 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWiki-TabNER:Advancing Table Interpretation Through Named Entity Recognition
Mar 07, 2024



Web tables contain a large amount of valuable knowledge and have inspired tabular language models aimed at tackling table interpretation (TI) tasks. In this paper, we analyse a widely used benchmark dataset for evaluation of TI tasks, particularly focusing on the entity linking task. Our analysis reveals that this dataset is overly simplified, potentially reducing its effectiveness for thorough evaluation and failing to accurately represent tables as they appear in the real-world. To overcome this drawback, we construct and annotate a new more challenging dataset. In addition to introducing the new dataset, we also introduce a novel problem aimed at addressing the entity linking task: named entity recognition within cells. Finally, we propose a prompting framework for evaluating the newly developed large language models (LLMs) on this novel TI task. We conduct experiments on prompting LLMs under various settings, where we use both random and similarity-based selection to choose the examples presented to the models. Our ablation study helps us gain insights into the impact of the few-shot examples. Additionally, we perform qualitative analysis to gain insights into the challenges encountered by the models and to understand the limitations of the proposed dataset.
Adversarial Attacks on Tables with Entity Swap
Sep 15, 2023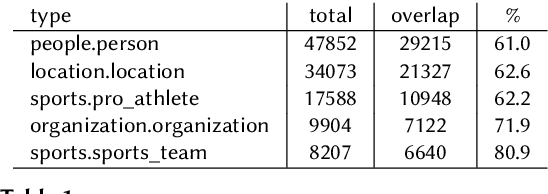
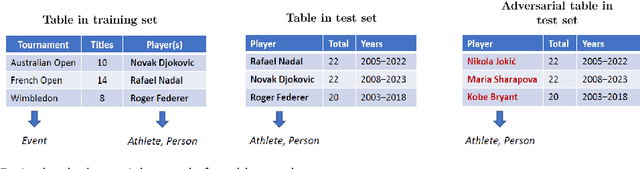
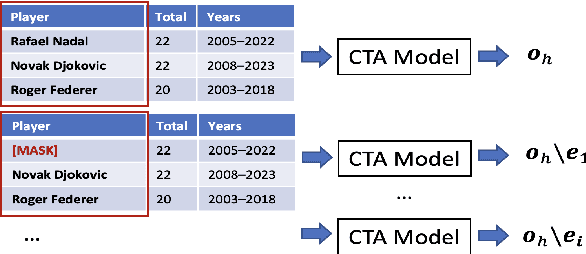
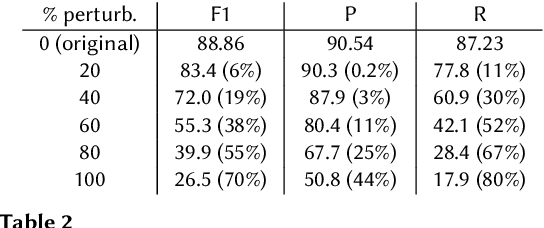
The capabilities of large language models (LLMs) have been successfully applied in the context of table representation learning. The recently proposed tabular language models have reported state-of-the-art results across various tasks for table interpretation. However, a closer look into the datasets commonly used for evaluation reveals an entity leakage from the train set into the test set. Motivated by this observation, we explore adversarial attacks that represent a more realistic inference setup. Adversarial attacks on text have been shown to greatly affect the performance of LLMs, but currently, there are no attacks targeting tabular language models. In this paper, we propose an evasive entity-swap attack for the column type annotation (CTA) task. Our CTA attack is the first black-box attack on tables, where we employ a similarity-based sampling strategy to generate adversarial examples. The experimental results show that the proposed attack generates up to a 70% drop in performance.
