 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Out-of-Distribution Generalization Capabilities of DNN-based Encoding Models for the Ventral Visual Cortex
Jun 16, 2024



We characterized the generalization capabilities of DNN-based encoding models when predicting neuronal responses from the visual cortex. We collected \textit{MacaqueITBench}, a large-scale dataset of neural population responses from the macaque inferior temporal (IT) cortex to over $300,000$ images, comprising $8,233$ unique natural images presented to seven monkeys over $109$ sessions. Using \textit{MacaqueITBench}, we investigated the impact of distribution shifts on models predicting neural activity by dividing the images into Out-Of-Distribution (OOD) train and test splits. The OOD splits included several different image-computable types including image contrast, hue, intensity, temperature, and saturation. Compared to the performance on in-distribution test images -- the conventional way these models have been evaluated -- models performed worse at predicting neuronal responses to out-of-distribution images, retaining as little as $20\%$ of the performance on in-distribution test images. The generalization performance under OOD shifts can be well accounted by a simple image similarity metric -- the cosine distance between image representations extracted from a pre-trained object recognition model is a strong predictor of neural predictivity under different distribution shifts. The dataset of images, neuronal firing rate recordings, and computational benchmarks are hosted publicly at: https://bit.ly/3zeutVd.
Look Twice: A Computational Model of Return Fixations across Tasks and Species
Jan 05, 2021
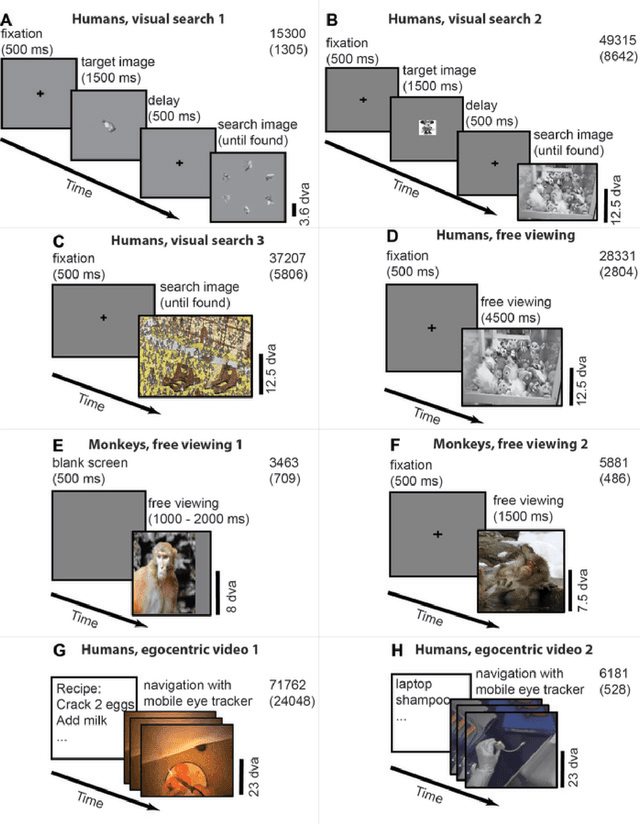
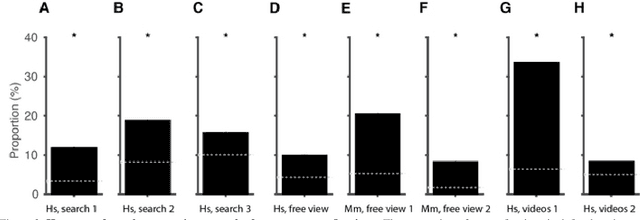
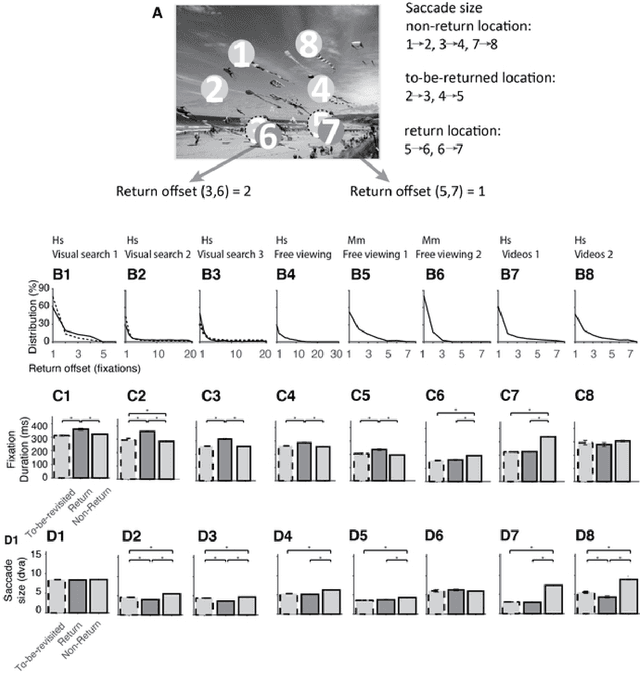
Saccadic eye movements allow animals to bring different parts of an image into high-resolution. During free viewing, inhibition of return incentivizes exploration by discouraging previously visited locations. Despite this inhibition, here we show that subjects make frequent return fixations. We systematically studied a total of 44,328 return