 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUCID: Learning Embodiment-Agnostic Intent Models from Unstructured Human Videos for Scalable Dexterous Robot Skill Acquisition
Jun 10, 2026The most widely-adopted robot learning pipelines today learn skills from robot demonstrations or structured human data, which are expensive to collect and tied to specific embodiments. In contrast, unstructured human videos provide a scalable alternative. They contain diverse manipulation demonstrations across objects, scenes, and strategies, but are not directly connected to robot action. We propose LUCID, a two-stage framework that learns task intent from unstructured human videos drawn from internet-scale datasets and learns robot control in massively-parallel simulation. The intent model predicts short-horizon intent (what should happen next in the scene) from the current observation in closed loop. An embodiment-specific sensorimotor policy converts this intent into robot actions. The intent interface is shared across controllers, so the same intent model can be applied to different embodiments, from our primary dexterous hand to a parallel-jaw gripper. We evaluate LUCID on five real-world manipulation tasks: stirring, wiping, and binning supervised by only internet video, with zero-shot transfer to novel scenes and object instances; and push-T and cable routing supervised by 1 hr each of self-collected smartphone video. Project page: https://lucid-robot.github.io/.
Grasp to Act: Dexterous Grasping for Tool Use in Dynamic Settings
Feb 24, 2026Achieving robust grasping with dexterous hands remains challenging, especially when manipulation involves dynamic forces such as impacts, torques, and continuous resistance--situations common in real-world tool use. Existing methods largely optimize grasps for static geometric stability and often fail once external forces arise during manipulation. We present Grasp-to-Act, a hybrid system that combines physics-based grasp optimization with reinforcement-learning-based grasp adaptation to maintain stable grasps throughout functional manipulation tasks. Our method synthesizes robust grasp configurations informed by human demonstrations and employs an adaptive controller that residually issues joint corrections to prevent in-hand slip while tracking the object trajectory. Grasp-to-Act enables robust zero-shot sim-to-real transfer across five dynamic tool-use tasks--hammering, sawing, cutting, stirring, and scooping--consistently outperforming baselines. Across simulation and real-world hardware trials with a 16-DoF dexterous hand, our method reduces translational and rotational in-hand slip and achieves the highest task completion rates, demonstrating stable functional grasps under dynamic, contact-rich conditions.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Sensor-Invariant Tactile Representation
Feb 27, 2025High-resolution tactile sensors have become critical for embodied perception and robotic manipulation. However, a key challenge in the field is the lack of transferability between sensors due to design and manufacturing variations, which result in significant differences in tactile signals. This limitation hinders the ability to transfer models or knowledge learned from one sensor to another. To address this, we introduce a novel method for extracting Sensor-Invariant Tactile Representations (SITR), enabling zero-shot transfer across optical tactile sensors. Our approach utilizes a transformer-based architecture trained on a diverse dataset of simulated sensor designs, allowing it to generalize to new sensors in the real world with minimal calibration. Experimental results demonstrate the method's effectiveness across various tactile sensing applications, facilitating data and model transferability for future advancements in the field.
Text2Place: Affordance-aware Text Guided Human Placement
Jul 22, 2024For a given scene, humans can easily reason for the locations and pose to place objects. Designing a computational model to reason about these affordances poses a significant challenge, mirroring the intuitive reasoning abilities of humans. This work tackles the problem of realistic human insertion in a given background scene termed as \textbf{Semantic Human Placement}. This task is extremely challenging given the diverse backgrounds, scale, and pose of the generated person and, finally, the identity preservation of the person. We divide the problem into the following two stages \textbf{i)} learning \textit{semantic masks} using text guidance for localizing regions in the image to place humans and \textbf{ii)} subject-conditioned inpainting to place a given subject adhering to the scene affordance within the \textit{semantic masks}. For learning semantic masks, we leverage rich object-scene priors learned from the text-to-image generative models and optimize a novel parameterization of the semantic mask, eliminating the need for large-scale training. To the best of our knowledge, we are the first ones to provide an effective solution for realistic human placements in diverse real-world scenes. The proposed method can generate highly realistic scene compositions while preserving the background and subject identity. Further, we present results for several downstream tasks - scene hallucination from a single or multiple generated persons and text-based attribute editing. With extensive comparisons against strong baselines, we show the superiority of our method in realistic human placement.
