 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysical Object Understanding with a Physically Controllable World Model
May 30, 2026A central challenge in visual intelligence is learning the physical structure of scenes from raw videos: how regions form objects and the laws that govern their interactions. Solving these tasks requires world models capable of inferring distributional states of the world from partial observations - capabilities that current architectures do not provide. We introduce a new class of probabilistic world models that support estimation of the probability of any visual variable, such as appearance and dynamics, conditioned on any other variables. Here, we identify that these models can be trained efficiently with autoregressive sequence modeling, yielding world models from which rich object understanding emerges. First, we demonstrate that our model captures the physical laws governing how objects move by generating multiple plausible future states of the world through sequential inference. Then, by analyzing motion correlations across these futures, we extract objects and articulated object subparts. Having discovered these objects, we show that our world model can manipulate them in 3D. Finally, we demonstrate how physical relationships between objects can be computed from the world model, enabling applications such as Visual Jenga.
Zero-shot World Models Are Developmentally Efficient Learners
Apr 11, 2026Young children demonstrate early abilities to understand their physical world, estimating depth, motion, object coherence, interactions, and many other aspects of physical scene understanding. Children are both data-efficient and flexible cognitive systems, creating competence despite extremely limited training data, while generalizing to myriad untrained tasks -- a major challenge even for today's best AI systems. Here we introduce a novel computational hypothesis for these abilities, the Zero-shot Visual World Model (ZWM). ZWM is based on three principles: a sparse temporally-factored predictor that decouples appearance from dynamics; zero-shot estimation through approximate causal inference; and composition of inferences to build more complex abilities. We show that ZWM can be learned from the first-person experience of a single child, rapidly generating competence across multiple physical understanding benchmarks. It also broadly recapitulates behavioral signatures of child development and builds brain-like internal representations. Our work presents a blueprint for efficient and flexible learning from human-scale data, advancing both a computational account for children's early physical understanding and a path toward data-efficient AI systems.
Self-Supervised Learning of Motion Concepts by Optimizing Counterfactuals
Mar 25, 2025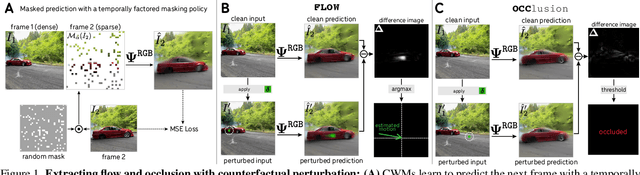
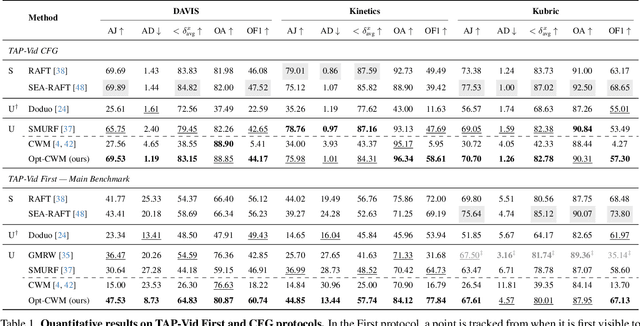
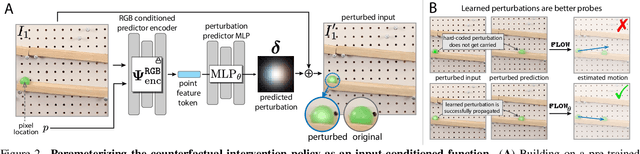
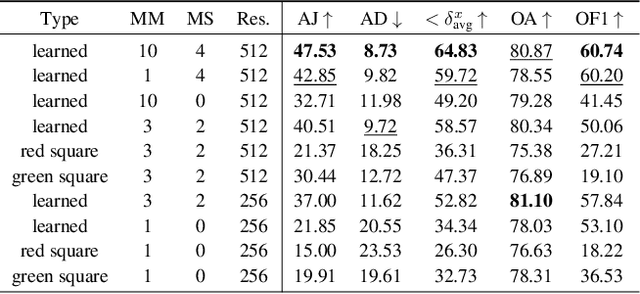
Estimating motion in videos is an essential computer vision problem with many downstream applications, including controllable video generation and robotics. Current solutions are primarily trained using synthetic data or require tuning of situation-specific heuristics, which inherently limits these models' capabilities in real-world contexts. Despite recent developments in large-scale self-supervised learning from videos, leveraging such representations for motion estimation remains relatively underexplored. In this work, we develop Opt-CWM, a self-supervised technique for flow and occlusion estimation from a pre-trained next-frame prediction model. Opt-CWM works by learning to optimize counterfactual probes that extract motion information from a base video model, avoiding the need for fixed heuristics while training on unrestricted video inputs. We achieve state-of-the-art performance for motion estimation on real-world videos while requiring no labeled data.
