 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking ChatGPT-4 on ACR Radiation Oncology In-Training Exam (TXIT): Potentials and Challenges for AI-Assisted Medical Education and Decision Making in Radiation Oncology
Apr 24, 2023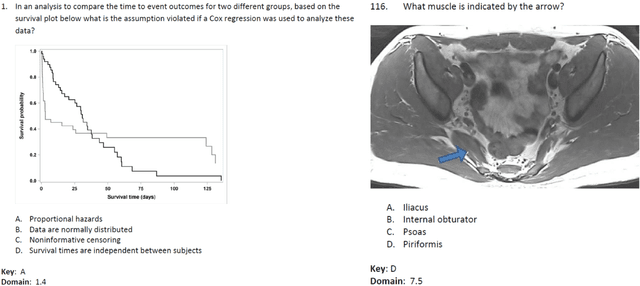
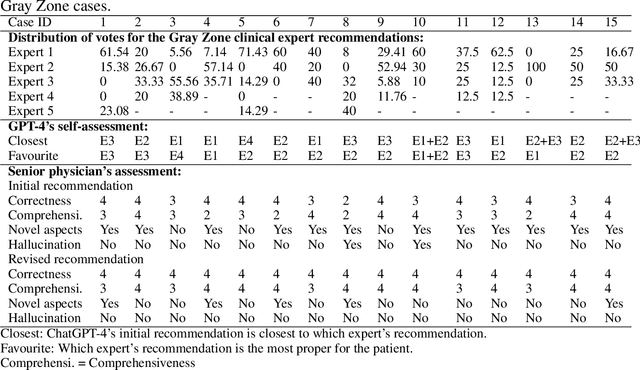

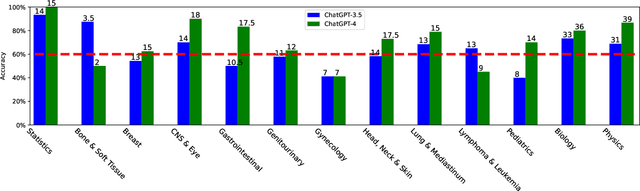
The potential of large language models in medicine for education and decision making purposes has been demonstrated as they achieve decent scores on medical exams such as the United States Medical Licensing Exam (USMLE) and the MedQA exam. In this work, we evaluate the performance of ChatGPT-3.5 and ChatGPT-4 in the specialized field of radiation oncology using the 38th American College of Radiology (ACR) radiation oncology in-training exam (TXIT). ChatGPT-3.5 and ChatGPT-4 have achieved the scores of 63.65% and 74.57%, respectively, highlighting the advantage of the latest ChatGPT-4 model. Based on the TXIT exam, ChatGPT-4's strong and weak areas in radiation oncology are identified to some extent. Specifically, ChatGPT-4 demonstrates good knowledge of statistics, CNS & eye, pediatrics, biology, and physics but has limitations in bone & soft tissue and gynecology, as per the ACR knowledge domain. Regarding clinical care paths, ChatGPT-4 performs well in diagnosis, prognosis, and toxicity but lacks proficiency in topics related to brachytherapy and dosimetry, as well as in-depth questions from clinical trials. While ChatGPT-4 is not yet suitable for clinical decision making in radiation oncology, it has the potential to assist in medical education for the general public and cancer patients. With further fine-tuning, it could assist radiation oncologists in recommending treatment decisions for challenging clinical cases based on the latest guidelines and the existing gray zone database.
The Segment Anything foundation model achieves favorable brain tumor autosegmentation accuracy on MRI to support radiotherapy treatment planning
Apr 16, 2023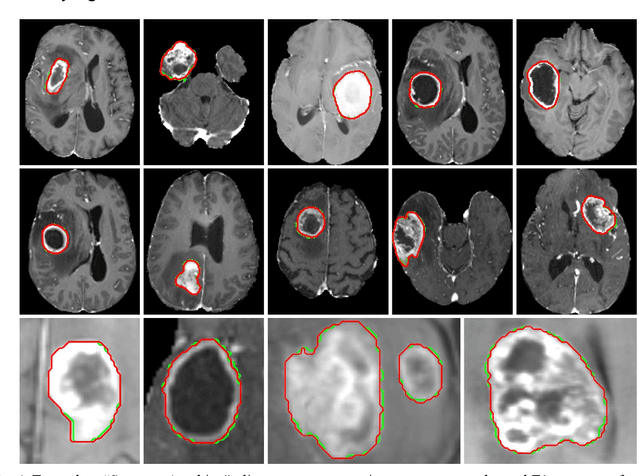
