 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Calibration of Graph Neural Networks for Node Classification
Jun 03, 2022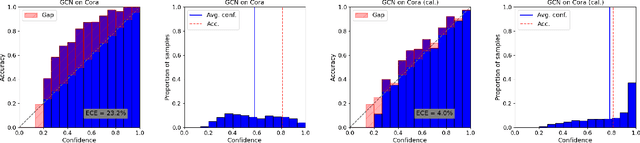
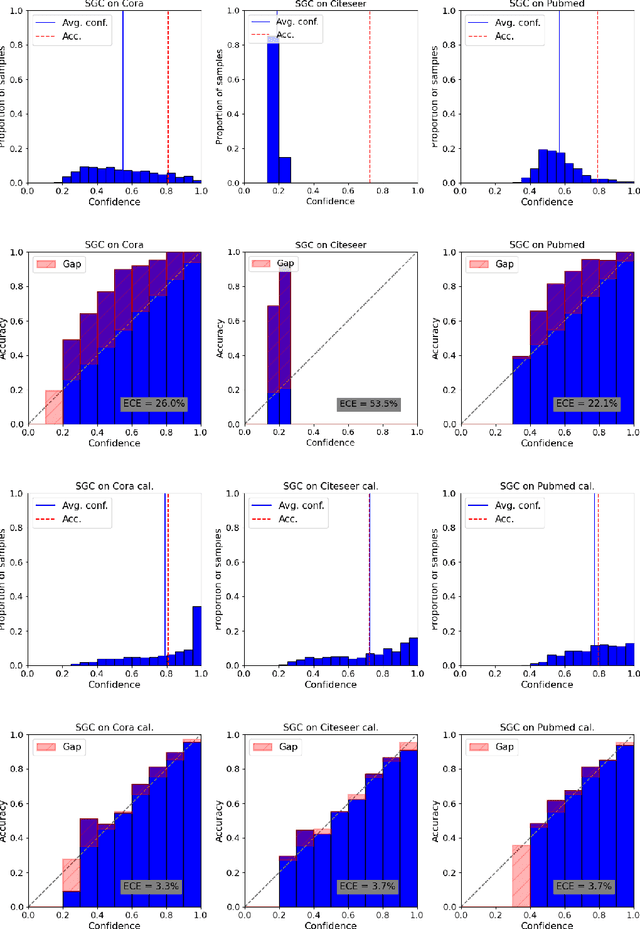
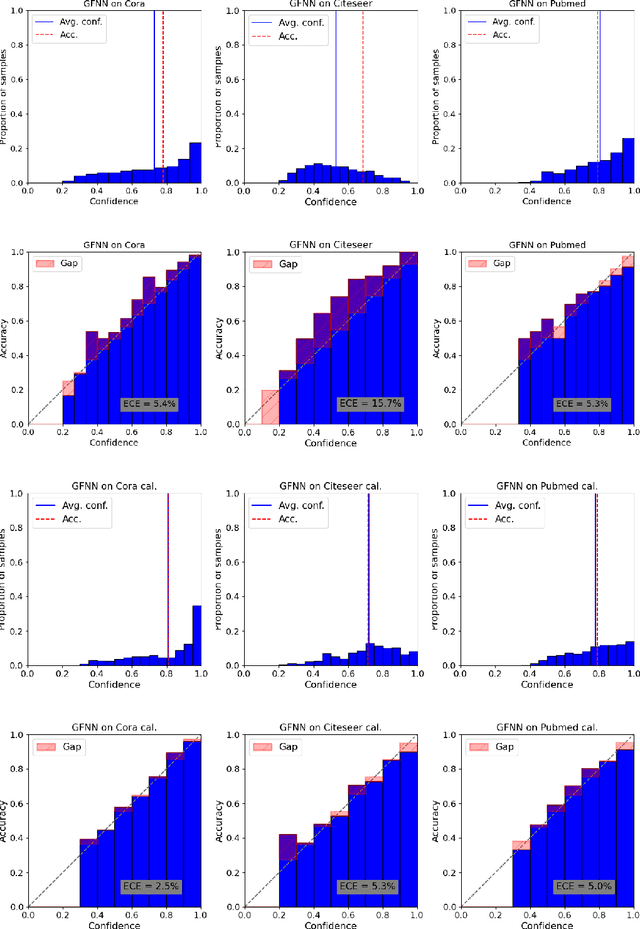
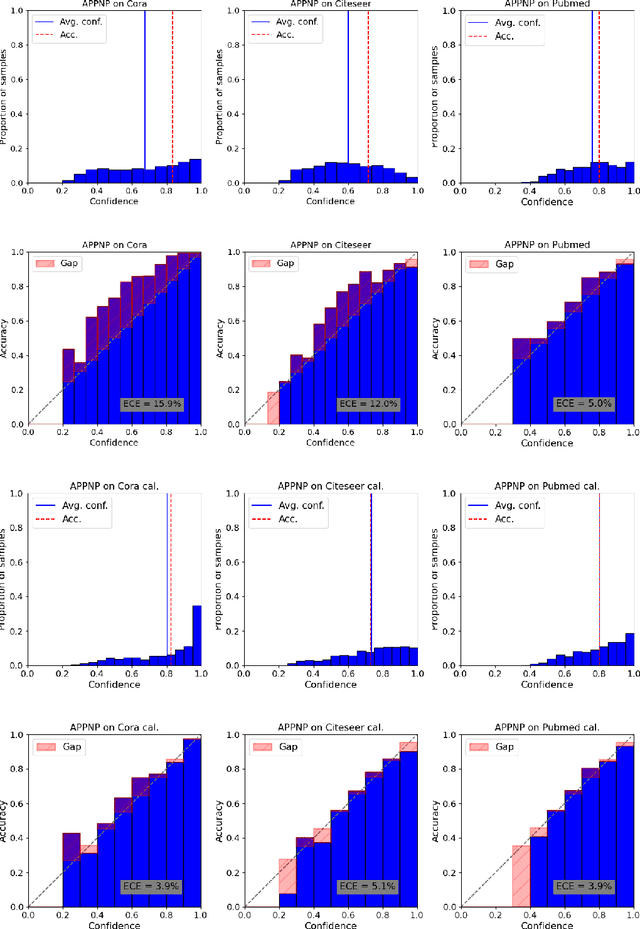
Graphs can model real-world, complex systems by representing entities and their interactions in terms of nodes and edges. To better exploit the graph structure, graph neural networks have been developed, which learn entity and edge embeddings for tasks such as node classification and link prediction. These models achieve good performance with respect to accuracy, but the confidence scores associated with the predictions might not be calibrated. That means that the scores might not reflect the ground-truth probabilities of the predicted events, which would be especially important for safety-critical applications. Even though graph neural networks are used for a wide range of tasks, the calibration thereof has not been sufficiently explored yet. We investigate the calibration of graph neural networks for node classification, study the effect of existing post-processing calibration methods, and analyze the influence of model capacity, graph density, and a new loss function on calibration. Further, we propose a topology-aware calibration method that takes the neighboring nodes into account and yields improved calibration compared to baseline methods.
TLogic: Temporal Logical Rules for Explainable Link Forecasting on Temporal Knowledge Graphs
Dec 15, 2021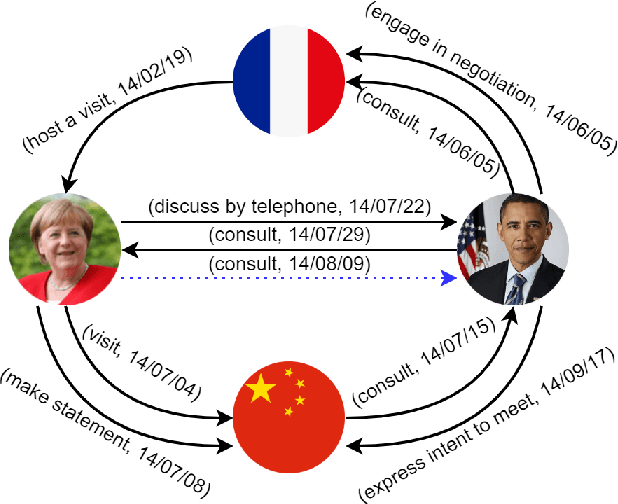
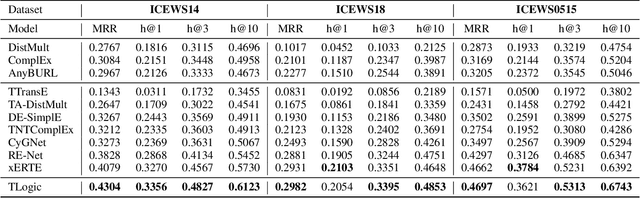

