 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking GPT-5 in Radiation Oncology: Measurable Gains, but Persistent Need for Expert Oversight
Aug 29, 2025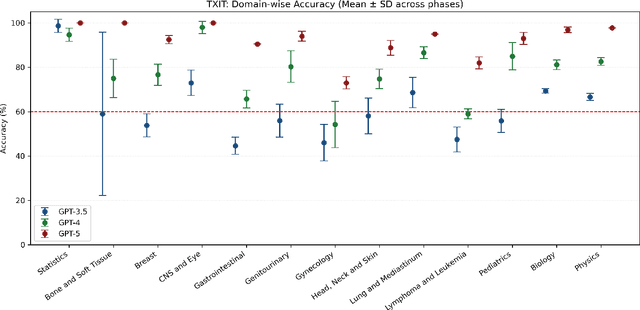
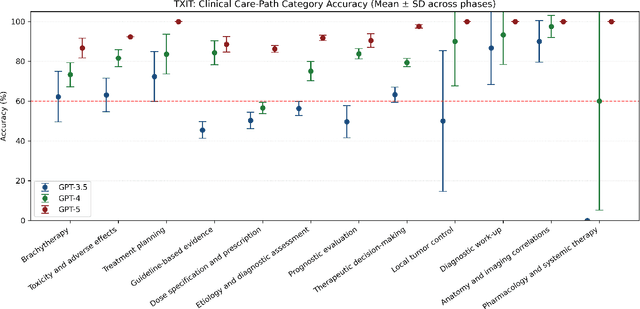

Introduction: Large language models (LLM) have shown great potential in clinical decision support. GPT-5 is a novel LLM system that has been specifically marketed towards oncology use. Methods: Performance was assessed using two complementary benchmarks: (i) the ACR Radiation Oncology In-Training Examination (TXIT, 2021), comprising 300 multiple-choice items, and (ii) a curated set of 60 authentic radiation oncologic vignettes representing diverse disease sites and treatment indications. For the vignette evaluation, GPT-5 was instructed to generate concise therapeutic plans. Four board-certified radiation oncologists rated correctness, comprehensiveness, and hallucinations. Inter-rater reliability was quantified using Fleiss' \k{appa}. Results: On the TXIT benchmark, GPT-5 achieved a mean accuracy of 92.8%, outperforming GPT-4 (78.8%) and GPT-3.5 (62.1%). Domain-specific gains were most pronounced in Dose and Diagnosis. In the vignette evaluation, GPT-5's treatment recommendations were rated highly for correctness (mean 3.24/4, 95% CI: 3.11-3.38) and comprehensiveness (3.59/4, 95% CI: 3.49-3.69). Hallucinations were rare with no case reaching majority consensus for their presence. Inter-rater agreement was low (Fleiss' \k{appa} 0.083 for correctness), reflecting inherent variability in clinical judgment. Errors clustered in complex scenarios requiring precise trial knowledge or detailed clinical adaptation. Discussion: GPT-5 clearly outperformed prior model variants on the radiation oncology multiple-choice benchmark. Although GPT-5 exhibited favorable performance in generating real-world radiation oncology treatment recommendations, correctness ratings indicate room for further improvement. While hallucinations were infrequent, the presence of substantive errors underscores that GPT-5-generated recommendations require rigorous expert oversight before clinical implementation.
A Self-supervised Multimodal Deep Learning Approach to Differentiate Post-radiotherapy Progression from Pseudoprogression in Glioblastoma
Feb 06, 2025



Accurate differentiation of pseudoprogression (PsP) from True Progression (TP) following radiotherapy (RT) in glioblastoma (GBM) patients is crucial for optimal treatment planning. However, this task remains challenging due to the overlapping imaging characteristics of PsP and TP. This study therefore proposes a multimodal deep-learning approach utilizing complementary information from routine anatomical MR images, clinical parameters, and RT treatment planning information for improved predictive accuracy. The approach utilizes a self-supervised Vision Transformer (ViT) to encode multi-sequence MR brain volumes to effectively capture both global and local context from the high dimensional input. The encoder is trained in a self-supervised upstream task on unlabeled glioma MRI datasets from the open BraTS2021, UPenn-GBM, and UCSF-PDGM datasets to generate compact, clinically relevant representations from FLAIR and T1 post-contrast sequences. These encoded MR inputs are then integrated with clinical data and RT treatment planning information through guided cross-modal attention, improving progression classification accuracy. This work was developed using two datasets from different centers: the Burdenko Glioblastoma Progression Dataset (n = 59) for training and validation, and the GlioCMV progression dataset from the University Hospital Erlangen (UKER) (n = 20) for testing. The proposed method achieved an AUC of 75.3%, outperforming the current state-of-the-art data-driven approaches. Importantly, the proposed approach relies on readily available anatomical MRI sequences, clinical data, and RT treatment planning information, enhancing its clinical feasibility. The proposed approach addresses the challenge of limited data availability for PsP and TP differentiation and could allow for improved clinical decision-making and optimized treatment plans for GBM patients.
