Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Model-free and Model-based Algorithms for Offline Reinforcement Learning
Paper and Code
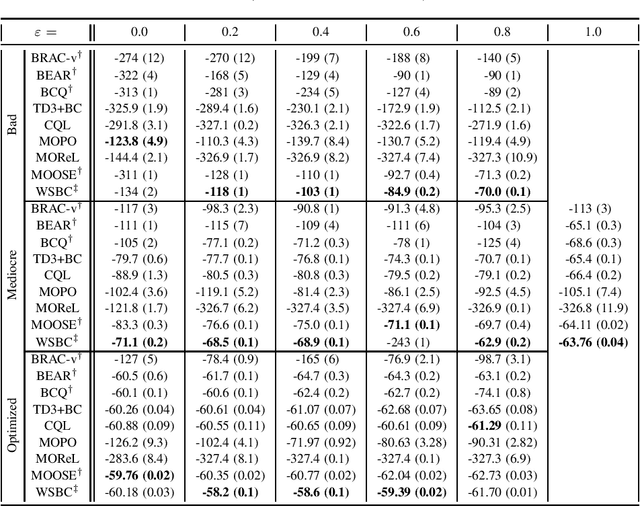
Offline reinforcement learning (RL) Algorithms are often designed with environments such as MuJoCo in mind, in which the planning horizon is extremely long and no noise exists. We compare model-free, model-based, as well as hybrid offline RL approaches on various industrial benchmark (IB) datasets to test the algorithms in settings closer to real world problems, including complex noise and partially observable states. We find that on the IB, hybrid approaches face severe difficulties and that simpler algorithms, such as rollout based algorithms or model-free algorithms with simpler regularizers perform best on the datasets.
* Submitted to IFAC Conference on Intelligent Control and Automation
Sciences (ICONS)2022
View paper on