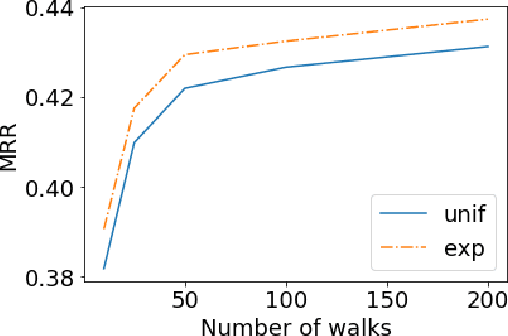
Conventional static knowledge graphs model entities in relational data as nodes, connected by edges of specific relation types. However, information and knowledge evolve continuously, and temporal dynamics emerge, which are expected to influence future situations. In temporal knowledge graphs, time information is integrated into the graph by equipping each edge with a timestamp or a time range. Embedding-based methods have been introduced for link prediction on temporal knowledge graphs, but they mostly lack explainability and comprehensible reasoning chains. Particularly, they are usually not designed to deal with link forecasting -- event prediction involving future timestamps. We address the task of link forecasting on temporal knowledge graphs and introduce TLogic, an explainable framework that is based on temporal logical rules extracted via temporal random walks. We compare TLogic with state-of-the-art baselines on three benchmark datasets and show better overall performance while our method also provides explanations that preserve time consistency. Furthermore, in contrast to most state-of-the-art embedding-based methods, TLogic works well in the inductive setting where already learned rules are transferred to related datasets with a common vocabulary.
Combining Sub-Symbolic and Symbolic Methods for Explainability
Dec 03, 2021