fixations out of 217,440 fixations across different tasks, in monkeys and humans, and in static images or egocentric videos. The ubiquitous return fixations were consistent across subjects, tended to occur within short offsets, and were characterized by longer duration than non-return fixations. The locations of return fixations corresponded to image areas of higher saliency and higher similarity to the sought target during visual search tasks. We propose a biologically-inspired computational model that capitalizes on a deep convolutional neural network for object recognition to predict a sequence of fixations. Given an input image, the model computes four maps that constrain the location of the next saccade: a saliency map, a target similarity map, a saccade size map, and a memory map. The model exhibits frequent return fixations and approximates the properties of return fixations across tasks and species. The model provides initial steps towards capturing the trade-off between exploitation of informative image locations combined with exploration of novel image locations during scene viewing.
Adversarial images for the primate brain
Nov 11, 2020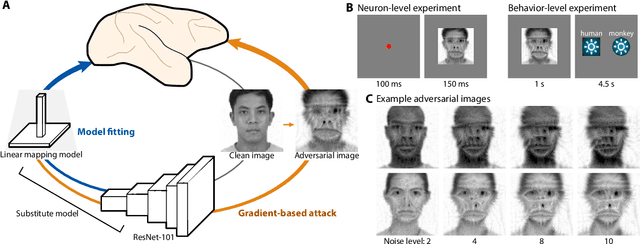
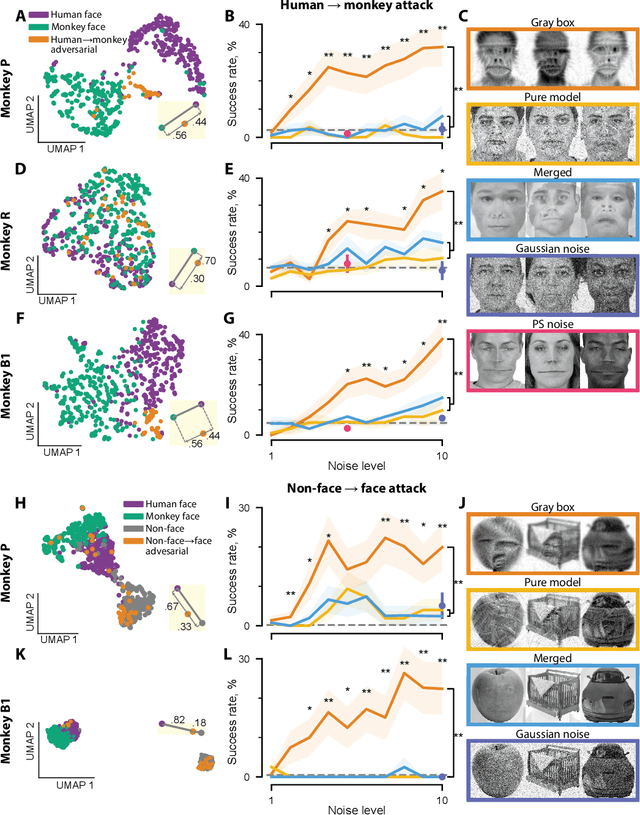
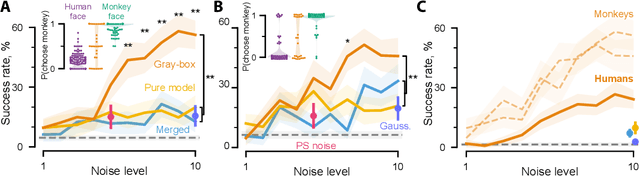
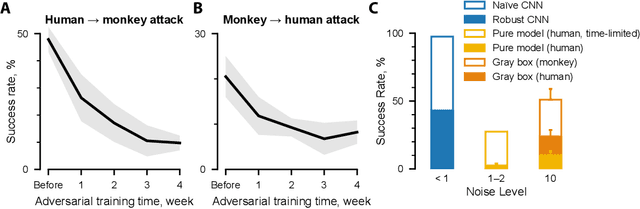
Deep artificial neural networks have been proposed as a model of primate vision. However, these networks are vulnerable to adversarial attacks, whereby introducing minimal noise can fool networks into misclassifying images. Primate vision is thought to be robust to such adversarial images. We evaluated this assumption by designing adversarial images to fool primate vision. To do so, we first trained a model to predict responses of face-selective neurons in macaque inferior temporal cortex. Next, we modified images, such as human faces, to match their model-predicted neuronal responses to a target category, such as monkey faces. These adversarial images elicited neuronal responses similar to the target category. Remarkably, the same images fooled monkeys and humans at the behavioral level. These results challenge fundamental assumptions about the similarity between computer and primate vision and show that a model of neuronal activity can selectively direct primate visual behavior.
