 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreciseControl: Enhancing Text-To-Image Diffusion Models with Fine-Grained Attribute Control
Jul 24, 2024Recently, we have seen a surge of personalization methods for text-to-image (T2I) diffusion models to learn a concept using a few images. Existing approaches, when used for face personalization, suffer to achieve convincing inversion with identity preservation and rely on semantic text-based editing of the generated face. However, a more fine-grained control is desired for facial attribute editing, which is challenging to achieve solely with text prompts. In contrast, StyleGAN models learn a rich face prior and enable smooth control towards fine-grained attribute editing by latent manipulation. This work uses the disentangled $\mathcal{W+}$ space of StyleGANs to condition the T2I model. This approach allows us to precisely manipulate facial attributes, such as smoothly introducing a smile, while preserving the existing coarse text-based control inherent in T2I models. To enable conditioning of the T2I model on the $\mathcal{W+}$ space, we train a latent mapper to translate latent codes from $\mathcal{W+}$ to the token embedding space of the T2I model. The proposed approach excels in the precise inversion of face images with attribute preservation and facilitates continuous control for fine-grained attribute editing. Furthermore, our approach can be readily extended to generate compositions involving multiple individuals. We perform extensive experiments to validate our method for face personalization and fine-grained attribute editing.
Exploring Attribute Variations in Style-based GANs using Diffusion Models
Nov 27, 2023Existing attribute editing methods treat semantic attributes as binary, resulting in a single edit per attribute. However, attributes such as eyeglasses, smiles, or hairstyles exhibit a vast range of diversity. In this work, we formulate the task of \textit{diverse attribute editing} by modeling the multidimensional nature of attribute edits. This enables users to generate multiple plausible edits per attribute. We capitalize on disentangled latent spaces of pretrained GANs and train a Denoising Diffusion Probabilistic Model (DDPM) to learn the latent distribution for diverse edits. Specifically, we train DDPM over a dataset of edit latent directions obtained by embedding image pairs with a single attribute change. This leads to latent subspaces that enable diverse attribute editing. Applying diffusion in the highly compressed latent space allows us to model rich distributions of edits within limited computational resources. Through extensive qualitative and quantitative experiments conducted across a range of datasets, we demonstrate the effectiveness of our approach for diverse attribute editing. We also showcase the results of our method applied for 3D editing of various face attributes.
NoisyTwins: Class-Consistent and Diverse Image Generation through StyleGANs
Apr 12, 2023StyleGANs are at the forefront of controllable image generation as they produce a latent space that is semantically disentangled, making it suitable for image editing and manipulation. However, the performance of StyleGANs severely degrades when trained via class-conditioning on large-scale long-tailed datasets. We find that one reason for degradation is the collapse of latents for each class in the $\mathcal{W}$ latent space. With NoisyTwins, we first introduce an effective and inexpensive augmentation strategy for class embeddings, which then decorrelates the latents based on self-supervision in the $\mathcal{W}$ space. This decorrelation mitigates collapse, ensuring that our method preserves intra-class diversity with class-consistency in image generation. We show the effectiveness of our approach on large-scale real-world long-tailed datasets of ImageNet-LT and iNaturalist 2019, where our method outperforms other methods by $\sim 19\%$ on FID, establishing a new state-of-the-art.