Similarly to other connectionist models, Graph Neural Networks (GNNs) lack transparency in their decision-making. A number of sub-symbolic approaches have been developed to provide insights into the GNN decision making process. These are first important steps on the way to explainability, but the generated explanations are often hard to understand for users that are not AI experts. To overcome this problem, we introduce a conceptual approach combining sub-symbolic and symbolic methods for human-centric explanations, that incorporate domain knowledge and causality. We furthermore introduce the notion of fidelity as a metric for evaluating how close the explanation is to the GNN's internal decision making process. The evaluation with a chemical dataset and ontology shows the explanatory value and reliability of our method.
Demystifying Graph Neural Network Explanations
Nov 25, 2021

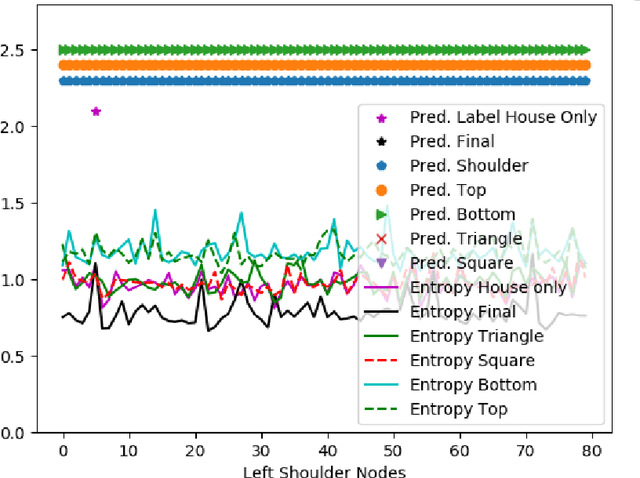

Graph neural networks (GNNs) are quickly becoming the standard approach for learning on graph structured data across several domains, but they lack transparency in their decision-making. Several perturbation-based approaches have been developed to provide insights into the decision making process of GNNs. As this is an early research area, the methods and data used to evaluate the generated explanations lack maturity. We explore these existing approaches and identify common pitfalls in three main areas: (1) synthetic data generation process, (2) evaluation metrics, and (3) the final presentation of the explanation. For this purpose, we perform an empirical study to explore these pitfalls along with their unintended consequences and propose remedies to mitigate their effects.
Generating Table Vector Representations
Oct 28, 2021
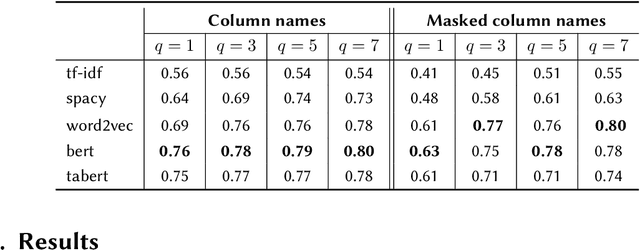