Counterfactual World Modeling for Physical Dynamics Understanding
Dec 26, 2023



The ability to understand physical dynamics is essential to learning agents acting in the world. This paper presents Counterfactual World Modeling (CWM), a candidate pure vision foundational model for physical dynamics understanding. CWM consists of three basic concepts. First, we propose a simple and powerful temporally-factored masking policy for masked prediction of video data, which encourages the model to learn disentangled representations of scene appearance and dynamics. Second, as a result of the factoring, CWM is capable of generating counterfactual next-frame predictions by manipulating a few patch embeddings to exert meaningful control over scene dynamics. Third, the counterfactual modeling capability enables the design of counterfactual queries to extract vision structures similar to keypoints, optical flows, and segmentations, which are useful for dynamics understanding. We show that zero-shot readouts of these structures extracted by the counterfactual queries attain competitive performance to prior methods on real-world datasets. Finally, we demonstrate that CWM achieves state-of-the-art performance on the challenging Physion benchmark for evaluating physical dynamics understanding.
Unifying (Machine) Vision via Counterfactual World Modeling
Jun 02, 2023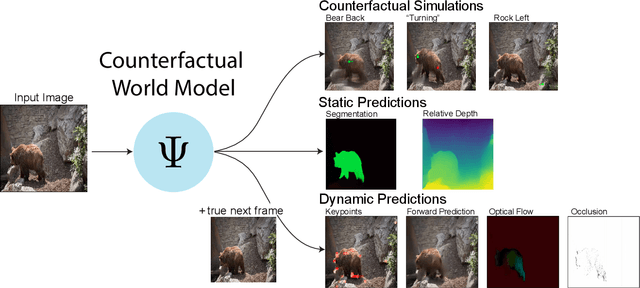


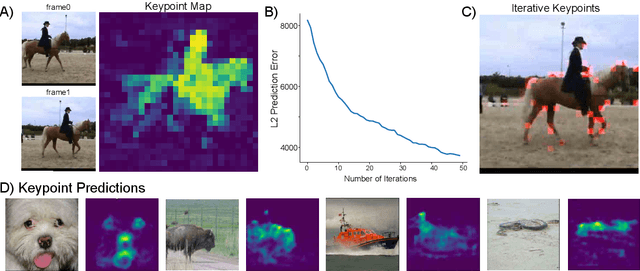
Leading approaches in machine vision employ different architectures for different tasks, trained on costly task-specific labeled datasets. This complexity has held back progress in areas, such as robotics, where robust task-general perception remains a bottleneck. In contrast, "foundation models" of natural language have shown how large pre-trained neural networks can provide zero-shot solutions to a broad spectrum of apparently distinct tasks. Here we introduce Counterfactual World Modeling (CWM), a framework for constructing a visual foundation model: a unified, unsupervised network that can be prompted to perform a wide variety of visual computations. CWM has two key components, which resolve the core issues that have hindered application of the foundation model concept to vision. The first is structured masking, a generalization of masked prediction methods that encourages a prediction model to capture the low-dimensional structure in visual data. The model thereby factors the key physical components of a scene and exposes an interface to them via small sets of visual tokens. This in turn enables CWM's second main idea -- counterfactual prompting -- the observation that many apparently distinct visual representations can be computed, in a zero-shot manner, by comparing the prediction model's output on real inputs versus slightly modified ("counterfactual") inputs. We show that CWM generates high-quality readouts on real-world images and videos for a diversity of tasks, including estimation of keypoints, optical flow, occlusions, object segments, and relative depth. Taken together, our results show that CWM is a promising path to unifying the manifold strands of machine vision in a conceptually simple foundation.