Improving GANs for Long-Tailed Data through Group Spectral Regularization
Aug 21, 2022

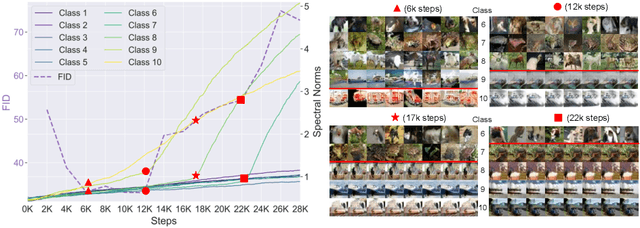

Deep long-tailed learning aims to train useful deep networks on practical, real-world imbalanced distributions, wherein most labels of the tail classes are associated with a few samples. There has been a large body of work to train discriminative models for visual recognition on long-tailed distribution. In contrast, we aim to train conditional Generative Adversarial Networks, a class of image generation models on long-tailed distributions. We find that similar to recognition, state-of-the-art methods for image generation also suffer from performance degradation on tail classes. The performance degradation is mainly due to class-specific mode collapse for tail classes, which we observe to be correlated with the spectral explosion of the conditioning parameter matrix. We propose a novel group Spectral Regularizer (gSR) that prevents the spectral explosion alleviating mode collapse, which results in diverse and plausible image generation even for tail classes. We find that gSR effectively combines with existing augmentation and regularization techniques, leading to state-of-the-art image generation performance on long-tailed data. Extensive experiments demonstrate the efficacy of our regularizer on long-tailed datasets with different degrees of imbalance.
Hierarchical Semantic Regularization of Latent Spaces in StyleGANs
Aug 07, 2022
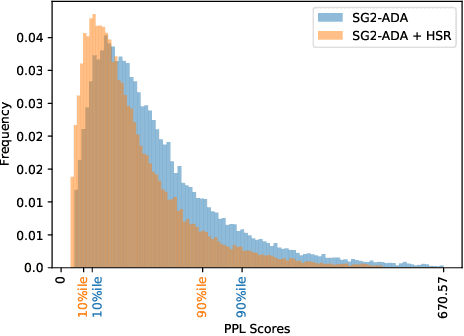
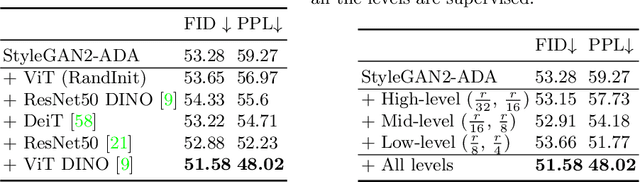
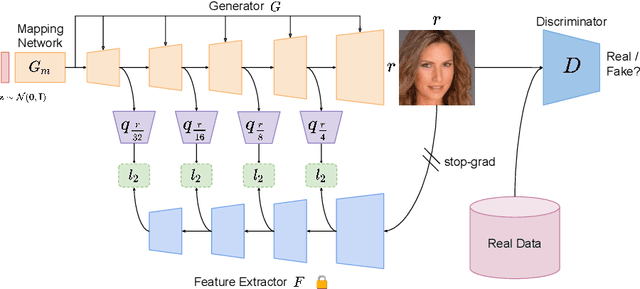
Progress in GANs has enabled the generation of high-resolution photorealistic images of astonishing quality. StyleGANs allow for compelling attribute modification on such images via mathematical operations on the latent style vectors in the W/W+ space that effectively modulate the rich hierarchical representations of the generator. Such operations have recently been generalized beyond mere attribute swapping in the original StyleGAN paper to include interpolations. In spite of many significant improvements in StyleGANs, they are still seen to generate unnatural images. The quality of the generated images is predicated on two assumptions; (a) The richness of the hierarchical representations learnt by the generator, and, (b) The linearity and smoothness of the style spaces. In this work, we propose a Hierarchical Semantic Regularizer (HSR) which aligns the hierarchical representations learnt by the generator to corresponding powerful features learnt by pretrained networks on large amounts of data. HSR is shown to not only improve generator representations but also the linearity and smoothness of the latent style spaces, leading to the generation of more natural-looking style-edited images. To demonstrate improved linearity, we propose a novel metric - Attribute Linearity Score (ALS). A significant reduction in the generation of unnatural images is corroborated by improvement in the Perceptual Path Length (PPL) metric by 16.19% averaged across different standard datasets while simultaneously improving the linearity of attribute-change in the attribute editing tasks.