Active Learning with Tabular Language Models
Nov 08, 2022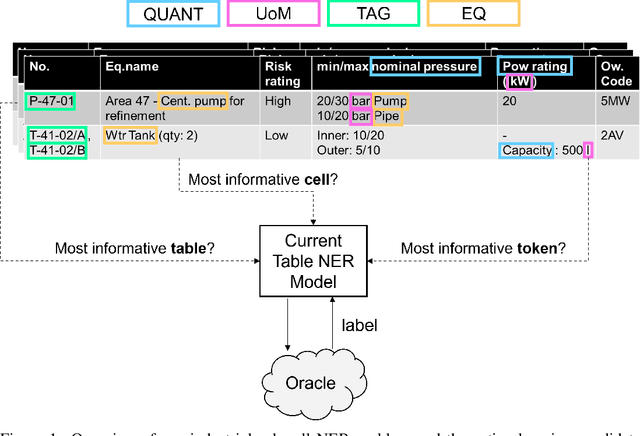
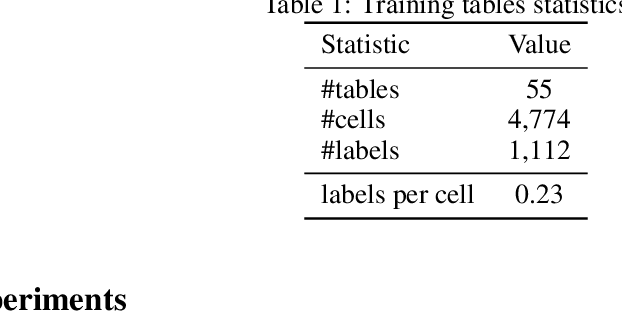
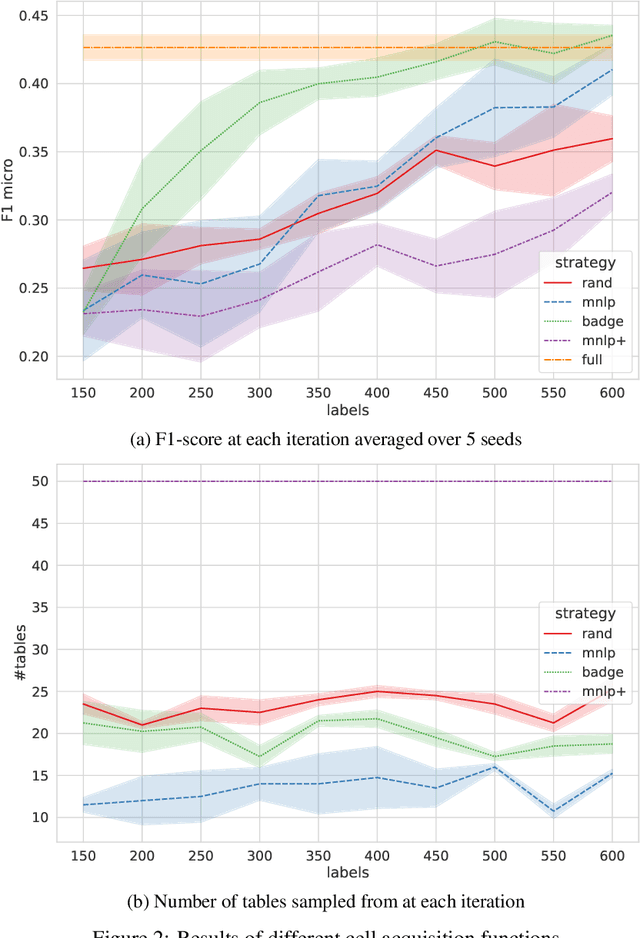
Despite recent advancements in tabular language model research, real-world applications are still challenging. In industry, there is an abundance of tables found in spreadsheets, but acquisition of substantial amounts of labels is expensive, since only experts can annotate the often highly technical and domain-specific tables. Active learning could potentially reduce labeling costs, however, so far there are no works related to active learning in conjunction with tabular language models. In this paper we investigate different acquisition functions in a real-world industrial tabular language model use case for sub-cell named entity recognition. Our results show that cell-level acquisition functions with built-in diversity can significantly reduce the labeling effort, while enforced table diversity is detrimental. We further see open fundamental questions concerning computational efficiency and the perspective of human annotators.
Named Entity Recognition in Industrial Tables using Tabular Language Models
Sep 29, 2022

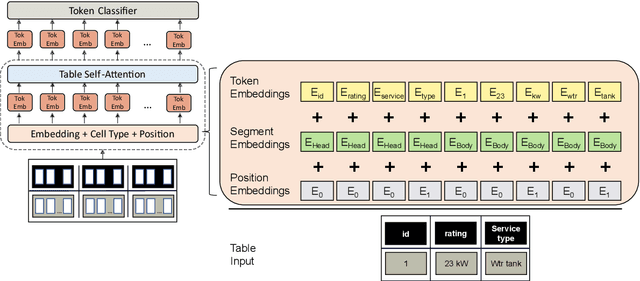
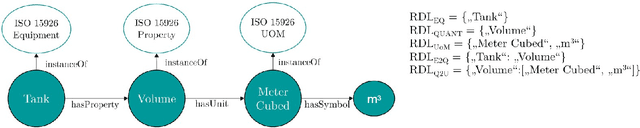
Specialized transformer-based models for encoding tabular data have gained interest in academia. Although tabular data is omnipresent in industry, applications of table transformers are still missing. In this paper, we study how these models can be applied to an industrial Named Entity Recognition (NER) problem where the entities are mentioned in tabular-structured spreadsheets. The highly technical nature of spreadsheets as well as the lack of labeled data present major challenges for fine-tuning transformer-based models. Therefore, we develop a dedicated table data augmentation strategy based on available domain-specific knowledge graphs. We show that this boosts performance in our low-resource scenario considerably. Further, we investigate the benefits of tabular structure as inductive bias compared to tables as linearized sequences. Our experiments confirm that a table transformer outperforms other baselines and that its tabular inductive bias is vital for convergence of transformer-based models.
