 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFsPONER: Few-shot Prompt Optimization for Named Entity Recognition in Domain-specific Scenarios
Jul 10, 2024

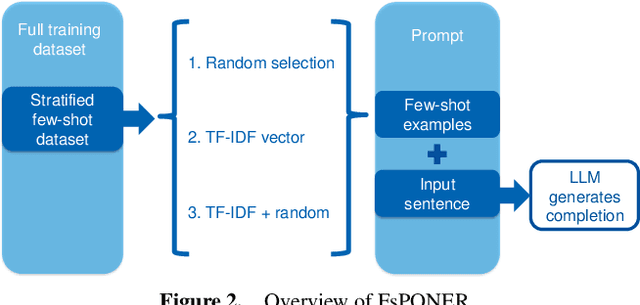

Large Language Models (LLMs) have provided a new pathway for Named Entity Recognition (NER) tasks. Compared with fine-tuning, LLM-powered prompting methods avoid the need for training, conserve substantial computational resources, and rely on minimal annotated data. Previous studies have achieved comparable performance to fully supervised BERT-based fine-tuning approaches on general NER benchmarks. However, none of the previous approaches has investigated the efficiency of LLM-based few-shot learning in domain-specific scenarios. To address this gap, we introduce FsPONER, a novel approach for optimizing few-shot prompts, and evaluate its performance on domain-specific NER datasets, with a focus on industrial manufacturing and maintenance, while using multiple LLMs -- GPT-4-32K, GPT-3.5-Turbo, LLaMA 2-chat, and Vicuna. FsPONER consists of three few-shot selection methods based on random sampling, TF-IDF vectors, and a combination of both. We compare these methods with a general-purpose GPT-NER method as the number of few-shot examples increases and evaluate their optimal NER performance against fine-tuned BERT and LLaMA 2-chat. In the considered real-world scenarios with data scarcity, FsPONER with TF-IDF surpasses fine-tuned models by approximately 10% in F1 score.
Named Entity Recognition in Industrial Tables using Tabular Language Models
Sep 29, 2022

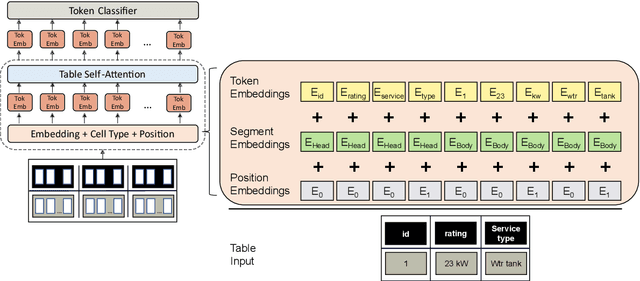
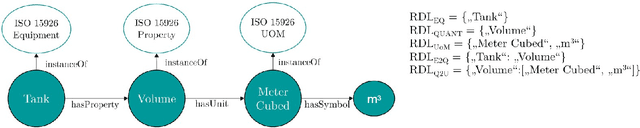
Specialized transformer-based models for encoding tabular data have gained interest in academia. Although tabular data is omnipresent in industry, applications of table transformers are still missing. In this paper, we study how these models can be applied to an industrial Named Entity Recognition (NER) problem where the entities are mentioned in tabular-structured spreadsheets. The highly technical nature of spreadsheets as well as the lack of labeled data present major challenges for fine-tuning transformer-based models. Therefore, we develop a dedicated table data augmentation strategy based on available domain-specific knowledge graphs. We show that this boosts performance in our low-resource scenario considerably. Further, we investigate the benefits of tabular structure as inductive bias compared to tables as linearized sequences. Our experiments confirm that a table transformer outperforms other baselines and that its tabular inductive bias is vital for convergence of transformer-based models.