Task-Specific Data Preparation for Deep Learning to Reconstruct Structures of Interest from Severely Truncated CBCT Data
Sep 13, 2024
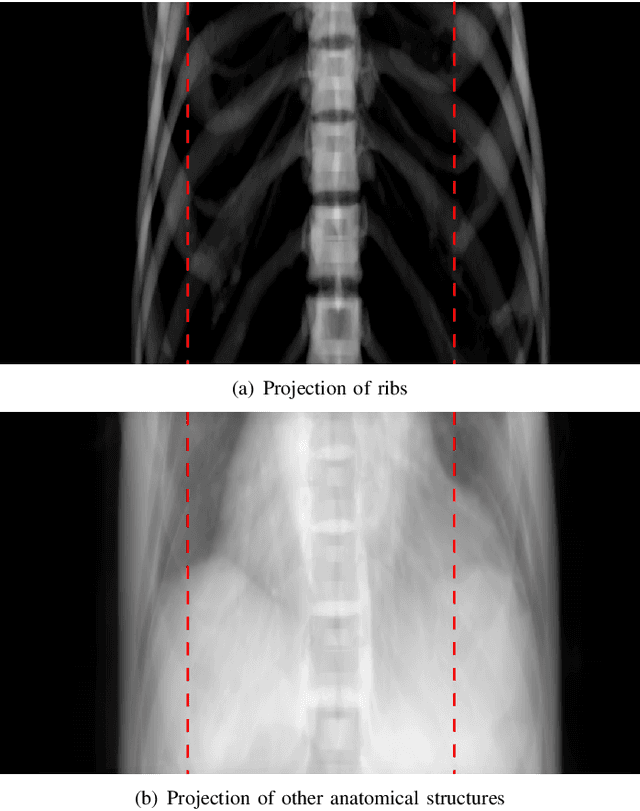
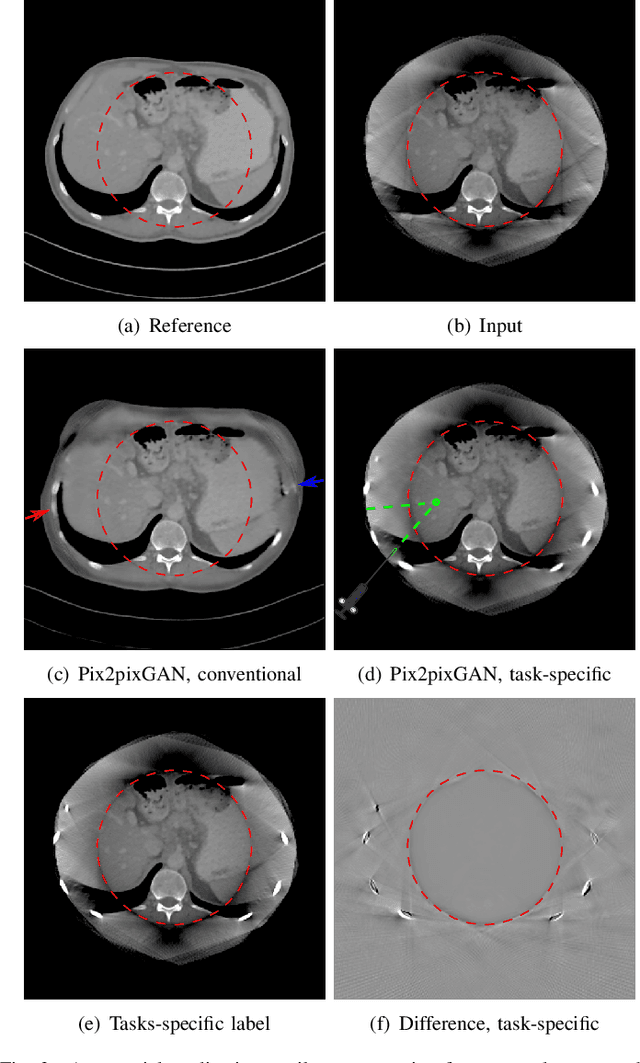
Cone-beam computed tomography (CBCT) is widely used in interventional surgeries and radiation oncology. Due to the limited size of flat-panel detectors, anatomical structures might be missing outside the limited field-of-view (FOV), which restricts the clinical applications of CBCT systems. Recently, deep learning methods have been proposed to extend the FOV for multi-slice CT systems. However, in mobile CBCT system with a smaller FOV size, projection data is severely truncated and it is challenging for a network to restore all missing structures outside the FOV. In some applications, only certain structures outside the FOV are of interest, e.g., ribs in needle path planning for liver/lung cancer diagnosis. Therefore, a task-specific data preparation method is proposed in this work, which automatically let the network focus on structures of interest instead of all the structures. Our preliminary experiment shows that Pix2pixGAN with a conventional training has the risk to reconstruct false positive and false negative rib structures from severely truncated CBCT data, whereas Pix2pixGAN with the proposed task-specific training can reconstruct all the ribs reliably. The proposed method is promising to empower CBCT with more clinical applications.