Cross-Geography Generalization of Machine Learning Methods for Classification of Flooded Regions in Aerial Images
Oct 04, 2022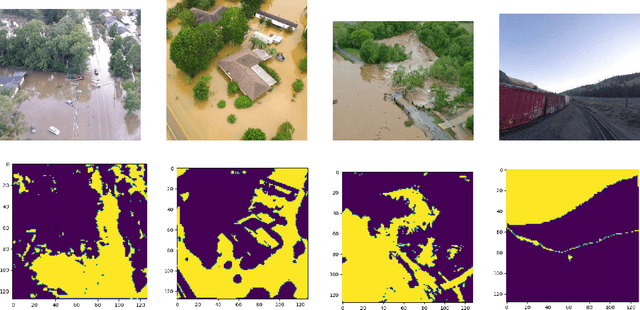
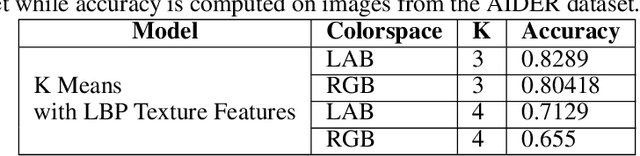
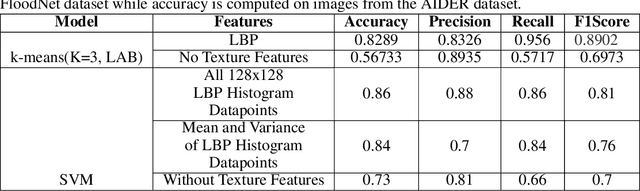
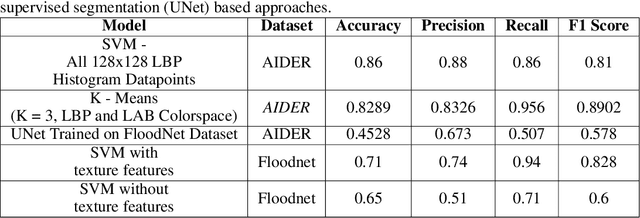
Identification of regions affected by floods is a crucial piece of information required for better planning and management of post-disaster relief and rescue efforts. Traditionally, remote sensing images are analysed to identify the extent of damage caused by flooding. The data acquired from sensors onboard earth observation satellites are analyzed to detect the flooded regions, which can be affected by low spatial and temporal resolution. However, in recent years, the images acquired from Unmanned Aerial Vehicles (UAVs) have also been utilized to assess post-disaster damage. Indeed, a UAV based platform can be rapidly deployed with a customized flight plan and minimum dependence on the ground infrastructure. This work proposes two approaches for identifying flooded regions in UAV aerial images. The first approach utilizes texture-based unsupervised segmentation to detect flooded areas, while the second uses an artificial neural network on the texture features to classify images as flooded and non-flooded. Unlike the existing works where the models are trained and tested on images of the same geographical regions, this work studies the performance of the proposed model in identifying flooded regions across geographical regions. An F1-score of 0.89 is obtained using the proposed segmentation-based approach which is higher than existing classifiers. The robustness of the proposed approach demonstrates that it can be utilized to identify flooded regions of any region with minimum or no user intervention.
Combining Reinforcement Learning with Model Predictive Control for On-Ramp Merging
Nov 17, 2020
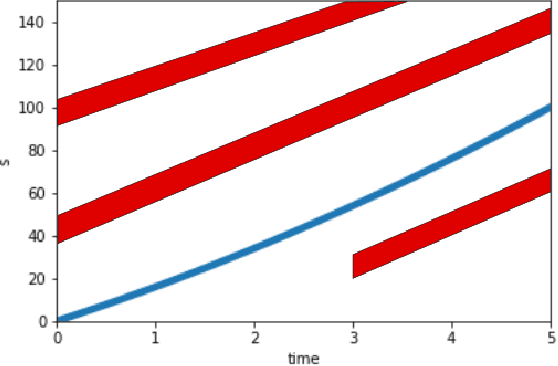