Unsupervised Segmentation in Real-World Images via Spelke Object Inference
May 17, 2022
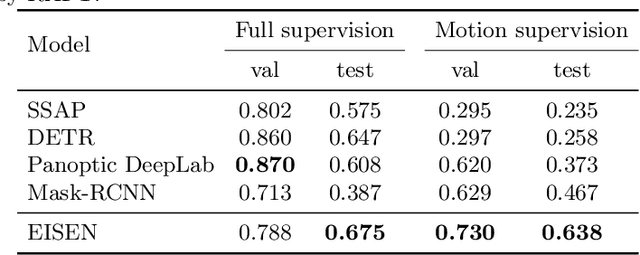
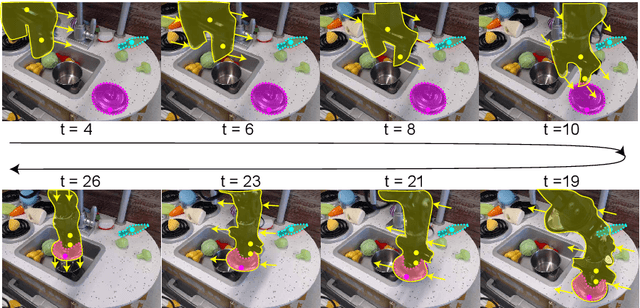

Self-supervised category-agnostic segmentation of real-world images into objects is a challenging open problem in computer vision. Here, we show how to learn static grouping priors from motion self-supervision, building on the cognitive science notion of Spelke Objects: groupings of stuff that move together. We introduce Excitatory-Inhibitory Segment Extraction Network (EISEN), which learns from optical flow estimates to extract pairwise affinity graphs for static scenes. EISEN then produces segments from affinities using a novel graph propagation and competition mechanism. Correlations between independent sources of motion (e.g. robot arms) and objects they move are resolved into separate segments through a bootstrapping training process. We show that EISEN achieves a substantial improvement in the state of the art for self-supervised segmentation on challenging synthetic and real-world robotic image datasets. We also present an ablation analysis illustrating the importance of each element of the EISEN architecture.
Deep Implicit Surface Point Prediction Networks
Jun 15, 2021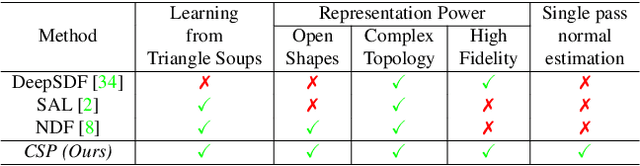
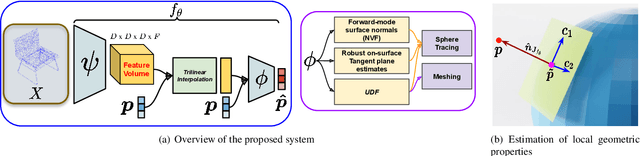
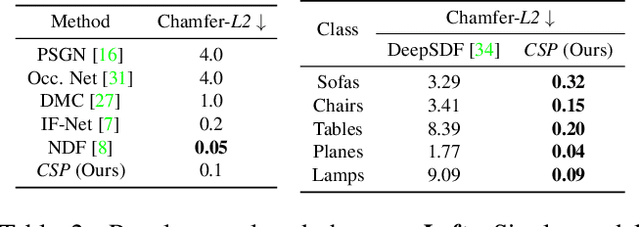
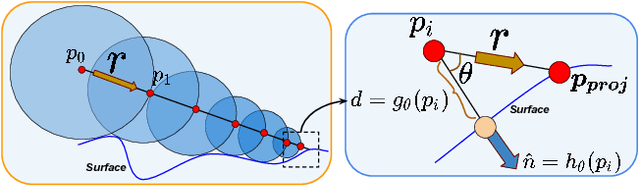
Deep neural representations of 3D shapes as implicit functions have been shown to produce high fidelity models surpassing the resolution-memory trade-off faced by the explicit representations using meshes and point clouds. However, most such approaches focus on representing closed shapes. Unsigned distance function (UDF) based approaches have been proposed recently as a promising alternative to represent both open and closed shapes. However, since the gradients of UDFs vanish on the surface, it is challenging to estimate local (differential) geometric properties like the normals and tangent planes which are needed for many downstream applications in vision and graphics. There are additional challenges in computing these properties efficiently with a low-memory footprint. This paper presents a novel approach that models such surfaces using a new class of implicit representations called the closest surface-point (CSP) representation. We show that CSP allows us to represent complex surfaces of any topology (open or closed) with high fidelity. It also allows for accurate and efficient computation of local geometric properties. We further demonstrate that it leads to efficient implementation of downstream algorithms like sphere-tracing for rendering the 3D surface as well as to create explicit mesh-based representations. Extensive experimental evaluation on the ShapeNet dataset validate the above contributions with results surpassing the state-of-the-art.
