 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Out-of-Distribution Generalization Capabilities of DNN-based Encoding Models for the Ventral Visual Cortex
Jun 16, 2024



We characterized the generalization capabilities of DNN-based encoding models when predicting neuronal responses from the visual cortex. We collected \textit{MacaqueITBench}, a large-scale dataset of neural population responses from the macaque inferior temporal (IT) cortex to over $300,000$ images, comprising $8,233$ unique natural images presented to seven monkeys over $109$ sessions. Using \textit{MacaqueITBench}, we investigated the impact of distribution shifts on models predicting neural activity by dividing the images into Out-Of-Distribution (OOD) train and test splits. The OOD splits included several different image-computable types including image contrast, hue, intensity, temperature, and saturation. Compared to the performance on in-distribution test images -- the conventional way these models have been evaluated -- models performed worse at predicting neuronal responses to out-of-distribution images, retaining as little as $20\%$ of the performance on in-distribution test images. The generalization performance under OOD shifts can be well accounted by a simple image similarity metric -- the cosine distance between image representations extracted from a pre-trained object recognition model is a strong predictor of neural predictivity under different distribution shifts. The dataset of images, neuronal firing rate recordings, and computational benchmarks are hosted publicly at: https://bit.ly/3zeutVd.
Look Around! Unexpected gains from training on environments in the vicinity of the target
Jan 29, 2024



Solutions to Markov Decision Processes (MDP) are often very sensitive to state transition probabilities. As the estimation of these probabilities is often inaccurate in practice, it is important to understand when and how Reinforcement Learning (RL) agents generalize when transition probabilities change. Here we present a new methodology to evaluate such generalization of RL agents under small shifts in the transition probabilities. Specifically, we evaluate agents in new environments (MDPs) in the vicinity of the training MDP created by adding quantifiable, parametric noise into the transition function of the training MDP. We refer to this process as Noise Injection, and the resulting environments as $\delta$-environments. This process allows us to create controlled variations of the same environment with the level of the noise serving as a metric of distance between environments. Conventional wisdom suggests that training and testing on the same MDP should yield the best results. However, we report several cases of the opposite -- when targeting a specific environment, training the agent in an alternative noise setting can yield superior outcomes. We showcase this phenomenon across $60$ different variations of ATARI games, including PacMan, Pong, and Breakout.
Human or Machine? Turing Tests for Vision and Language
Nov 23, 2022As AI algorithms increasingly participate in daily activities that used to be the sole province of humans, we are inevitably called upon to consider how much machines are really like us. To address this question, we turn to the Turing test and systematically benchmark current AIs in their abilities to imitate humans. We establish a methodology to evaluate humans versus machines in Turing-like tests and systematically evaluate a representative set of selected domains, parameters, and variables. The experiments involved testing 769 human agents, 24 state-of-the-art AI agents, 896 human judges, and 8 AI judges, in 21,570 Turing tests across 6 tasks encompassing vision and language modalities. Surprisingly, the results reveal that current AIs are not far from being able to impersonate human judges across different ages, genders, and educational levels in complex visual and language challenges. In contrast, simple AI judges outperform human judges in distinguishing human answers versus machine answers. The curated large-scale Turing test datasets introduced here and their evaluation metrics provide valuable insights to assess whether an agent is human or not. The proposed formulation to benchmark human imitation ability in current AIs paves a way for the research community to expand Turing tests to other research areas and conditions. All of source code and data are publicly available at https://tinyurl.com/8x8nha7p
What makes domain generalization hard?