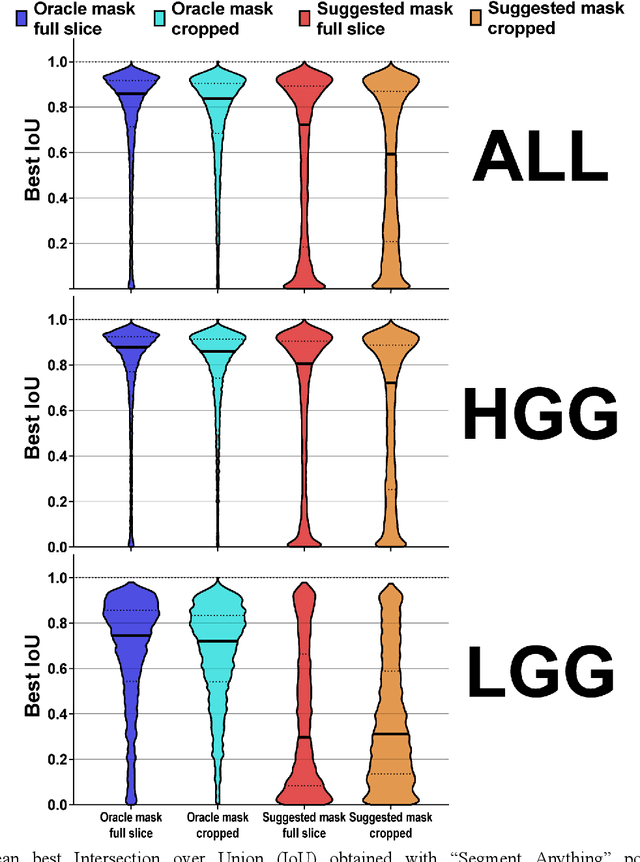
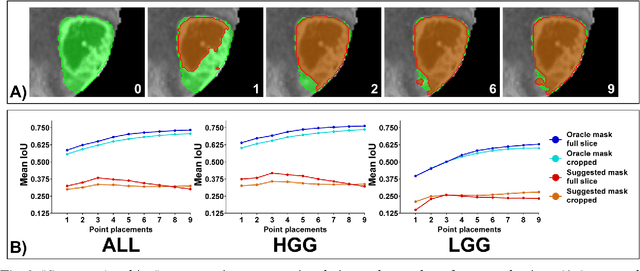
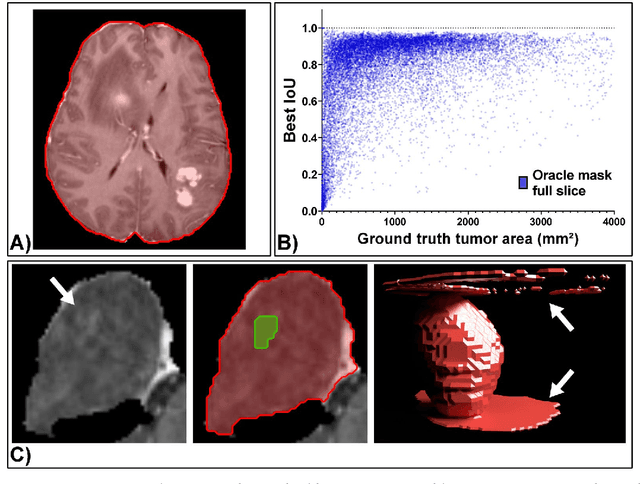
Background: Tumor segmentation in MRI is crucial in radiotherapy (RT) treatment planning for brain tumor patients. Segment anything (SA), a novel promptable foundation model for autosegmentation, has shown high accuracy for multiple segmentation tasks but was not evaluated on medical datasets yet. Methods: SA was evaluated in a point-to-mask task for glioma brain tumor autosegmentation on 16744 transversal slices from 369 MRI datasets (BraTS 2020). Up to 9 point prompts were placed per slice. Tumor core (enhancing tumor + necrotic core) was segmented on contrast-enhanced T1w sequences. Out of the 3 masks predicted by SA, accuracy was evaluated for the mask with the highest calculated IoU (oracle mask) and with highest model predicted IoU (suggested mask). In addition to assessing SA on whole MRI slices, SA was also evaluated on images cropped to the tumor (max. 3D extent + 2 cm). Results: Mean best IoU (mbIoU) using oracle mask on full MRI slices was 0.762 (IQR 0.713-0.917). Best 2D mask was achieved after a mean of 6.6 point prompts (IQR 5-9). Segmentation accuracy was significantly better for high- compared to low-grade glioma cases (mbIoU 0.789 vs. 0.668). Accuracy was worse using MRI slices cropped to the tumor (mbIoU 0.759) and was much worse using suggested mask (full slices 0.572). For all experiments, accuracy was low on peripheral slices with few tumor voxels (mbIoU, <300: 0.537 vs. >=300: 0.841). Stacking best oracle segmentations from full axial MRI slices, mean 3D DSC for tumor core was 0.872, which was improved to 0.919 by combining axial, sagittal and coronal masks. Conclusions: The Segment Anything foundation model, while trained on photos, can achieve high zero-shot accuracy for glioma brain tumor segmentation on MRI slices. The results suggest that Segment Anything can accelerate and facilitate RT treatment planning, when properly integrated in a clinical application.