High-quality Web tables are rich sources of information that can be used to populate Knowledge Graphs (KG). The focus of this paper is an evaluation of methods for table-to-class annotation, which is a sub-task of Table Interpretation (TI). We provide a formal definition for table classification as a machine learning task. We propose an experimental setup and we evaluate 5 fundamentally different approaches to find the best method for generating vector table representations. Our findings indicate that although transfer learning methods achieve high F1 score on the table classification task, dedicated table encoding models are a promising direction as they appear to capture richer semantics.
Power to the Relational Inductive Bias: Graph Neural Networks in Electrical Power Grids
Sep 08, 2021

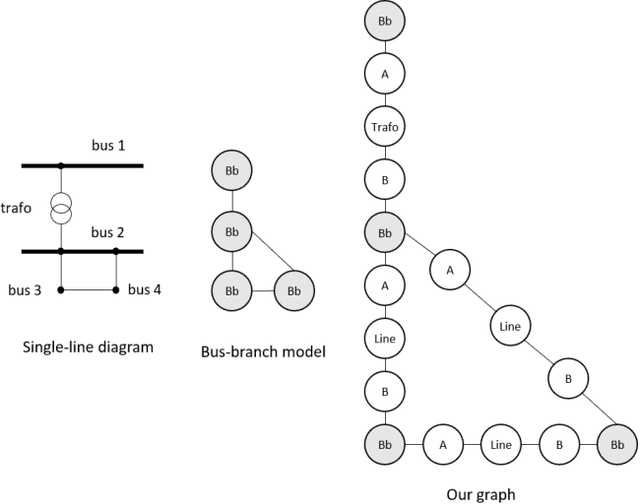
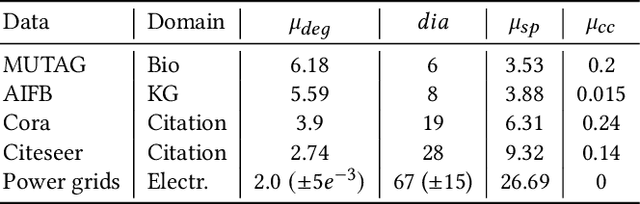
The application of graph neural networks (GNNs) to the domain of electrical power grids has high potential impact on smart grid monitoring. Even though there is a natural correspondence of power flow to message-passing in GNNs, their performance on power grids is not well-understood. We argue that there is a gap between GNN research driven by benchmarks which contain graphs that differ from power grids in several important aspects. Additionally, inductive learning of GNNs across multiple power grid topologies has not been explored with real-world data. We address this gap by means of (i) defining power grid graph datasets in inductive settings, (ii) an exploratory analysis of graph properties, and (iii) an empirical study of the concrete learning task of state estimation on real-world power grids. Our results show that GNNs are more robust to noise with up to 400% lower error compared to baselines. Furthermore, due to the unique properties of electrical grids, we do not observe the well known over-smoothing phenomenon of GNNs and find the best performing models to be exceptionally deep with up to 13 layers. This is in stark contrast to existing benchmark datasets where the consensus is that 2 to 3 layer GNNs perform best. Our results demonstrate that a key challenge in this domain is to effectively handle long-range dependence.
Neural Multi-Hop Reasoning With Logical Rules on Biomedical Knowledge Graphs
Mar 18, 2021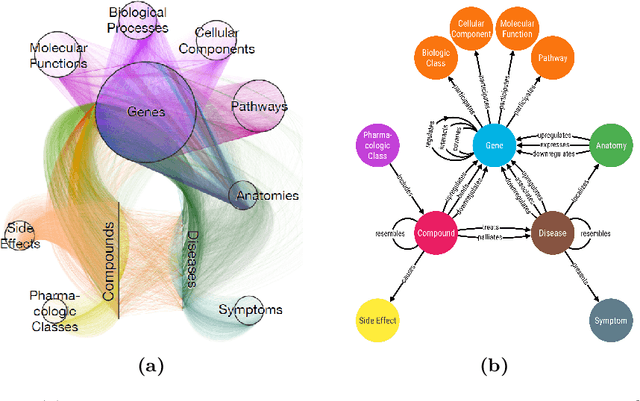