Jun 15, 2022
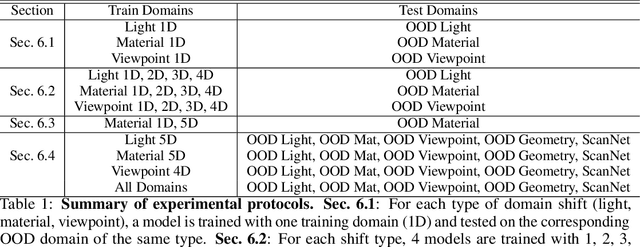
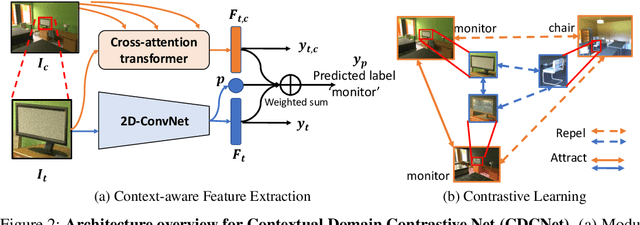
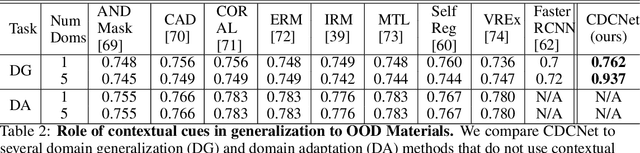
While several methodologies have been proposed for the daunting task of domain generalization, understanding what makes this task challenging has received little attention. Here we present SemanticDG (Semantic Domain Generalization): a benchmark with 15 photo-realistic domains with the same geometry, scene layout and camera parameters as the popular 3D ScanNet dataset, but with controlled domain shifts in lighting, materials, and viewpoints. Using this benchmark, we investigate the impact of each of these semantic shifts on generalization independently. Visual recognition models easily generalize to novel lighting, but struggle with distribution shifts in materials and viewpoints. Inspired by human vision, we hypothesize that scene context can serve as a bridge to help models generalize across material and viewpoint domain shifts and propose a context-aware vision transformer along with a contrastive loss over material and viewpoint changes to address these domain shifts. Our approach (dubbed as CDCNet) outperforms existing domain generalization methods by over an 18% margin. As a critical benchmark, we also conduct psychophysics experiments and find that humans generalize equally well across lighting, materials and viewpoints. The benchmark and computational model introduced here help understand the challenges associated with generalization across domains and provide initial steps towards extrapolation to semantic distribution shifts. We include all data and source code in the supplement.
Three approaches to facilitate DNN generalization to objects in out-of-distribution orientations and illuminations: late-stopping, tuning batch normalization and invariance loss
Oct 30, 2021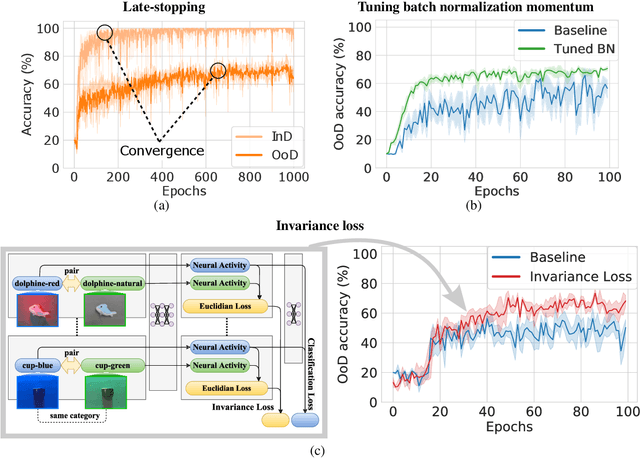



The training data distribution is often biased towards objects in certain orientations and illumination conditions. While humans have a remarkable capability of recognizing objects in out-of-distribution (OoD) orientations and illuminations, Deep Neural Networks (DNNs) severely suffer in this case, even when large amounts of training examples are available. In this paper, we investigate three different approaches to improve DNNs in recognizing objects in OoD orientations and illuminations. Namely, these are (i) training much longer after convergence of the in-distribution (InD) validation accuracy, i.e., late-stopping, (ii) tuning the momentum parameter of the batch normalization layers, and (iii) enforcing invariance of the neural activity in an intermediate layer to orientation and illumination conditions. Each of these approaches substantially improves the DNN's OoD accuracy (more than 20% in some cases). We report results in four datasets: two datasets are modified from the MNIST and iLab datasets, and the other two are novel (one of 3D rendered cars and another of objects taken from various controlled orientations and illumination conditions). These datasets allow to study the effects of different amounts of bias and are challenging as DNNs perform poorly in OoD conditions. Finally, we demonstrate that even though the three approaches focus on different aspects of DNNs, they all tend to lead to the same underlying neural mechanism to enable OoD accuracy gains -- individual neurons in the intermediate layers become more selective to a category and also invariant to OoD orientations and illuminations.