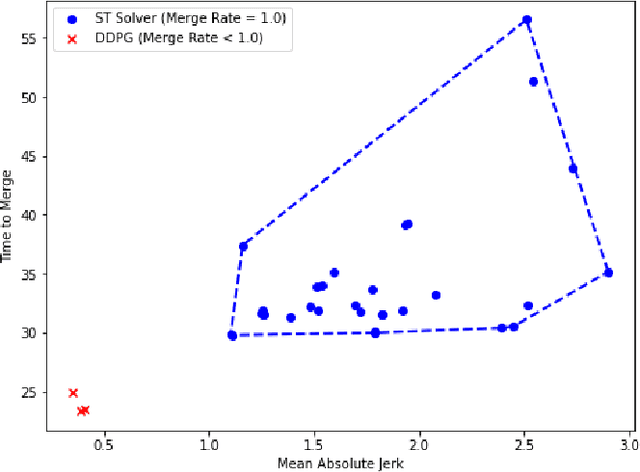
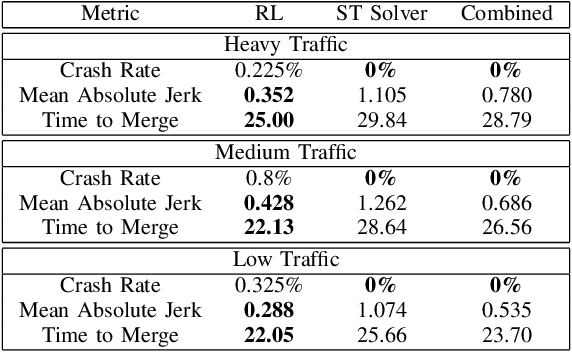
We consider the problem of designing an algorithm to allow a car to autonomously merge on to a highway from an on-ramp. Two broad classes of techniques have been proposed to solve motion planning problems in autonomous driving: Model Predictive Control (MPC) and Reinforcement Learning (RL). In this paper, we first establish the strengths and weaknesses of state-of-the-art MPC and RL-based techniques through simulations. We show that the performance of the RL agent is worse than that of the MPC solution from the perspective of safety and robustness to out-of-distribution traffic patterns, i.e., traffic patterns which were not seen by the RL agent during training. On the other hand, the performance of the RL agent is better than that of the MPC solution when it comes to efficiency and passenger comfort. We subsequently present an algorithm which blends the model-free RL agent with the MPC solution and show that it provides better trade-offs between all metrics -- passenger comfort, efficiency, crash rate and robustness.
Provably-Efficient Double Q-Learning
Jul 09, 2020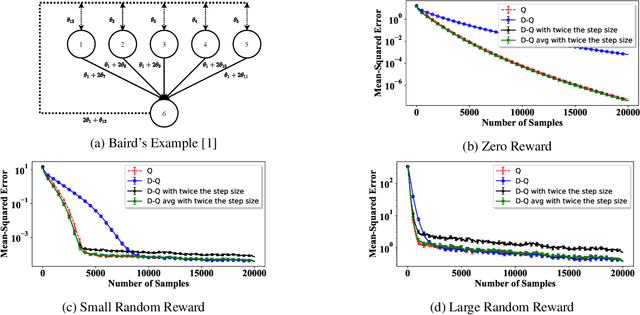
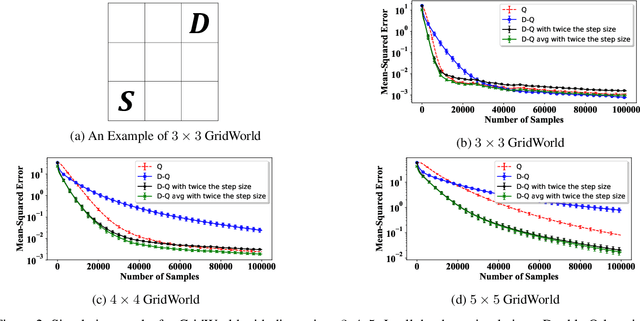

In this paper, we establish a theoretical comparison between the asymptotic mean-squared error of Double Q-learning and Q-learning. Our result builds upon an analysis for linear stochastic approximation based on Lyapunov equations and applies to both tabular setting and with linear function approximation, provided that the optimal policy is unique and the algorithms converge. We show that the asymptotic mean-squared error of Double Q-learning is exactly equal to that of Q-learning if Double Q-learning uses twice the learning rate of Q-learning and outputs the average of its two estimators. We also present some practical implications of this theoretical observation using simulations.
