 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNarrative-Driven Paper-to-Slide Generation via ArcDeck
Apr 13, 2026We introduce ArcDeck, a multi-agent framework that formulates paper-to-slide generation as a structured narrative reconstruction task. Unlike existing methods that directly summarize raw text into slides, ArcDeck explicitly models the source paper's logical flow. It first parses the input to construct a discourse tree and establish a global commitment document, ensuring the high-level intent is preserved. These structural priors then guide an iterative multi-agent refinement process, where specialized agents iteratively critique and revise the presentation outline before rendering the final visual layouts and designs. To evaluate our approach, we also introduce ArcBench, a newly curated benchmark of academic paper-slide pairs. Experimental results demonstrate that explicit discourse modeling, combined with role-specific agent coordination, significantly improves the narrative flow and logical coherence of the generated presentations.
Compass Control: Multi Object Orientation Control for Text-to-Image Generation
Apr 10, 2025
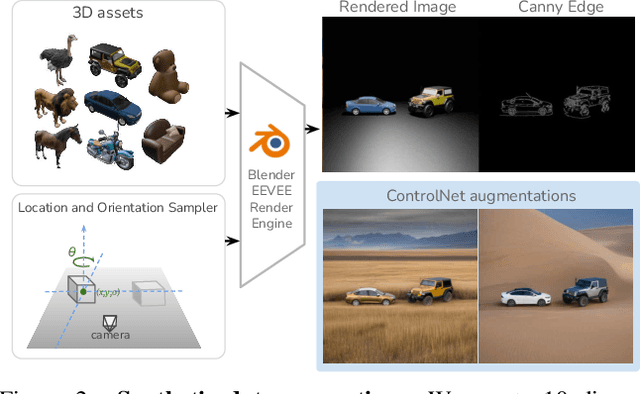
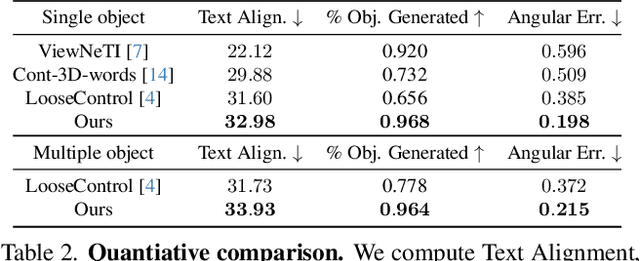
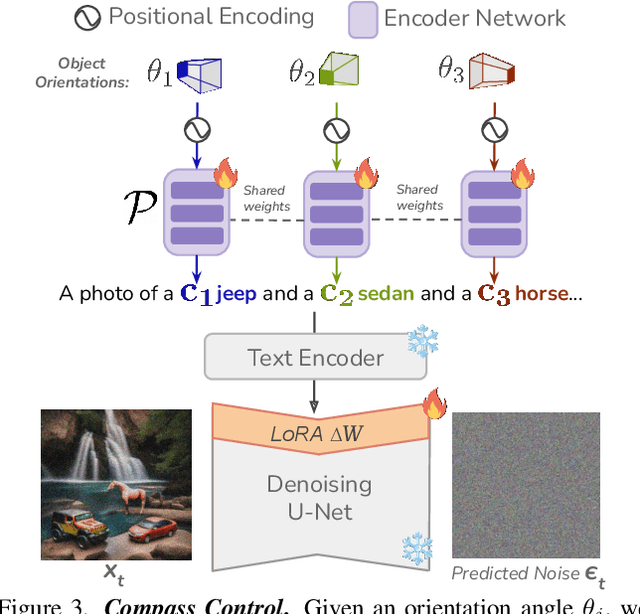
Existing approaches for controlling text-to-image diffusion models, while powerful, do not allow for explicit 3D object-centric control, such as precise control of object orientation. In this work, we address the problem of multi-object orientation control in text-to-image diffusion models. This enables the generation of diverse multi-object scenes with precise orientation control for each object. The key idea is to condition the diffusion model with a set of orientation-aware \textbf{compass} tokens, one for each object, along with text tokens. A light-weight encoder network predicts these compass tokens taking object orientation as the input. The model is trained on a synthetic dataset of procedurally generated scenes, each containing one or two 3D assets on a plain background. However, direct training this framework results in poor orientation control as well as leads to entanglement among objects. To mitigate this, we intervene in the generation process and constrain the cross-attention maps of each compass token to its corresponding object regions. The trained model is able to achieve precise orientation control for a) complex objects not seen during training and b) multi-object scenes with more than two objects, indicating strong generalization capabilities. Further, when combined with personalization methods, our method precisely controls the orientation of the new object in diverse contexts. Our method achieves state-of-the-art orientation control and text alignment, quantified with extensive evaluations and a user study.