To Which Out-Of-Distribution Object Orientations Are DNNs Capable of Generalizing?
Sep 28, 2021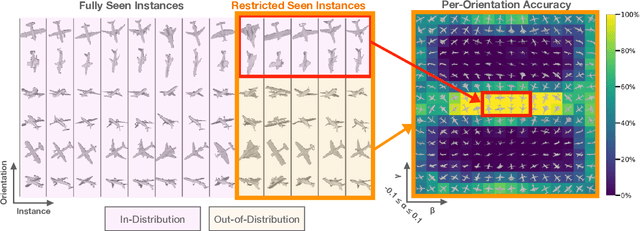
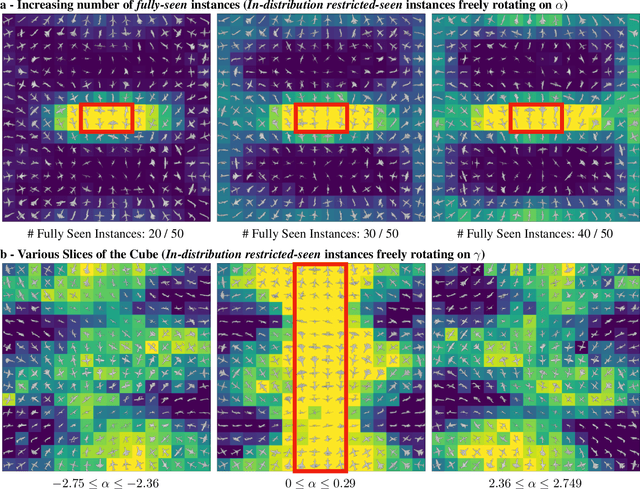

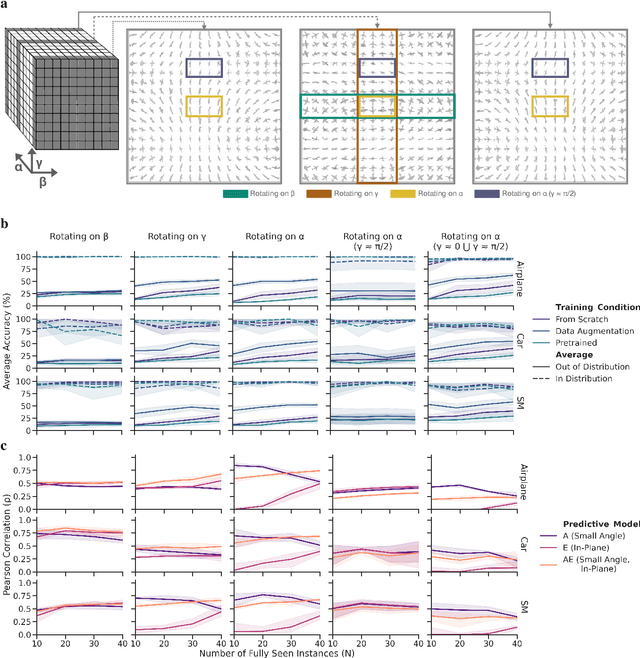
The capability of Deep Neural Networks (DNNs) to recognize objects in orientations outside the distribution of the training data, ie. out-of-distribution (OoD) orientations, is not well understood. For humans, behavioral studies showed that recognition accuracy varies across OoD orientations, where generalization is much better for some orientations than for others. In contrast, for DNNs, it remains unknown how generalization abilities are distributed among OoD orientations. In this paper, we investigate the limitations of DNNs' generalization capacities by systematically inspecting patterns of success and failure of DNNs across OoD orientations. We use an intuitive and controlled, yet challenging learning paradigm, in which some instances of an object category are seen at only a few geometrically restricted orientations, while other instances are seen at all orientations. The effect of data diversity is also investigated by increasing the number of instances seen at all orientations in the training set. We present a comprehensive analysis of DNNs' generalization abilities and limitations for representative architectures (ResNet, Inception, DenseNet and CORnet). Our results reveal an intriguing pattern -- DNNs are only capable of generalizing to instances of objects that appear like 2D, ie. in-plane, rotations of in-distribution orientations.