Gradient-free activation maximization for identifying effective stimuli
May 01, 2019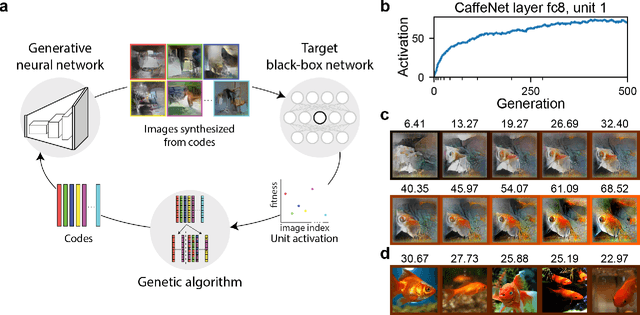
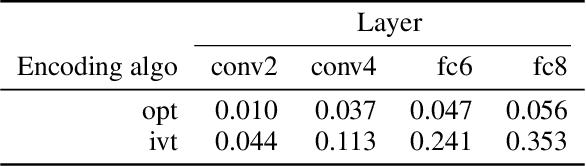
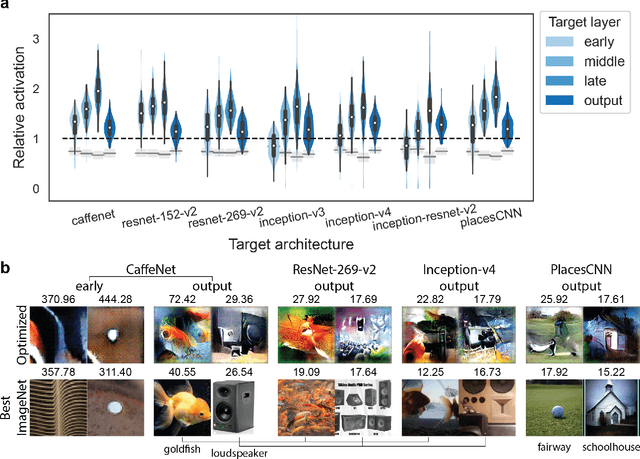

A fundamental question for understanding brain function is what types of stimuli drive neurons to fire. In visual neuroscience, this question has also been posted as characterizing the receptive field of a neuron. The search for effective stimuli has traditionally been based on a combination of insights from previous studies, intuition, and luck. Recently, the same question has emerged in the study of units in convolutional neural networks (ConvNets), and together with this question a family of solutions were developed that are generally referred to as "feature visualization by activation maximization." We sought to bring in tools and techniques developed for studying ConvNets to the study of biological neural networks. However, one key difference that impedes direct translation of tools is that gradients can be obtained from ConvNets using backpropagation, but such gradients are not available from the brain. To circumvent this problem, we developed a method for gradient-free activation maximization by combining a generative neural network with a genetic algorithm. We termed this method XDream (EXtending DeepDream with real-time evolution for activation maximization), and we have shown that this method can reliably create strong stimuli for neurons in the macaque visual cortex (Ponce et al., 2019). In this paper, we describe extensive experiments characterizing the XDream method by using ConvNet units as in silico models of neurons. We show that XDream is applicable across network layers, architectures, and training sets; examine design choices in the algorithm; and provide practical guides for choosing hyperparameters in the algorithm. XDream is an efficient algorithm for uncovering neuronal tuning preferences in black-box networks using a vast and diverse stimulus space.