Mixed Logit Models and Network Formation
Jun 30, 2020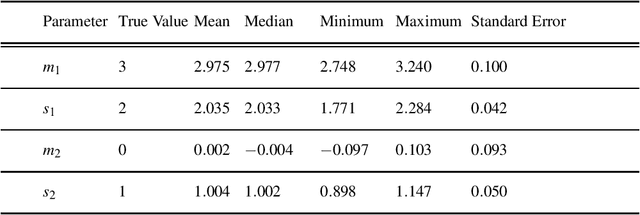
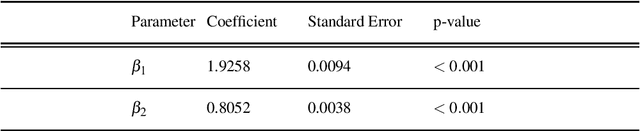
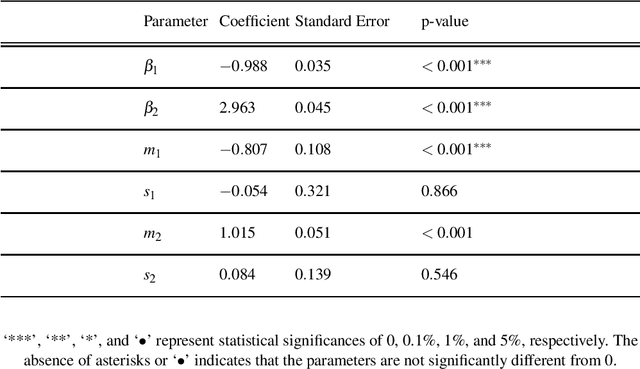
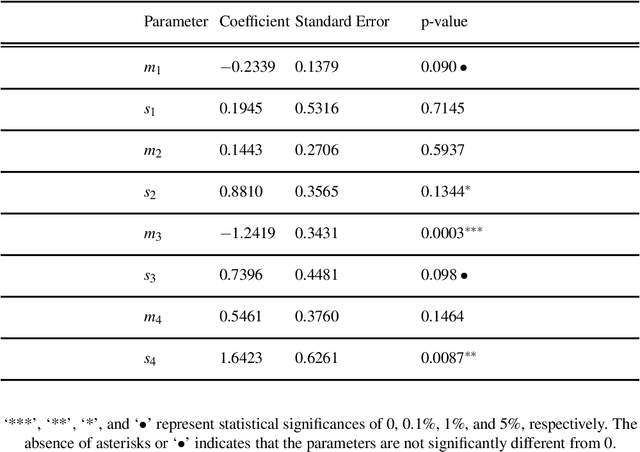
The study of network formation is pervasive in economics, sociology, and many other fields. In this paper, we model network formation as a ``choice'' that is made by nodes in a network to connect to other nodes. We study these ``choices'' using discrete-choice models, in which an agent chooses between two or more discrete alternatives. One framework for studying network formation is the multinomial logit (MNL) model. We highlight limitations of the MNL model on networks that are constructed from empirical data. We employ the ``repeated choice'' (RC) model to study network formation \cite{TrainRevelt97mixedlogit}. We argue that the RC model overcomes important limitations of the MNL model and is well-suited to study network formation. We also illustrate how to use the RC model to accurately study network formation using both synthetic and real-world networks. Using synthetic networks, we also compare the performance of the MNL model and the RC model; we find that the RC model estimates the data-generation process of our synthetic networks more accurately than the MNL model. We provide examples of qualitatively interesting questions -- the presence of homophily in a teen friendship network and the fact that new patents are more likely to cite older, more cited, and similar patents -- for which the RC model allows us to achieve insights.
Finite-Time Performance Bounds and Adaptive Learning Rate Selection for Two Time-Scale Reinforcement Learning
Jul 14, 2019
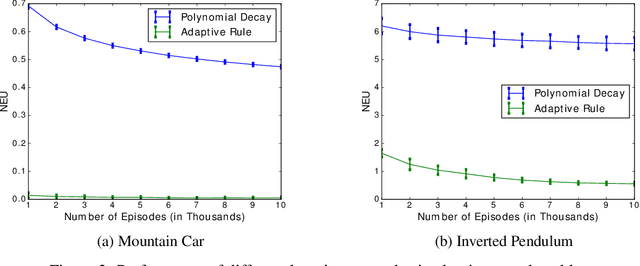
We study two time-scale linear stochastic approximation algorithms, which can be used to model well-known reinforcement learning algorithms such as GTD, GTD2, and TDC. We present finite-time performance bounds for the case where the learning rate is fixed. The key idea in obtaining these bounds is to use a Lyapunov function motivated by singular perturbation theory for linear differential equations. We use the bound to design an adaptive learning rate scheme which significantly improves the convergence rate over the known optimal polynomial decay rule in our experiments, and can be used to potentially improve the performance of any other schedule where the learning rate is changed at pre-determined time instants.