Small in-distribution changes in 3D perspective and lighting fool both CNNs and Transformers
Jun 30, 2021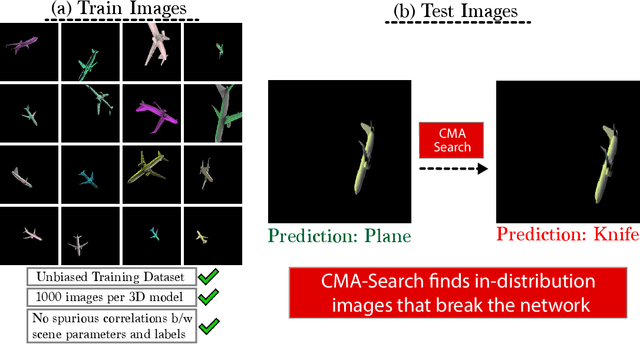


Neural networks are susceptible to small transformations including 2D rotations and shifts, image crops, and even changes in object colors. This is often attributed to biases in the training dataset, and the lack of 2D shift-invariance due to not respecting the sampling theorem. In this paper, we challenge this hypothesis by training and testing on unbiased datasets, and showing that networks are brittle to both small 3D perspective changes and lighting variations which cannot be explained by dataset bias or lack of shift-invariance. To find these in-distribution errors, we introduce an evolution strategies (ES) based approach, which we call CMA-Search. Despite training with a large-scale (0.5 million images), unbiased dataset of camera and light variations, in over 71% cases CMA-Search can find camera parameters in the vicinity of a correctly classified image which lead to in-distribution misclassifications with < 3.6% change in parameters. With lighting changes, CMA-Search finds misclassifications in 33% cases with < 11.6% change in parameters. Finally, we extend this method to find misclassifications in the vicinity of ImageNet images for both ResNet and OpenAI's CLIP model.
When Pigs Fly: Contextual Reasoning in Synthetic and Natural Scenes
Apr 06, 2021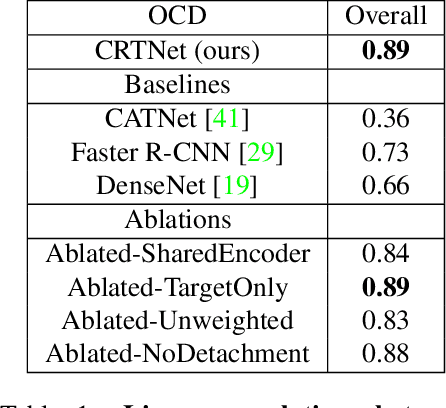
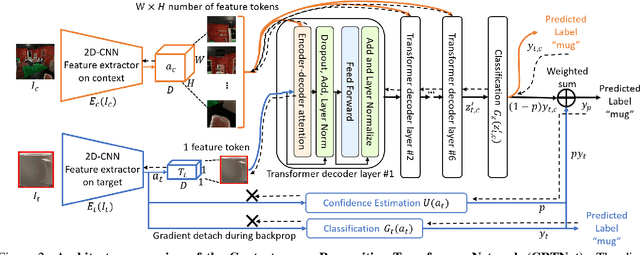
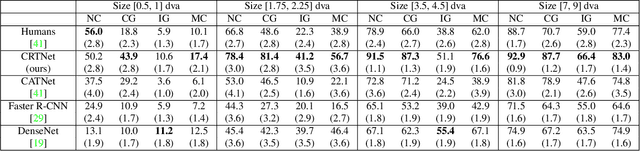
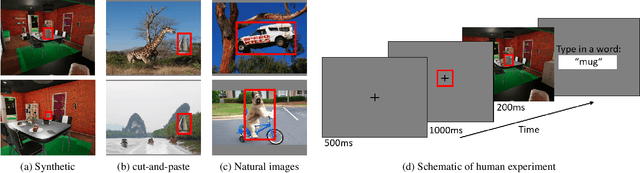
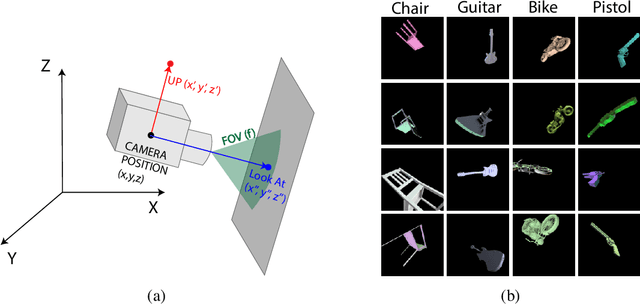
Context is of fundamental importance to both human and machine vision -- an object in the air is more likely to be an airplane, than a pig. The rich notion of context incorporates several aspects including physics rules, statistical co-occurrences, and relative object sizes, among others. While previous works have crowd-sourced out-of-context photographs from the web to study scene context, controlling the nature and extent of contextual violations has been an extremely daunting task. Here we introduce a diverse, synthetic Out-of-Context Dataset (OCD) with fine-grained control over scene context. By leveraging a 3D simulation engine, we systematically control the gravity, object co-occurrences and relative sizes across 36 object categories in a virtual household environment. We then conduct a series of experiments to gain insights into the impact of contextual cues on both human and machine vision using OCD. First, we conduct psycho-physics experiments to establish a human benchmark for out-of-context recognition, and