 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking ChatGPT-4 on ACR Radiation Oncology In-Training Exam (TXIT): Potentials and Challenges for AI-Assisted Medical Education and Decision Making in Radiation Oncology
Paper and Code

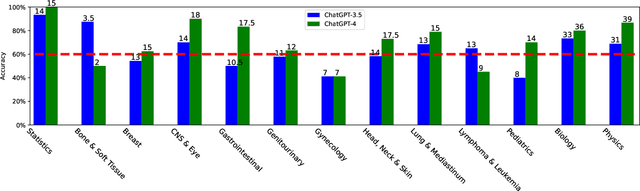
The potential of large language models in medicine for education and decision making purposes has been demonstrated as they achieve decent scores on medical exams such as the United States Medical Licensing Exam (USMLE) and the MedQA exam. In this work, we evaluate the performance of ChatGPT-3.5 and ChatGPT-4 in the specialized field of radiation oncology using the 38th American College of Radiology (ACR) radiation oncology in-training exam (TXIT). ChatGPT-3.5 and ChatGPT-4 have achieved the scores of 63.65% and 74.57%, respectively, highlighting the advantage of the latest ChatGPT-4 model. Based on the TXIT exam, ChatGPT-4's strong and weak areas in radiation oncology are identified to some extent. Specifically, ChatGPT-4 demonstrates good knowledge of statistics, CNS & eye, pediatrics, biology, and physics but has limitations in bone & soft tissue and gynecology, as per the ACR knowledge domain. Regarding clinical care paths, ChatGPT-4 performs well in diagnosis, prognosis, and toxicity but lacks proficiency in topics related to brachytherapy and dosimetry, as well as in-depth questions from clinical trials. While ChatGPT-4 is not yet suitable for clinical decision making in radiation oncology, it has the potential to assist in medical education for the general public and cancer patients. With further fine-tuning, it could assist radiation oncologists in recommending treatment decisions for challenging clinical cases based on the latest guidelines and the existing gray zone database.