PreciseControl: Enhancing Text-To-Image Diffusion Models with Fine-Grained Attribute Control
Jul 24, 2024Recently, we have seen a surge of personalization methods for text-to-image (T2I) diffusion models to learn a concept using a few images. Existing approaches, when used for face personalization, suffer to achieve convincing inversion with identity preservation and rely on semantic text-based editing of the generated face. However, a more fine-grained control is desired for facial attribute editing, which is challenging to achieve solely with text prompts. In contrast, StyleGAN models learn a rich face prior and enable smooth control towards fine-grained attribute editing by latent manipulation. This work uses the disentangled $\mathcal{W+}$ space of StyleGANs to condition the T2I model. This approach allows us to precisely manipulate facial attributes, such as smoothly introducing a smile, while preserving the existing coarse text-based control inherent in T2I models. To enable conditioning of the T2I model on the $\mathcal{W+}$ space, we train a latent mapper to translate latent codes from $\mathcal{W+}$ to the token embedding space of the T2I model. The proposed approach excels in the precise inversion of face images with attribute preservation and facilitates continuous control for fine-grained attribute editing. Furthermore, our approach can be readily extended to generate compositions involving multiple individuals. We perform extensive experiments to validate our method for face personalization and fine-grained attribute editing.
Text2Place: Affordance-aware Text Guided Human Placement
Jul 22, 2024For a given scene, humans can easily reason for the locations and pose to place objects. Designing a computational model to reason about these affordances poses a significant challenge, mirroring the intuitive reasoning abilities of humans. This work tackles the problem of realistic human insertion in a given background scene termed as \textbf{Semantic Human Placement}. This task is extremely challenging given the diverse backgrounds, scale, and pose of the generated person and, finally, the identity preservation of the person. We divide the problem into the following two stages \textbf{i)} learning \textit{semantic masks} using text guidance for localizing regions in the image to place humans and \textbf{ii)} subject-conditioned inpainting to place a given subject adhering to the scene affordance within the \textit{semantic masks}. For learning semantic masks, we leverage rich object-scene priors learned from the text-to-image generative models and optimize a novel parameterization of the semantic mask, eliminating the need for large-scale training. To the best of our knowledge, we are the first ones to provide an effective solution for realistic human placements in diverse real-world scenes. The proposed method can generate highly realistic scene compositions while preserving the background and subject identity. Further, we present results for several downstream tasks - scene hallucination from a single or multiple generated persons and text-based attribute editing. With extensive comparisons against strong baselines, we show the superiority of our method in realistic human placement.
Robustness Analysis on Foundational Segmentation Models
Jun 15, 2023



Due to the increase in computational resources and accessibility of data, an increase in large, deep learning models trained on copious amounts of data using self-supervised or semi-supervised learning have emerged. These "foundation" models are often adapted to a variety of downstream tasks like classification, object detection, and segmentation with little-to-no training on the target dataset. In this work, we perform a robustness analysis of Visual Foundation Models (VFMs) for segmentation tasks and compare them to supervised models of smaller scale. We focus on robustness against real-world distribution shift perturbations.We benchmark four state-of-the-art segmentation architectures using 2 different datasets, COCO and ADE20K, with 17 different perturbations with 5 severity levels each. We find interesting insights that include (1) VFMs are not robust to compression-based corruptions, (2) while the selected VFMs do not significantly outperform or exhibit more robustness compared to non-VFM models, they remain competitively robust in zero-shot evaluations, particularly when non-VFM are under supervision and (3) selected VFMs demonstrate greater resilience to specific categories of objects, likely due to their open-vocabulary training paradigm, a feature that non-VFM models typically lack. We posit that the suggested robustness evaluation introduces new requirements for foundational models, thus sparking further research to enhance their performance.