Everything is There in Latent Space: Attribute Editing and Attribute Style Manipulation by StyleGAN Latent Space Exploration
Jul 20, 2022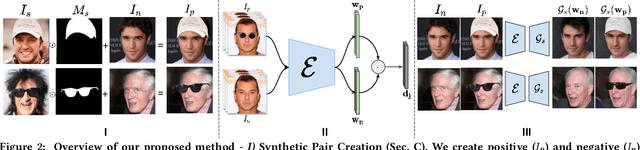
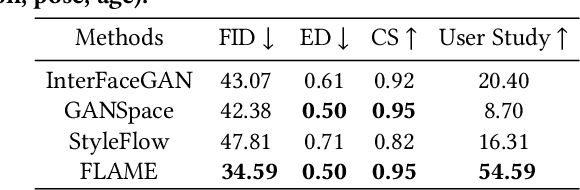

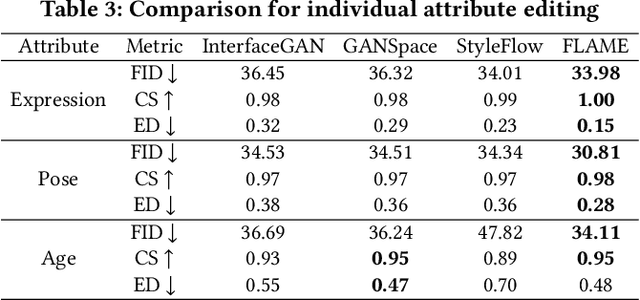
Unconstrained Image generation with high realism is now possible using recent Generative Adversarial Networks (GANs). However, it is quite challenging to generate images with a given set of attributes. Recent methods use style-based GAN models to perform image editing by leveraging the semantic hierarchy present in the layers of the generator. We present Few-shot Latent-based Attribute Manipulation and Editing (FLAME), a simple yet effective framework to perform highly controlled image editing by latent space manipulation. Specifically, we estimate linear directions in the latent space (of a pre-trained StyleGAN) that controls semantic attributes in the generated image. In contrast to previous methods that either rely on large-scale attribute labeled datasets or attribute classifiers, FLAME uses minimal supervision of a few curated image pairs to estimate disentangled edit directions. FLAME can perform both individual and sequential edits with high precision on a diverse set of images while preserving identity. Further, we propose a novel task of Attribute Style Manipulation to generate diverse styles for attributes such as eyeglass and hair. We first encode a set of synthetic images of the same identity but having different attribute styles in the latent space to estimate an attribute style manifold. Sampling a new latent from this manifold will result in a new attribute style in the generated image. We propose a novel sampling method to sample latent from the manifold, enabling us to generate a diverse set of attribute styles beyond the styles present in the training set. FLAME can generate diverse attribute styles in a disentangled manner. We illustrate the superior performance of FLAME against previous image editing methods by extensive qualitative and quantitative comparisons. FLAME also generalizes well on multiple datasets such as cars and churches.
LEAD: Self-Supervised Landmark Estimation by Aligning Distributions of Feature Similarity
Apr 06, 2022
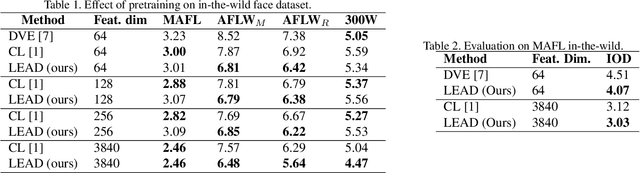


In this work, we introduce LEAD, an approach to discover landmarks from an unannotated collection of category-specific images. Existing works in self-supervised landmark detection are based on learning dense (pixel-level) feature representations from an image, which are further used to learn landmarks in a semi-supervised manner. While there have been advances in self-supervised learning of image features for instance-level tasks like classification, these methods do not ensure dense equivariant representations. The property of equivariance is of interest for dense prediction tasks like landmark estimation. In this work, we introduce an approach to enhance the learning of dense equivariant representations in a self-supervised fashion. We follow a two-stage training approach: first, we train a network using the BYOL objective which operates at an instance level. The correspondences obtained through this network are further used to train a dense and compact representation of the image using a lightweight network. We show that having such a prior in the feature extractor helps in landmark detection, even under drastically limited number of annotations while also improving generalization across scale variations.