then compare it with state-of-the-art computer vision models to quantify the gap between the two. Finally, we propose a context-aware recognition transformer model, fusing object and contextual information via multi-head attention. Our model captures useful information for contextual reasoning, enabling human-level performance and significantly better robustness in out-of-context conditions compared to baseline models across OCD and other existing out-of-context natural image datasets. All source code and data are publicly available https://github.com/kreimanlab/WhenPigsFlyContext.
On the Capability of Neural Networks to Generalize to Unseen Category-Pose Combinations
Jul 15, 2020
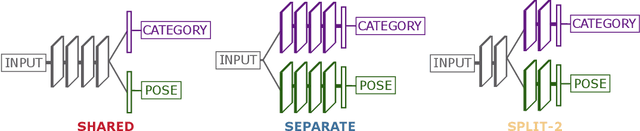
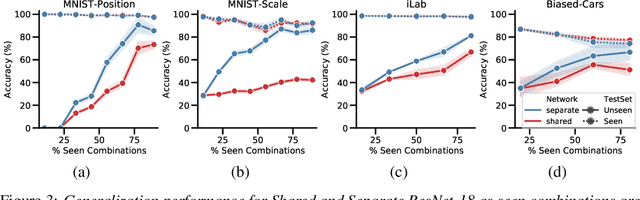
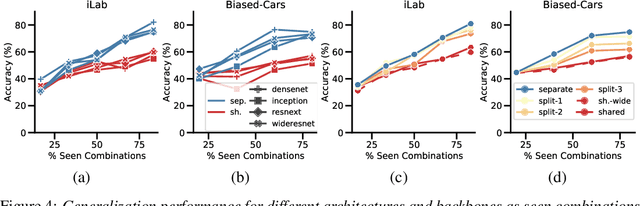
Recognizing an object's category and pose lies at the heart of visual understanding. Recent works suggest that deep neural networks (DNNs) often fail to generalize to category-pose combinations not seen during training. However, it is unclear when and how such generalization may be possible. Does the number of combinations seen during training impact generalization? Is it better to learn category and pose in separate networks, or in a single shared network? Furthermore, what are the neural mechanisms that drive the network's generalization? In this paper, we answer these questions by analyzing state-of-the-art DNNs trained to recognize both object category and pose (position, scale, and 3D viewpoint) with quantitative control over the number of category-pose combinations seen during training. We also investigate the emergence of two types of specialized neurons that can explain generalization to unseen combinations---neurons selective to category and invariant to pose, and vice versa. We perform experiments on MNIST extended with position or scale, the iLab dataset with vehicles at different viewpoints, and a challenging new dataset for car model recognition and viewpoint estimation that we introduce in this paper, the Biased-Cars dataset. Our results demonstrate that as the number of combinations seen during training increases, networks generalize better to unseen category-pose combinations, facilitated by an increase in the selectivity and invariance of individual neurons. We find that learning category and pose in separate networks compared to a shared one leads to an increase in such selectivity and invariance, as separate networks are not forced to preserve information about both category and pose. This enables separate networks to significantly outperform shared ones at predicting unseen category-pose combinations.