Fine-Tuning a Local LLaMA-3 Large Language Model for Automated Privacy-Preserving Physician Letter Generation in Radiation Oncology
Aug 20, 2024



Generating physician letters is a time-consuming task in daily clinical practice. This study investigates local fine-tuning of large language models (LLMs), specifically LLaMA models, for physician letter generation in a privacy-preserving manner within the field of radiation oncology. Our findings demonstrate that base LLaMA models, without fine-tuning, are inadequate for effectively generating physician letters. The QLoRA algorithm provides an efficient method for local intra-institutional fine-tuning of LLMs with limited computational resources (i.e., a single 48 GB GPU workstation within the hospital). The fine-tuned LLM successfully learns radiation oncology-specific information and generates physician letters in an institution-specific style. ROUGE scores of the generated summary reports highlight the superiority of the 8B LLaMA-3 model over the 13B LLaMA-2 model. Further multidimensional physician evaluations of 10 cases reveal that, although the fine-tuned LLaMA-3 model has limited capacity to generate content beyond the provided input data, it successfully generates salutations, diagnoses and treatment histories, recommendations for further treatment, and planned schedules. Overall, clinical benefit was rated highly by the clinical experts (average score of 3.44 on a 4-point scale). With careful physician review and correction, automated LLM-based physician letter generation has significant practical value.
Comprehensive Multimodal Deep Learning Survival Prediction Enabled by a Transformer Architecture: A Multicenter Study in Glioblastoma
May 21, 2024Background: This research aims to improve glioblastoma survival prediction by integrating MR images, clinical and molecular-pathologic data in a transformer-based deep learning model, addressing data heterogeneity and performance generalizability. Method: We propose and evaluate a transformer-based non-linear and non-proportional survival prediction model. The model employs self-supervised learning techniques to effectively encode the high-dimensional MRI input for integration with non-imaging data using cross-attention. To demonstrate model generalizability, the model is assessed with the time-dependent concordance index (Cdt) in two training setups using three independent public test sets: UPenn-GBM, UCSF-PDGM, and RHUH-GBM, each comprising 378, 366, and 36 cases, respectively. Results: The proposed transformer model achieved promising performance for imaging as well as non-imaging data, effectively integrating both modalities for enhanced performance (UPenn-GBM test-set, imaging Cdt 0.645, multimodal Cdt 0.707) while outperforming state-of-the-art late-fusion 3D-CNN-based models. Consistent performance was observed across the three independent multicenter test sets with Cdt values of 0.707 (UPenn-GBM, internal test set), 0.672 (UCSF-PDGM, first external test set) and 0.618 (RHUH-GBM, second external test set). The model achieved significant discrimination between patients with favorable and unfavorable survival for all three datasets (logrank p 1.9\times{10}^{-8}, 9.7\times{10}^{-3}, and 1.2\times{10}^{-2}). Conclusions: The proposed transformer-based survival prediction model integrates complementary information from diverse input modalities, contributing to improved glioblastoma survival prediction compared to state-of-the-art methods. Consistent performance was observed across institutions supporting model generalizability.
