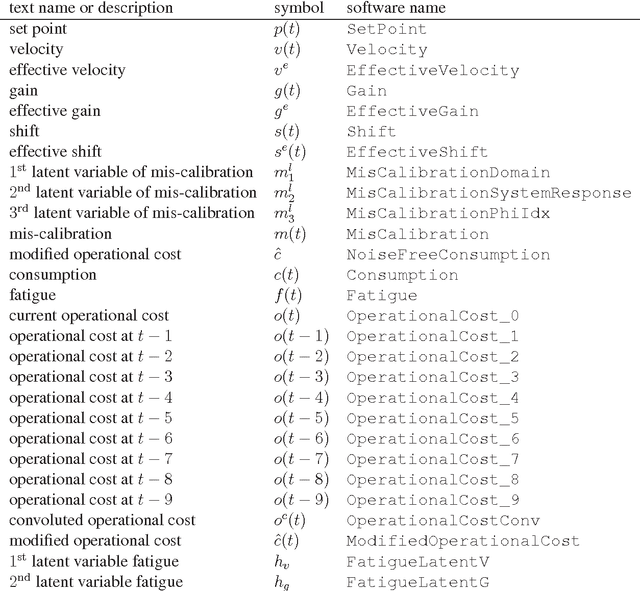
A novel reinforcement learning benchmark, called Industrial Benchmark, is introduced. The Industrial Benchmark aims at being be realistic in the sense, that it includes a variety of aspects that we found to be vital in industrial applications. It is not designed to be an approximation of any real system, but to pose the same hardness and complexity.
Batch Reinforcement Learning on the Industrial Benchmark: First Experiences
Jul 27, 2017
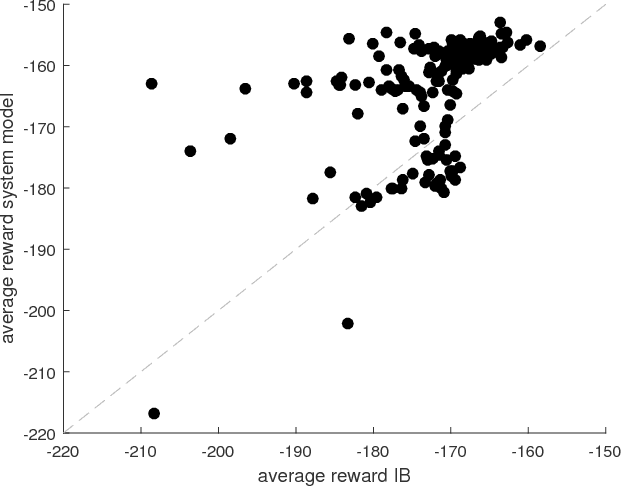


The Particle Swarm Optimization Policy (PSO-P) has been recently introduced and proven to produce remarkable results on interacting with academic reinforcement learning benchmarks in an off-policy, batch-based setting. To further investigate the properties and feasibility on real-world applications, this paper investigates PSO-P on the so-called Industrial Benchmark (IB), a novel reinforcement learning (RL) benchmark that aims at being realistic by including a variety of aspects found in industrial applications, like continuous state and action spaces, a high dimensional, partially observable state space, delayed effects, and complex stochasticity. The experimental results of PSO-P on IB are compared to results of closed-form control policies derived from the model-based Recurrent Control Neural Network (RCNN) and the model-free Neural Fitted Q-Iteration (NFQ). Experiments show that PSO-P is not only of interest for academic benchmarks, but also for real-world industrial applications, since it also yielded the best performing policy in our IB setting. Compared to other well established RL techniques, PSO-P produced outstanding results in performance and robustness, requiring only a relatively low amount of effort in finding adequate parameters or making complex design decisions.