 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysical Object Understanding with a Physically Controllable World Model
May 30, 2026A central challenge in visual intelligence is learning the physical structure of scenes from raw videos: how regions form objects and the laws that govern their interactions. Solving these tasks requires world models capable of inferring distributional states of the world from partial observations - capabilities that current architectures do not provide. We introduce a new class of probabilistic world models that support estimation of the probability of any visual variable, such as appearance and dynamics, conditioned on any other variables. Here, we identify that these models can be trained efficiently with autoregressive sequence modeling, yielding world models from which rich object understanding emerges. First, we demonstrate that our model captures the physical laws governing how objects move by generating multiple plausible future states of the world through sequential inference. Then, by analyzing motion correlations across these futures, we extract objects and articulated object subparts. Having discovered these objects, we show that our world model can manipulate them in 3D. Finally, we demonstrate how physical relationships between objects can be computed from the world model, enabling applications such as Visual Jenga.
Unified 3D Scene Understanding Through Physical World Modeling
May 23, 2026Understanding 3D scenes requires flexible combinations of visual reasoning tasks, including depth estimation, novel view synthesis, and object manipulation, all of which are essential for perception and interaction. Existing approaches have typically addressed these tasks in isolation, preventing them from sharing a common representation or transferring knowledge across tasks. A conceptually simpler but practically non-trivial alternative is to unify these diverse tasks into a single model, reducing different tasks from separate training objectives to merely different prompts and allowing for joint training across all datasets. In this work, we present a physical world model for unified 3D understanding and interaction (3WM), formulated as a probabilistic graphical model in which nodes represent multimodal scene elements such as RGB, optical flow, and camera pose. Diverse tasks emerge from different inference pathways through the graph: novel view synthesis from RGB and dense flow prompts, object manipulation from RGB and sparse flow prompts, and depth estimation from RGB and camera conditioning, all zero-shot without task-specific training. 3WM outperforms specialized baselines without the need for finetuning by offering precise controllability, strong geometric consistency, and robustness in real-world scenarios, achieving state-of-the-art performance on NVS and 3D object manipulation. Beyond predefined tasks, the model supports composable inference pathways, such as moving objects aside while navigating a 3D environment, enabling complex geometric reasoning. This demonstrates that a unified model can serve as a practical alternative to fragmented task-specific systems, taking a step towards a general-purpose visual world model.
ViPS: Video-informed Pose Spaces for Auto-Rigged Meshes
Apr 19, 2026Kinematic rigs provide a structured interface for articulating 3D meshes, but they lack an inherent representation of the plausible manifold of joint configurations for a given asset. Without such a pose space, stochastic sampling or manual manipulation of raw rig parameters often leads to semantic or geometric violations, such as anatomical hyperextension and non-physical self-intersections. We propose Video-informed Pose Spaces (ViPS), a feed-forward framework that discovers the latent distribution of valid articulations for auto-rigged meshes by distilling motion priors from a pretrained video diffusion model. Unlike existing methods that rely on scarce artist-authored 4D datasets, ViPS transfers generative video priors into a universal distribution over a given rig parameterization. Differentiable geometric validators applied to the skinned mesh enforce asset-specific validity without requiring manual regularizers. Our model learns a smooth, compact, and controllable pose space that supports diverse sampling, manifold projection for inverse kinematics, and temporally coherent trajectories for keyframing. Furthermore, the distilled 3D pose samples serve as precise semantic proxies for guiding video diffusion, effectively closing the loop between generative 2D priors and structured 3D kinematic control. Our evaluations show that ViPS, trained solely on video priors, matches the performance of state-of-the-art methods trained on synthetic artist-created 4D data in both plausibility and diversity. Most importantly, as a universal model, ViPS demonstrates robust zero-shot generalization to out-of-distribution species and unseen skeletal topologies.