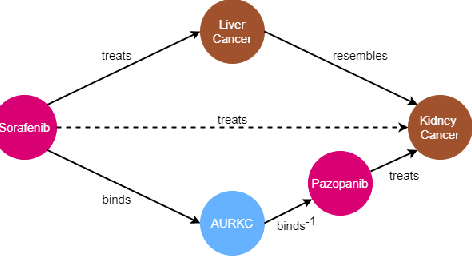

Biomedical knowledge graphs permit an integrative computational approach to reasoning about biological systems. The nature of biological data leads to a graph structure that differs from those typically encountered in benchmarking datasets. To understand the implications this may have on the performance of reasoning algorithms, we conduct an empirical study based on the real-world task of drug repurposing. We formulate this task as a link prediction problem where both compounds and diseases correspond to entities in a knowledge graph. To overcome apparent weaknesses of existing algorithms, we propose a new method, PoLo, that combines policy-guided walks based on reinforcement learning with logical rules. These rules are integrated into the algorithm by using a novel reward function. We apply our method to Hetionet, which integrates biomedical information from 29 prominent bioinformatics databases. Our experiments show that our approach outperforms several state-of-the-art methods for link prediction while providing interpretability.
Integrating Logical Rules Into Neural Multi-Hop Reasoning for Drug Repurposing
Jul 10, 2020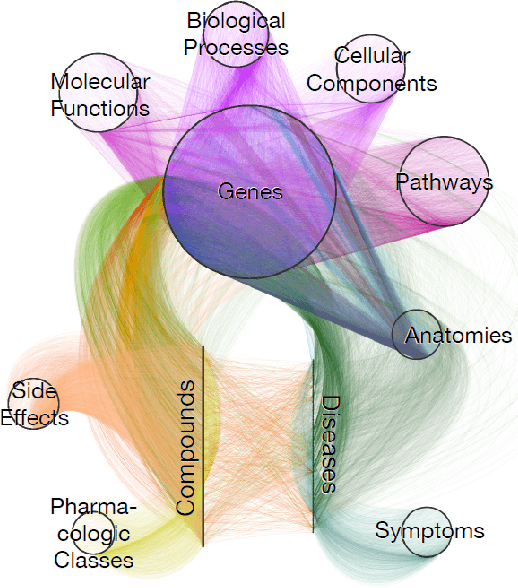

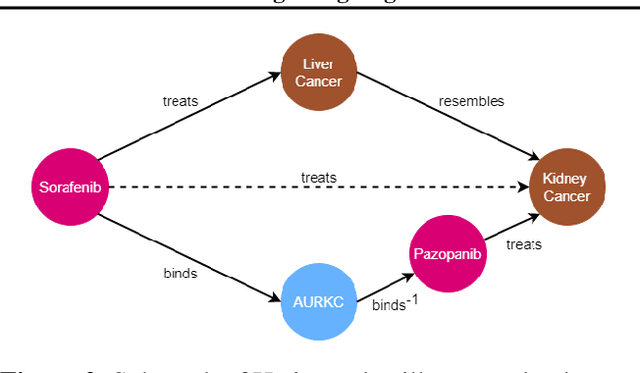
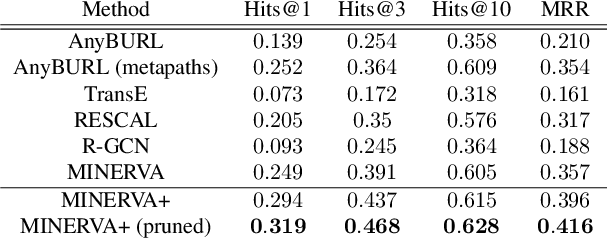
The graph structure of biomedical data differs from those in typical knowledge graph benchmark tasks. A particular property of biomedical data is the presence of long-range dependencies, which can be captured by patterns described as logical rules. We propose a novel method that combines these rules with a neural multi-hop reasoning approach that uses reinforcement learning. We conduct an empirical study based on the real-world task of drug repurposing by formulating this task as a link prediction problem. We apply our method to the biomedical knowledge graph Hetionet and show that our approach outperforms several baseline methods.
Debate Dynamics for Human-comprehensible Fact-checking on Knowledge Graphs
Jan 09, 2020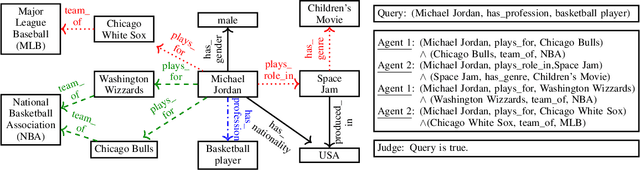