Multicenter Privacy-Preserving Model Training for Deep Learning Brain Metastases Autosegmentation
May 17, 2024



Objectives: This work aims to explore the impact of multicenter data heterogeneity on deep learning brain metastases (BM) autosegmentation performance, and assess the efficacy of an incremental transfer learning technique, namely learning without forgetting (LWF), to improve model generalizability without sharing raw data. Materials and methods: A total of six BM datasets from University Hospital Erlangen (UKER), University Hospital Zurich (USZ), Stanford, UCSF, NYU and BraTS Challenge 2023 on BM segmentation were used for this evaluation. First, the multicenter performance of a convolutional neural network (DeepMedic) for BM autosegmentation was established for exclusive single-center training and for training on pooled data, respectively. Subsequently bilateral collaboration was evaluated, where a UKER pretrained model is shared to another center for further training using transfer learning (TL) either with or without LWF. Results: For single-center training, average F1 scores of BM detection range from 0.625 (NYU) to 0.876 (UKER) on respective single-center test data. Mixed multicenter training notably improves F1 scores at Stanford and NYU, with negligible improvement at other centers. When the UKER pretrained model is applied to USZ, LWF achieves a higher average F1 score (0.839) than naive TL (0.570) and single-center training (0.688) on combined UKER and USZ test data. Naive TL improves sensitivity and contouring accuracy, but compromises precision. Conversely, LWF demonstrates commendable sensitivity, precision and contouring accuracy. When applied to Stanford, similar performance was observed. Conclusion: Data heterogeneity results in varying performance in BM autosegmentation, posing challenges to model generalizability. LWF is a promising approach to peer-to-peer privacy-preserving model training.
Fourier PD and PDUNet: Complex-valued networks to speed-up MR Thermometry during Hypterthermia
Oct 02, 2023Hyperthermia (HT) in combination with radio- and/or chemotherapy has become an accepted cancer treatment for distinct solid tumour entities. In HT, tumour tissue is exogenously heated to temperatures of 39 to 43 $\degree$C for 60 minutes. Temperature monitoring can be performed noninvasively using dynamic magnetic resonance imaging (MRI). However, the slow nature of MRI leads to motion artefacts in the images due to the movements of patients during image acquisition time. By discarding parts of the data, the speed of the acquisition can be increased - known as Undersampling. However, due to the invalidation of the Nyquist criterion, the acquired images have lower resolution and can also produce artefacts. The aim of this work was, therefore, to reconstruct highly undersampled MR thermometry acquisitions with better resolution and with less artefacts compared to conventional techniques like compressed sensing. The use of deep learning in the medical field has emerged in recent times, and various studies have shown that deep learning has the potential to solve inverse problems such as MR image reconstruction. However, most of the published work only focusses on the magnitude images, while the phase images are ignored, which are fundamental requirements for MR thermometry. This work, for the first time ever, presents deep learning based solutions for reconstructing undersampled MR thermometry data. Two different deep learning models have been employed here, the Fourier Primal-Dual network and Fourier Primal-Dual UNet, to reconstruct highly undersampled complex images of MR thermometry. It was observed that the method was able to reduce the temperature difference between the undersampled MRIs and the fully sampled MRIs from 1.5 $\degree$C to 0.5 $\degree$C.
A Survey of Incremental Transfer Learning: Combining Peer-to-Peer Federated Learning and Domain Incremental Learning for Multicenter Collaboration
Sep 29, 2023



Due to data privacy constraints, data sharing among multiple clinical centers is restricted, which impedes the development of high performance deep learning models from multicenter collaboration. Naive weight transfer methods share intermediate model weights without raw data and hence can bypass data privacy restrictions. However, performance drops are typically observed when the model is transferred from one center to the next because of the forgetting problem. Incremental transfer learning, which combines peer-to-peer federated learning and domain incremental learning, can overcome the data privacy issue and meanwhile preserve model performance by using continual learning techniques. In this work, a conventional domain/task incremental learning framework is adapted for incremental transfer learning. A comprehensive survey on the efficacy of different regularization-based continual learning methods for multicenter collaboration is performed. The influences of data heterogeneity, classifier head setting, network optimizer, model initialization, center order, and weight transfer type have been investigated thoroughly. Our framework is publicly accessible to the research community for further development.