Synthetically Trained Icon Proposals for Parsing and Summarizing Infographics
Jul 27, 2018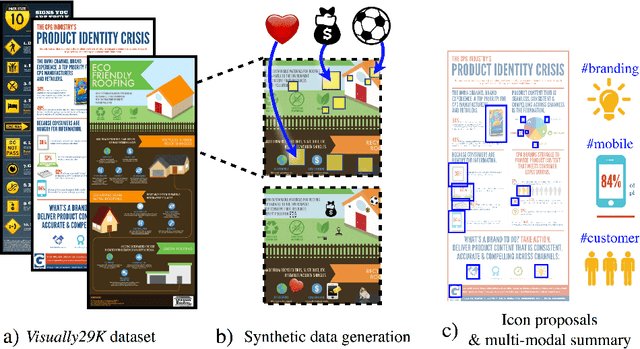
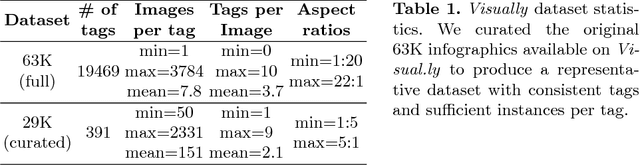

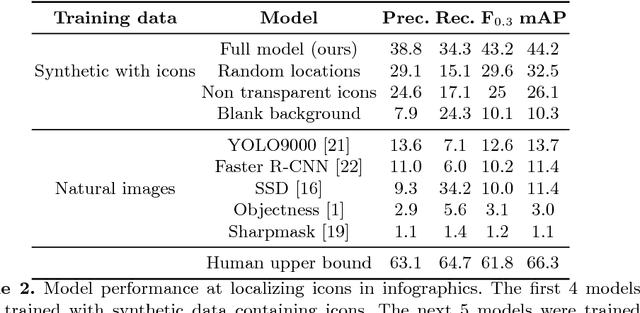
Widely used in news, business, and educational media, infographics are handcrafted to effectively communicate messages about complex and often abstract topics including `ways to conserve the environment' and `understanding the financial crisis'. Composed of stylistically and semantically diverse visual and textual elements, infographics pose new challenges for computer vision. While automatic text extraction works well on infographics, computer vision approaches trained on natural images fail to identify the stand-alone visual elements in infographics, or `icons'. To bridge this representation gap, we propose a synthetic data generation strategy: we augment background patches in infographics from our Visually29K dataset with Internet-scraped icons which we use as training data for an icon proposal mechanism. On a test set of 1K annotated infographics, icons are located with 38% precision and 34% recall (the best model trained with natural images achieves 14% precision and 7% recall). Combining our icon proposals with icon classification and text extraction, we present a multi-modal summarization application. Our application takes an infographic as input and automatically produces text tags and visual hashtags that are textually and visually representative of the infographic's topics respectively.