Generating Table Vector Representations
Oct 28, 2021
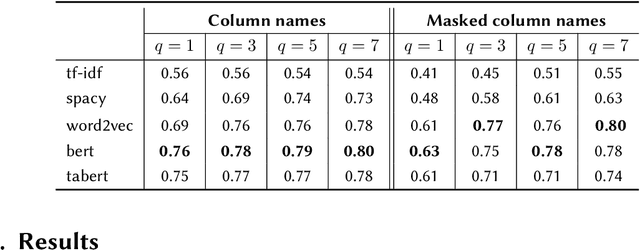


High-quality Web tables are rich sources of information that can be used to populate Knowledge Graphs (KG). The focus of this paper is an evaluation of methods for table-to-class annotation, which is a sub-task of Table Interpretation (TI). We provide a formal definition for table classification as a machine learning task. We propose an experimental setup and we evaluate 5 fundamentally different approaches to find the best method for generating vector table representations. Our findings indicate that although transfer learning methods achieve high F1 score on the table classification task, dedicated table encoding models are a promising direction as they appear to capture richer semantics.
Knowledge Graphs Evolution and Preservation -- A Technical Report from ISWS 2019
Dec 22, 2020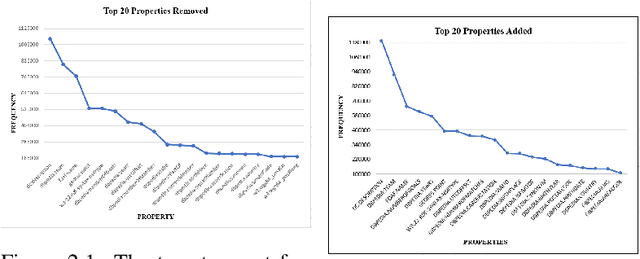
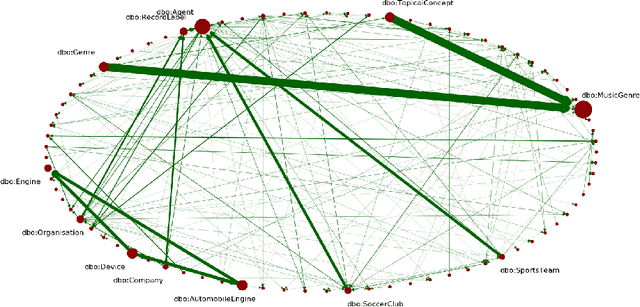

One of the grand challenges discussed during the Dagstuhl Seminar "Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web" and described in its report is that of a: "Public FAIR Knowledge Graph of Everything: We increasingly see the creation of knowledge graphs that capture information about the entirety of a class of entities. [...] This grand challenge extends this further by asking if we can create a knowledge graph of "everything" ranging from common sense concepts to location based entities. This knowledge graph should be "open to the public" in a FAIR manner democratizing this mass amount of knowledge." Although linked open data (LOD) is one knowledge graph, it is the closest realisation (and probably the only one) to a public FAIR Knowledge Graph (KG) of everything. Surely, LOD provides a unique testbed for experimenting and evaluating research hypotheses on open and FAIR KG. One of the most neglected FAIR issues about KGs is their ongoing evolution and long term preservation. We want to investigate this problem, that is to understand what preserving and supporting the evolution of KGs means and how these problems can be addressed. Clearly, the problem can be approached from different perspectives and may require the development of different approaches, including new theories, ontologies, metrics, strategies, procedures, etc. This document reports a collaborative effort performed by 9 teams of students, each guided by a senior researcher as their mentor, attending the International Semantic Web Research School (ISWS 2019). Each team provides a different perspective to the problem of knowledge graph evolution substantiated by a set of research questions as the main subject of their investigation. In addition, they provide their working definition for KG preservation and evolution.