 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Scene Understanding Through Local Random Access Sequence Modeling
Apr 04, 20253D scene understanding from single images is a pivotal problem in computer vision with numerous downstream applications in graphics, augmented reality, and robotics. While diffusion-based modeling approaches have shown promise, they often struggle to maintain object and scene consistency, especially in complex real-world scenarios. To address these limitations, we propose an autoregressive generative approach called Local Random Access Sequence (LRAS) modeling, which uses local patch quantization and randomly ordered sequence generation. By utilizing optical flow as an intermediate representation for 3D scene editing, our experiments demonstrate that LRAS achieves state-of-the-art novel view synthesis and 3D object manipulation capabilities. Furthermore, we show that our framework naturally extends to self-supervised depth estimation through a simple modification of the sequence design. By achieving strong performance on multiple 3D scene understanding tasks, LRAS provides a unified and effective framework for building the next generation of 3D vision models.
Counterfactual World Modeling for Physical Dynamics Understanding
Dec 26, 2023



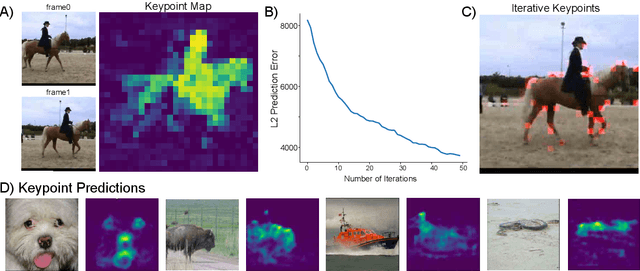
The ability to understand physical dynamics is essential to learning agents acting in the world. This paper presents Counterfactual World Modeling (CWM), a candidate pure vision foundational model for physical dynamics understanding. CWM consists of three basic concepts. First, we propose a simple and powerful temporally-factored masking policy for masked prediction of video data, which encourages the model to learn disentangled representations of scene appearance and dynamics. Second, as a result of the factoring, CWM is capable of generating counterfactual next-frame predictions by manipulating a few patch embeddings to exert meaningful control over scene dynamics. Third, the counterfactual modeling capability enables the design of counterfactual queries to extract vision structures similar to keypoints, optical flows, and segmentations, which are useful for dynamics understanding. We show that zero-shot readouts of these structures extracted by the counterfactual queries attain competitive performance to prior methods on real-world datasets. Finally, we demonstrate that CWM achieves state-of-the-art performance on the challenging Physion benchmark for evaluating physical dynamics understanding.
Unifying (Machine) Vision via Counterfactual World Modeling
Jun 02, 2023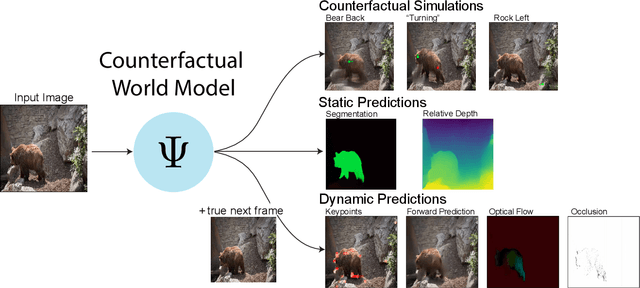


Leading approaches in machine vision employ different architectures for different tasks, trained on costly task-specific labeled datasets. This complexity has held back progress in areas, such as robotics, where robust task-general perception remains a bottleneck. In contrast, "foundation models" of natural language have shown how large pre-trained neural networks can provide zero-shot solutions to a broad spectrum of apparently distinct tasks. Here we introduce Counterfactual World Modeling (CWM), a framework for constructing a visual foundation model: a unified, unsupervised network that can be prompted to perform a wide variety of visual computations. CWM has two key components, which resolve the core issues that have hindered application of the foundation model concept to vision. The first is structured masking, a generalization of masked prediction methods that encourages a prediction model to capture the low-dimensional structure in visual data. The model thereby factors the key physical components of a scene and exposes an interface to them via small sets of visual tokens. This in turn enables CWM's second main idea -- counterfactual prompting -- the observation that many apparently distinct visual representations can be computed, in a zero-shot manner, by comparing the prediction model's output on real inputs versus slightly modified ("counterfactual") inputs. We show that CWM generates high-quality readouts on real-world images and videos for a diversity of tasks, including estimation of keypoints, optical flow, occlusions, object segments, and relative depth. Taken together, our results show that CWM is a promising path to unifying the manifold strands of machine vision in a conceptually simple foundation.