Memory-Efficient Transfer Learning with Fading Side Networks via Masked Dual Path Distillation
Apr 10, 2026Memory-efficient transfer learning (METL) approaches have recently achieved promising performance in adapting pre-trained models to downstream tasks. They avoid applying gradient backpropagation in large backbones, thus significantly reducing the number of trainable parameters and high memory consumption during fine-tuning. However, since they typically employ a lightweight and learnable side network, these methods inevitably introduce additional memory and time overhead during inference, which contradicts the ultimate goal of efficient transfer learning. To address the above issue, we propose a novel approach dubbed Masked Dual Path Distillation (MDPD) to accelerate inference while retaining parameter and memory efficiency in fine-tuning with fading side networks. Specifically, MDPD develops a framework that enhances the performance by mutually distilling the frozen backbones and learnable side networks in fine-tuning, and discard the side network during inference without sacrificing accuracy. Moreover, we design a novel feature-based knowledge distillation method for the encoder structure with multiple layers. Extensive experiments on distinct backbones across vision/language-only and vision-and-language tasks demonstrate that our method not only accelerates inference by at least 25.2\% while keeping parameter and memory consumption comparable, but also remarkably promotes the accuracy compared to SOTA approaches. The source code is available at https://github.com/Zhang-VKk/MDPD.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
3D Scene Understanding Through Local Random Access Sequence Modeling
Apr 04, 20253D scene understanding from single images is a pivotal problem in computer vision with numerous downstream applications in graphics, augmented reality, and robotics. While diffusion-based modeling approaches have shown promise, they often struggle to maintain object and scene consistency, especially in complex real-world scenarios. To address these limitations, we propose an autoregressive generative approach called Local Random Access Sequence (LRAS) modeling, which uses local patch quantization and randomly ordered sequence generation. By utilizing optical flow as an intermediate representation for 3D scene editing, our experiments demonstrate that LRAS achieves state-of-the-art novel view synthesis and 3D object manipulation capabilities. Furthermore, we show that our framework naturally extends to self-supervised depth estimation through a simple modification of the sequence design. By achieving strong performance on multiple 3D scene understanding tasks, LRAS provides a unified and effective framework for building the next generation of 3D vision models.
Purest Quantum State Identification
Feb 20, 2025
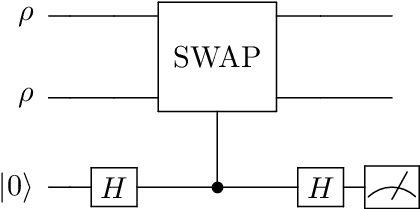
Precise identification of quantum states under noise constraints is essential for quantum information processing. In this study, we generalize the classical best arm identification problem to quantum domains, designing methods for identifying the purest one within $K$ unknown $n$-qubit quantum states using $N$ samples. %, with direct applications in quantum computation and quantum communication. We propose two distinct algorithms: (1) an algorithm employing incoherent measurements, achieving error $\exp\left(- \Omega\left(\frac{N H_1}{\log(K) 2^n }\right) \right)$, and (2) an algorithm utilizing coherent measurements, achieving error $\exp\left(- \Omega\left(\frac{N H_2}{\log(K) }\right) \right)$, highlighting the power of quantum memory. Furthermore, we establish a lower bound by proving that all strategies with fixed two-outcome incoherent POVM must suffer error probability exceeding $ \exp\left( - O\left(\frac{NH_1}{2^n}\right)\right)$. This framework provides concrete design principles for overcoming sampling bottlenecks in quantum technologies.
Counterfactual World Modeling for Physical Dynamics Understanding
Dec 26, 2023



The ability to understand physical dynamics is essential to learning agents acting in the world. This paper presents Counterfactual World Modeling (CWM), a candidate pure vision foundational model for physical dynamics understanding. CWM consists of three basic concepts. First, we propose a simple and powerful temporally-factored masking policy for masked prediction of video data, which encourages the model to learn disentangled representations of scene appearance and dynamics. Second, as a result of the factoring, CWM is capable of generating counterfactual next-frame predictions by manipulating a few patch embeddings to exert meaningful control over scene dynamics. Third, the counterfactual modeling capability enables the design of counterfactual queries to extract vision structures similar to keypoints, optical flows, and segmentations, which are useful for dynamics understanding. We show that zero-shot readouts of these structures extracted by the counterfactual queries attain competitive performance to prior methods on real-world datasets. Finally, we demonstrate that CWM achieves state-of-the-art performance on the challenging Physion benchmark for evaluating physical dynamics understanding.