Deep Learning for Cancer Prognosis Prediction Using Portrait Photos by StyleGAN Embedding
Jun 28, 2023

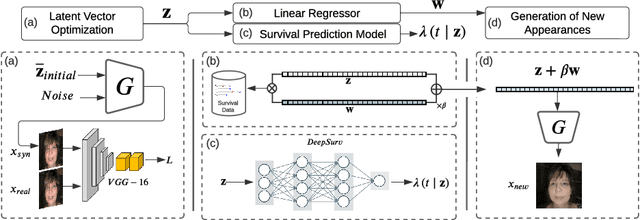

Survival prediction for cancer patients is critical for optimal treatment selection and patient management. Current patient survival prediction methods typically extract survival information from patients' clinical record data or biological and imaging data. In practice, experienced clinicians can have a preliminary assessment of patients' health status based on patients' observable physical appearances, which are mainly facial features. However, such assessment is highly subjective. In this work, the efficacy of objectively capturing and using prognostic information contained in conventional portrait photographs using deep learning for survival predication purposes is investigated for the first time. A pre-trained StyleGAN2 model is fine-tuned on a custom dataset of our cancer patients' photos to empower its generator with generative ability suitable for patients' photos. The StyleGAN2 is then used to embed the photographs to its highly expressive latent space. Utilizing the state-of-the-art survival analysis models and based on StyleGAN's latent space photo embeddings, this approach achieved a C-index of 0.677, which is notably higher than chance and evidencing the prognostic value embedded in simple 2D facial images. In addition, thanks to StyleGAN's interpretable latent space, our survival prediction model can be validated for relying on essential facial features, eliminating any biases from extraneous information like clothing or background. Moreover, a health attribute is obtained from regression coefficients, which has important potential value for patient care.
Benchmarking ChatGPT-4 on ACR Radiation Oncology In-Training Exam (TXIT): Potentials and Challenges for AI-Assisted Medical Education and Decision Making in Radiation Oncology
Apr 24, 2023
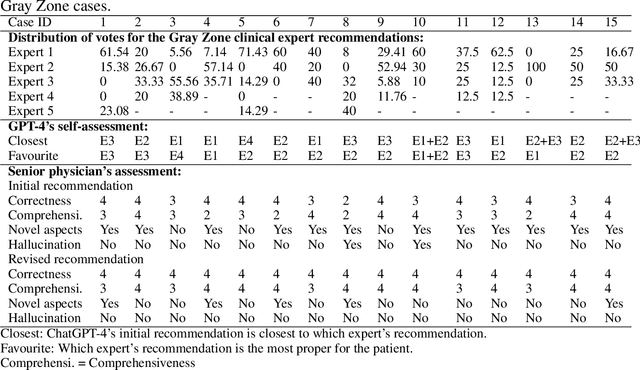

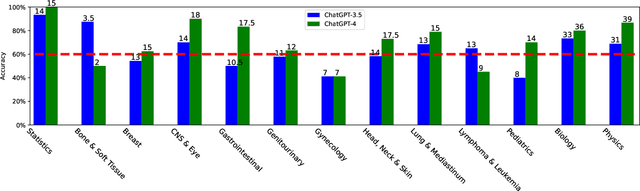
The potential of large language models in medicine for education and decision making purposes has been demonstrated as they achieve decent scores on medical exams such as the United States Medical Licensing Exam (USMLE) and the MedQA exam. In this work, we evaluate the performance of ChatGPT-3.5 and ChatGPT-4 in the specialized field of radiation oncology using the 38th American College of Radiology (ACR) radiation oncology in-training exam (TXIT). ChatGPT-3.5 and ChatGPT-4 have achieved the scores of 63.65% and 74.57%, respectively, highlighting the advantage of the latest ChatGPT-4 model. Based on the TXIT exam, ChatGPT-4's strong and weak areas in radiation oncology are identified to some extent. Specifically, ChatGPT-4 demonstrates good knowledge of statistics, CNS & eye, pediatrics, biology, and physics but has limitations in bone & soft tissue and gynecology, as per the ACR knowledge domain. Regarding clinical care paths, ChatGPT-4 performs well in diagnosis, prognosis, and toxicity but lacks proficiency in topics related to brachytherapy and dosimetry, as well as in-depth questions from clinical trials. While ChatGPT-4 is not yet suitable for clinical decision making in radiation oncology, it has the potential to assist in medical education for the general public and cancer patients. With further fine-tuning, it could assist radiation oncologists in recommending treatment decisions for challenging clinical cases based on the latest guidelines and the existing gray zone database.