Deep Implicit Surface Point Prediction Networks
Jun 15, 2021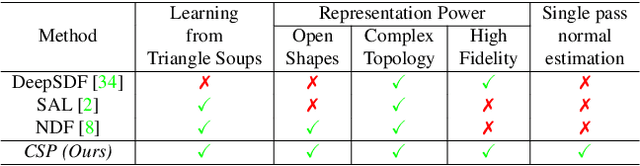
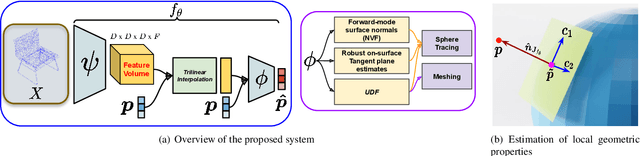
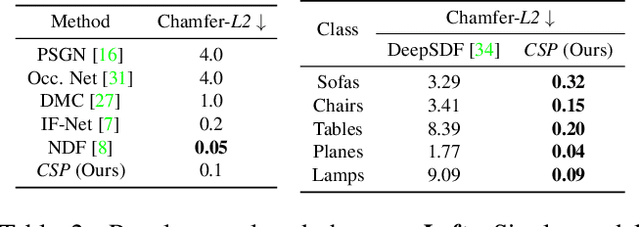
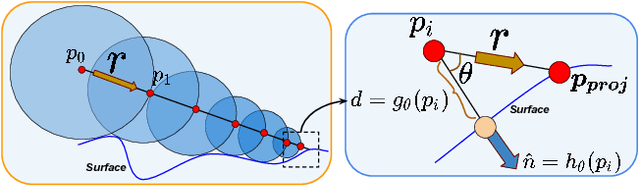
Deep neural representations of 3D shapes as implicit functions have been shown to produce high fidelity models surpassing the resolution-memory trade-off faced by the explicit representations using meshes and point clouds. However, most such approaches focus on representing closed shapes. Unsigned distance function (UDF) based approaches have been proposed recently as a promising alternative to represent both open and closed shapes. However, since the gradients of UDFs vanish on the surface, it is challenging to estimate local (differential) geometric properties like the normals and tangent planes which are needed for many downstream applications in vision and graphics. There are additional challenges in computing these properties efficiently with a low-memory footprint. This paper presents a novel approach that models such surfaces using a new class of implicit representations called the closest surface-point (CSP) representation. We show that CSP allows us to represent complex surfaces of any topology (open or closed) with high fidelity. It also allows for accurate and efficient computation of local geometric properties. We further demonstrate that it leads to efficient implementation of downstream algorithms like sphere-tracing for rendering the 3D surface as well as to create explicit mesh-based representations. Extensive experimental evaluation on the ShapeNet dataset validate the above contributions with results surpassing the state-of-the-art.
Fashionable Modelling with Flux
Nov 01, 2018
Machine learning as a discipline has seen an incredible surge of interest in recent years due in large part to a perfect storm of new theory, superior tooling, renewed interest in its capabilities. We present in this paper a framework named Flux that shows how further refinement of the core ideas of machine learning, built upon the foundation of the Julia programming language, can yield an environment that is simple, easily modifiable, and performant. We detail the fundamental principles of Flux as a framework for differentiable programming, give examples of models that are implemented within Flux to display many of the language and framework-level features that contribute to its ease of use and high productivity, display internal compiler techniques used to enable the acceleration and performance that lies at the heart of Flux, and finally give an overview of the larger ecosystem that Flux fits inside of.