Unifying (Machine) Vision via Counterfactual World Modeling
Jun 02, 2023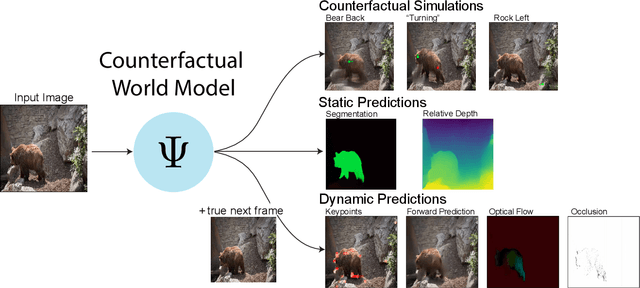


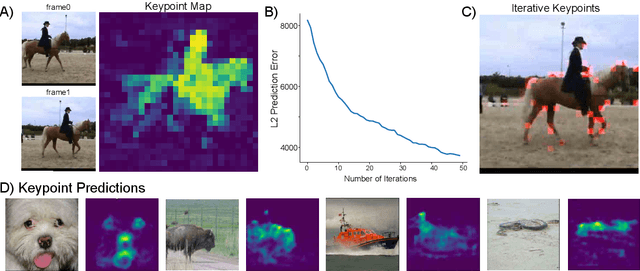
Leading approaches in machine vision employ different architectures for different tasks, trained on costly task-specific labeled datasets. This complexity has held back progress in areas, such as robotics, where robust task-general perception remains a bottleneck. In contrast, "foundation models" of natural language have shown how large pre-trained neural networks can provide zero-shot solutions to a broad spectrum of apparently distinct tasks. Here we introduce Counterfactual World Modeling (CWM), a framework for constructing a visual foundation model: a unified, unsupervised network that can be prompted to perform a wide variety of visual computations. CWM has two key components, which resolve the core issues that have hindered application of the foundation model concept to vision. The first is structured masking, a generalization of masked prediction methods that encourages a prediction model to capture the low-dimensional structure in visual data. The model thereby factors the key physical components of a scene and exposes an interface to them via small sets of visual tokens. This in turn enables CWM's second main idea -- counterfactual prompting -- the observation that many apparently distinct visual representations can be computed, in a zero-shot manner, by comparing the prediction model's output on real inputs versus slightly modified ("counterfactual") inputs. We show that CWM generates high-quality readouts on real-world images and videos for a diversity of tasks, including estimation of keypoints, optical flow, occlusions, object segments, and relative depth. Taken together, our results show that CWM is a promising path to unifying the manifold strands of machine vision in a conceptually simple foundation.
Implicit Neural Spatial Representations for Time-dependent PDEs
Sep 30, 2022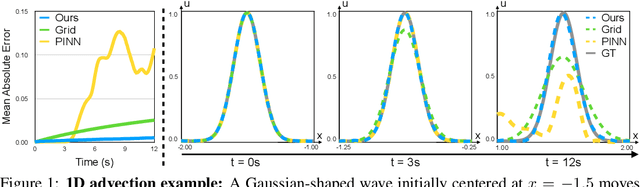

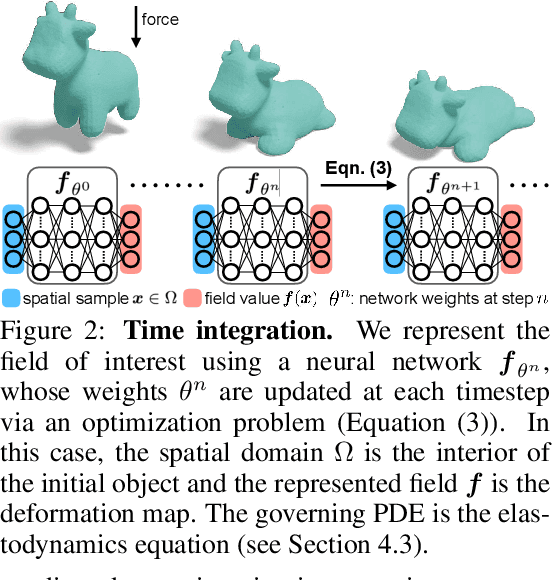

Numerically solving partial differential equations (PDEs) often entails spatial and temporal discretizations. Traditional methods (e.g., finite difference, finite element, smoothed-particle hydrodynamics) frequently adopt explicit spatial discretizations, such as grids, meshes, and point clouds, where each degree-of-freedom corresponds to a location in space. While these explicit spatial correspondences are intuitive to model and understand, these representations are not necessarily optimal for accuracy, memory-usage, or adaptivity. In this work, we explore implicit neural representation as an alternative spatial discretization, where spatial information is implicitly stored in the neural network weights. With implicit neural spatial representation, PDE-constrained time-stepping translates into updating neural network weights, which naturally integrates with commonly adopted optimization time integrators. We validate our approach on a variety of classic PDEs with examples involving large elastic deformations, turbulent fluids, and multiscale phenomena. While slower to compute than traditional representations, our approach exhibits higher accuracy, lower memory consumption, and dynamically adaptive allocation of degrees of freedom without complex remeshing.