 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Multiview Object Consistency in Humans and Image Models
Sep 10, 2024



We introduce a benchmark to directly evaluate the alignment between human observers and vision models on a 3D shape inference task. We leverage an experimental design from the cognitive sciences which requires zero-shot visual inferences about object shape: given a set of images, participants identify which contain the same/different objects, despite considerable viewpoint variation. We draw from a diverse range of images that include common objects (e.g., chairs) as well as abstract shapes (i.e., procedurally generated `nonsense' objects). After constructing over 2000 unique image sets, we administer these tasks to human participants, collecting 35K trials of behavioral data from over 500 participants. This includes explicit choice behaviors as well as intermediate measures, such as reaction time and gaze data. We then evaluate the performance of common vision models (e.g., DINOv2, MAE, CLIP). We find that humans outperform all models by a wide margin. Using a multi-scale evaluation approach, we identify underlying similarities and differences between models and humans: while human-model performance is correlated, humans allocate more time/processing on challenging trials. All images, data, and code can be accessed via our project page.
Approaching human 3D shape perception with neurally mappable models
Sep 07, 2023Humans effortlessly infer the 3D shape of objects. What computations underlie this ability? Although various computational models have been proposed, none of them capture the human ability to match object shape across viewpoints. Here, we ask whether and how this gap might be closed. We begin with a relatively novel class of computational models, 3D neural fields, which encapsulate the basic principles of classic analysis-by-synthesis in a deep neural network (DNN). First, we find that a 3D Light Field Network (3D-LFN) supports 3D matching judgments well aligned to humans for within-category comparisons, adversarially-defined comparisons that accentuate the 3D failure cases of standard DNN models, and adversarially-defined comparisons for algorithmically generated shapes with no category structure. We then investigate the source of the 3D-LFN's ability to achieve human-aligned performance through a series of computational experiments. Exposure to multiple viewpoints of objects during training and a multi-view learning objective are the primary factors behind model-human alignment; even conventional DNN architectures come much closer to human behavior when trained with multi-view objectives. Finally, we find that while the models trained with multi-view learning objectives are able to partially generalize to new object categories, they fall short of human alignment. This work provides a foundation for understanding human shape inferences within neurally mappable computational architectures.
Unsupervised Segmentation in Real-World Images via Spelke Object Inference
May 17, 2022
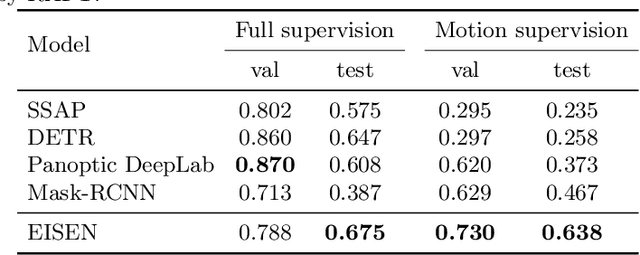
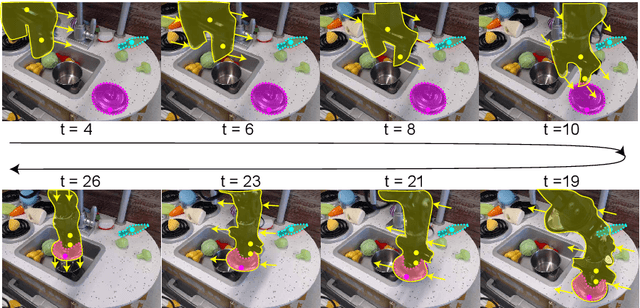

Self-supervised category-agnostic segmentation of real-world images into objects is a challenging open problem in computer vision. Here, we show how to learn static grouping priors from motion self-supervision, building on the cognitive science notion of Spelke Objects: groupings of stuff that move together. We introduce Excitatory-Inhibitory Segment Extraction Network (EISEN), which learns from optical flow estimates to extract pairwise affinity graphs for static scenes. EISEN then produces segments from affinities using a novel graph propagation and competition mechanism. Correlations between independent sources of motion (e.g. robot arms) and objects they move are resolved into separate segments through a bootstrapping training process. We show that EISEN achieves a substantial improvement in the state of the art for self-supervised segmentation on challenging synthetic and real-world robotic image datasets. We also present an ablation analysis illustrating the importance of each element of the EISEN architecture.
Identifying concept libraries from language about object structure
May 11, 2022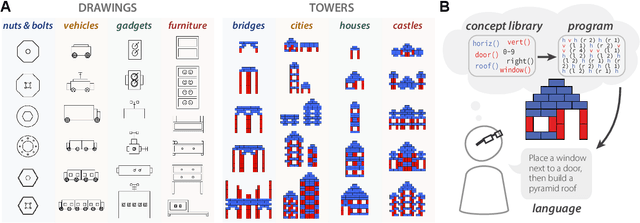
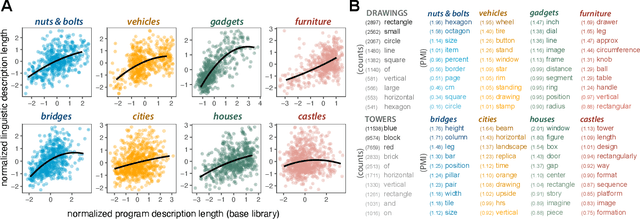
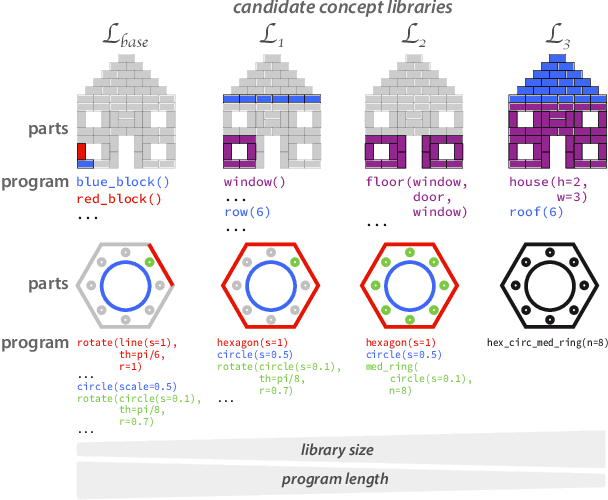
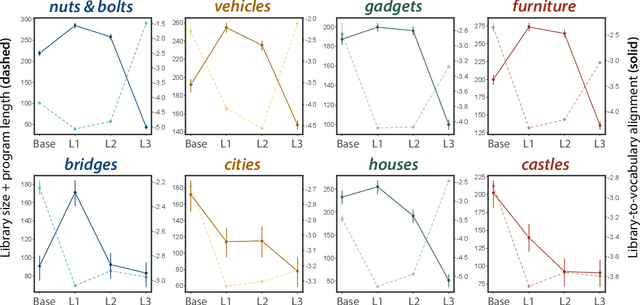
Our understanding of the visual world goes beyond naming objects, encompassing our ability to parse objects into meaningful parts, attributes, and relations. In this work, we leverage natural language descriptions for a diverse set of 2K procedurally generated objects to identify the parts people use and the principles leading these parts to be favored over others. We formalize our problem as search over a space of program libraries that contain different part concepts, using tools from machine translation to evaluate how well programs expressed in each library align to human language. By combining naturalistic language at scale with structured program representations, we discover a fundamental information-theoretic tradeoff governing the part concepts people name: people favor a lexicon that allows concise descriptions of each object, while also minimizing the size of the lexicon itself.