We propose a novel method for fact-checking on knowledge graphs based on debate dynamics. The underlying idea is to frame the task of triple classification as a debate game between two reinforcement learning agents which extract arguments -- paths in the knowledge graph -- with the goal to justify the fact being true (thesis) or the fact being false (antithesis), respectively. Based on these arguments, a binary classifier, referred to as the judge, decides whether the fact is true or false. The two agents can be considered as sparse feature extractors that present interpretable evidence for either the thesis or the antithesis. In contrast to black-box methods, the arguments enable the user to gain an understanding for the decision of the judge. Moreover, our method allows for interactive reasoning on knowledge graphs where the users can raise additional arguments or evaluate the debate taking common sense reasoning and external information into account. Such interactive systems can increase the acceptance of various AI applications based on knowledge graphs and can further lead to higher efficiency, robustness, and fairness.
Reasoning on Knowledge Graphs with Debate Dynamics
Jan 02, 2020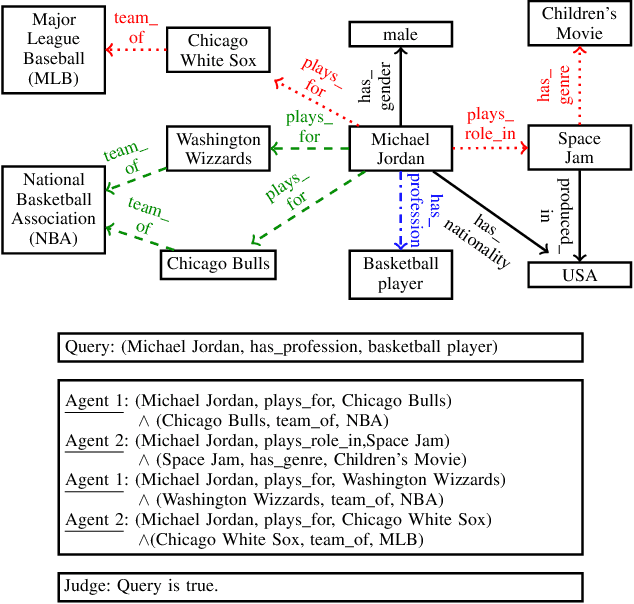

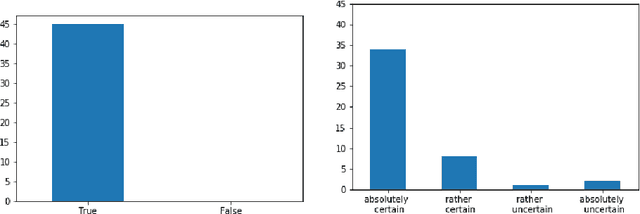
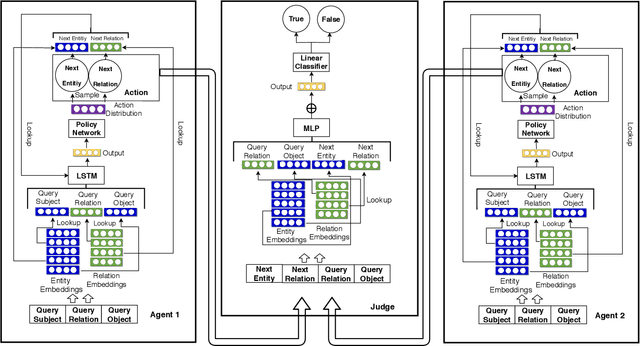
We propose a novel method for automatic reasoning on knowledge graphs based on debate dynamics. The main idea is to frame the task of triple classification as a debate game between two reinforcement learning agents which extract arguments -- paths in the knowledge graph -- with the goal to promote the fact being true (thesis) or the fact being false (antithesis), respectively. Based on these arguments, a binary classifier, called the judge, decides whether the fact is true or false. The two agents can be considered as sparse, adversarial feature generators that present interpretable evidence for either the thesis or the antithesis. In contrast to other black-box methods, the arguments allow users to get an understanding of the decision of the judge. Since the focus of this work is to create an explainable method that maintains a competitive predictive accuracy, we benchmark our method on the triple classification and link prediction task. Thereby, we find that our method outperforms several baselines on the benchmark datasets FB15k-237, WN18RR, and Hetionet. We also conduct a survey and find that the extracted arguments are informative for users.