 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Data Quality for Dataset Selection in Offline Reinforcement Learning
Paper and Code
Nov 26, 2021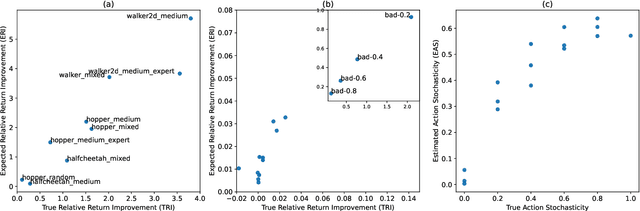
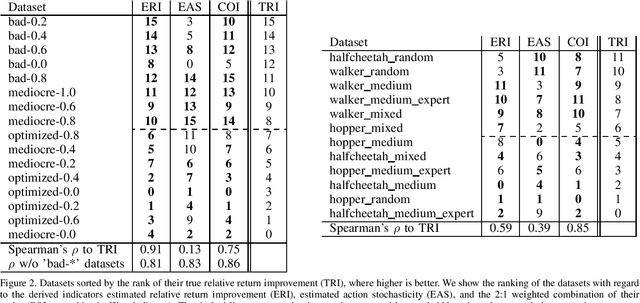
Recently developed offline reinforcement learning algorithms have made it possible to learn policies directly from pre-collected datasets, giving rise to a new dilemma for practitioners: Since the performance the algorithms are able to deliver depends greatly on the dataset that is presented to them, practitioners need to pick the right dataset among the available ones. This problem has so far not been discussed in the corresponding literature. We discuss ideas how to select promising datasets and propose three very simple indicators: Estimated relative return improvement (ERI) and estimated action stochasticity (EAS), as well as a combination of the two (COI), and empirically show that despite their simplicity they can be very effectively used for dataset selection.