Biologically-plausible learning algorithms can scale to large datasets
Nov 25, 2018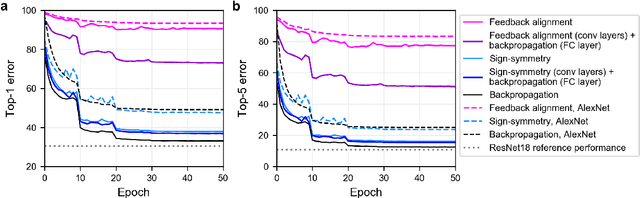
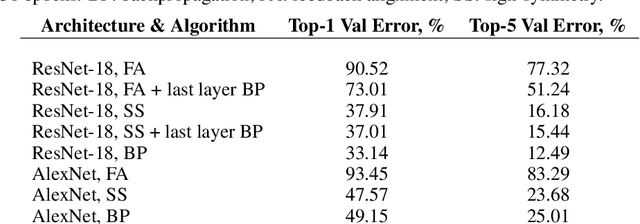
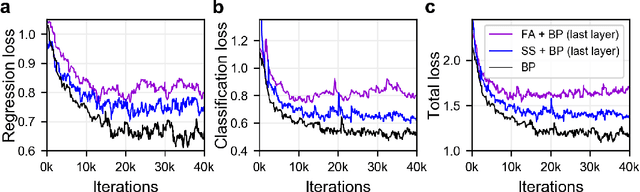
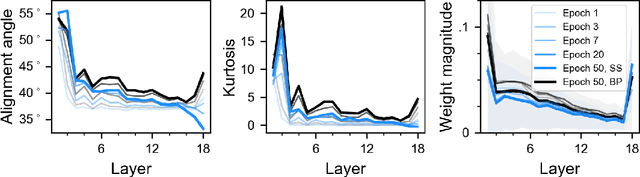
The backpropagation (BP) algorithm is often thought to be biologically implausible in the brain. One of the main reasons is that BP requires symmetric weight matrices in the feedforward and feedback pathways. To address this "weight transport problem" (Grossberg, 1987), two more biologically plausible algorithms, proposed by Liao et al. (2016) and Lillicrap et al. (2016), relax BP's weight symmetry requirements and demonstrate comparable learning capabilities to that of BP on small datasets. However, a recent study by Bartunov et al. (2018) evaluate variants of target-propagation (TP) and feedback alignment (FA) on MINIST, CIFAR, and ImageNet datasets, and find that although many of the proposed algorithms perform well on MNIST and CIFAR, they perform significantly worse than BP on ImageNet. Here, we additionally evaluate the sign-symmetry algorithm (Liao et al., 2016), which differs from both BP and FA in that the feedback and feedforward weights share signs but not magnitudes. We examine the performance of sign-symmetry and feedback alignment on ImageNet and MS COCO datasets using different network architectures (ResNet-18 and AlexNet for ImageNet, RetinaNet for MS COCO). Surprisingly, networks trained with sign-symmetry can attain classification performance approaching that of BP-trained networks. These results complement the study by Bartunov et al. (2018), and establish a new benchmark for future biologically plausible learning algorithms on more difficult datasets and more complex architectures.