DUDE: Deep Unsigned Distance Embeddings for Hi-Fidelity Representation of Complex 3D Surfaces
Nov 04, 2020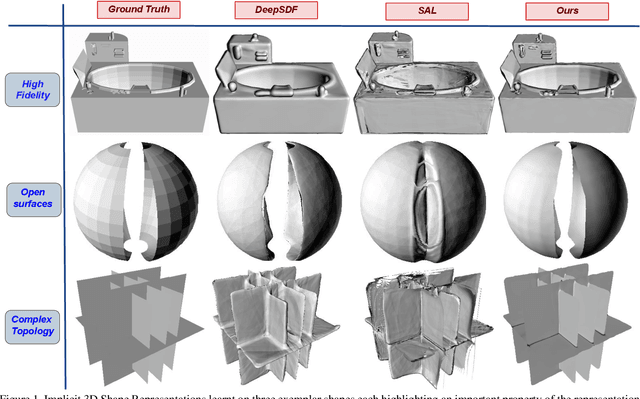
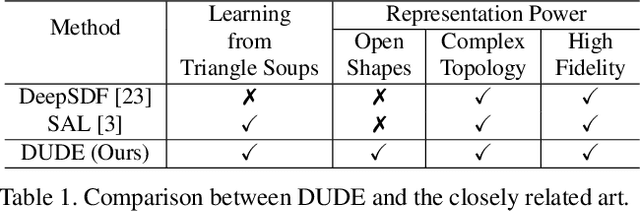
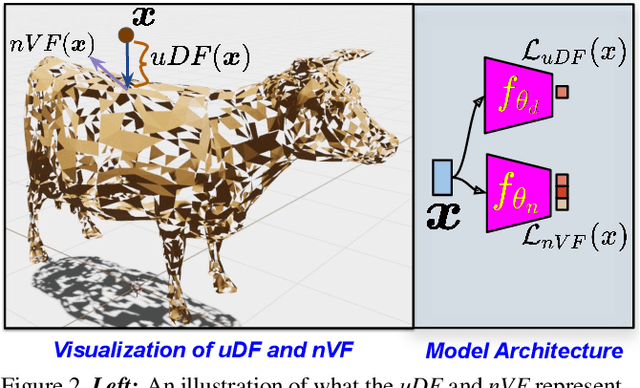
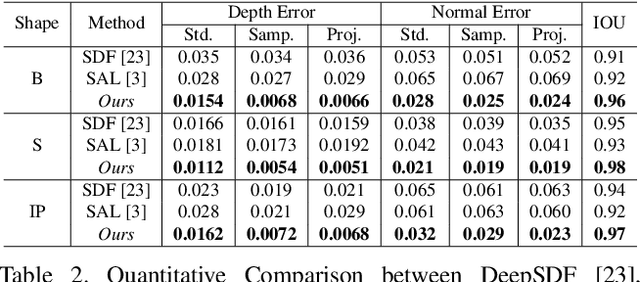
High fidelity representation of shapes with arbitrary topology is an important problem for a variety of vision and graphics applications. Owing to their limited resolution, classical discrete shape representations using point clouds, voxels and meshes produce low quality results when used in these applications. Several implicit 3D shape representation approaches using deep neural networks have been proposed leading to significant improvements in both quality of representations as well as the impact on downstream applications. However, these methods can only be used to represent topologically closed shapes which greatly limits the class of shapes that they can represent. As a consequence, they also often require clean, watertight meshes for training. In this work, we propose DUDE - a Deep Unsigned Distance Embedding method which alleviates both of these shortcomings. DUDE is a disentangled shape representation that utilizes an unsigned distance field (uDF) to represent proximity to a surface, and a normal vector field (nVF) to represent surface orientation. We show that a combination of these two (uDF+nVF) can be used to learn high fidelity representations for arbitrary open/closed shapes. As opposed to prior work such as DeepSDF, our shape representations can be directly learnt from noisy triangle soups, and do not need watertight meshes. Additionally, we propose novel algorithms for extracting and rendering iso-surfaces from the learnt representations. We validate DUDE on benchmark 3D datasets and demonstrate that it produces significant improvements over the state of the art.