 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Vehicle Trajectory Planning for Static Obstacle Avoidance using Nonlinear Optimization
Jul 18, 2023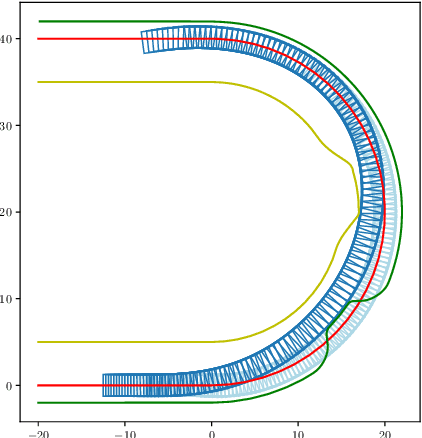
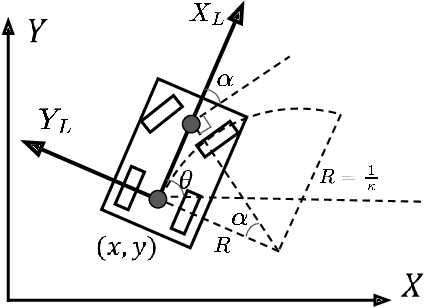
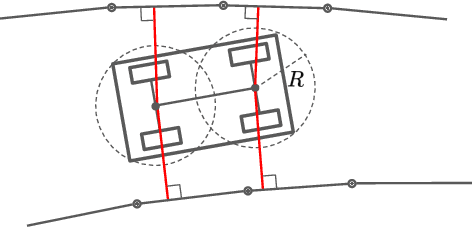
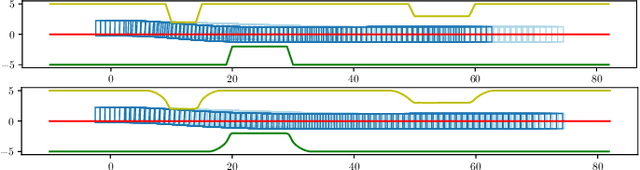
Vehicle trajectory planning is a key component for an autonomous driving system. A practical system not only requires the component to compute a feasible trajectory, but also a comfortable one given certain comfort metrics. Nevertheless, computation efficiency is critical for the system to be deployed as a commercial product. In this paper, we present a novel trajectory planning algorithm based on nonlinear optimization. The algorithm computes a kinematically feasible and comfort-optimal trajectory that achieves collision avoidance with static obstacles. Furthermore, the algorithm is time efficient. It generates an 6-second trajectory within 10 milliseconds on an Intel i7 machine or 20 milliseconds on an Nvidia Drive Orin platform.
Interactive Trajectory Planner for Mandatory Lane Changing in Dense Non-Cooperative Traffic
Mar 04, 2023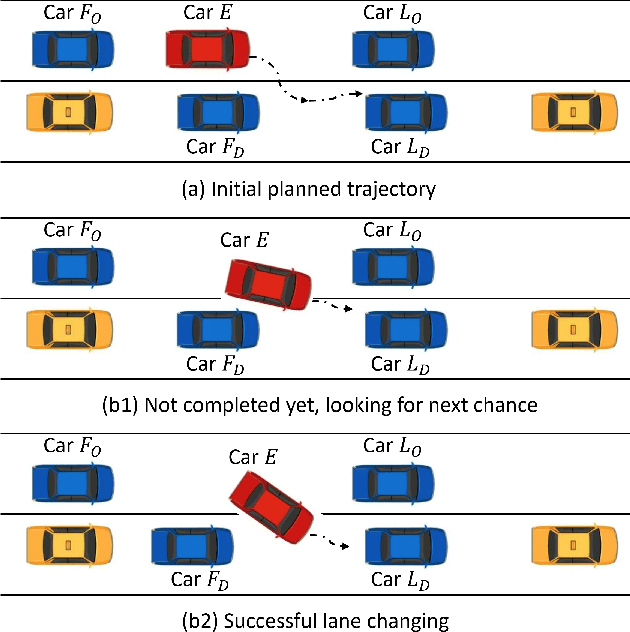
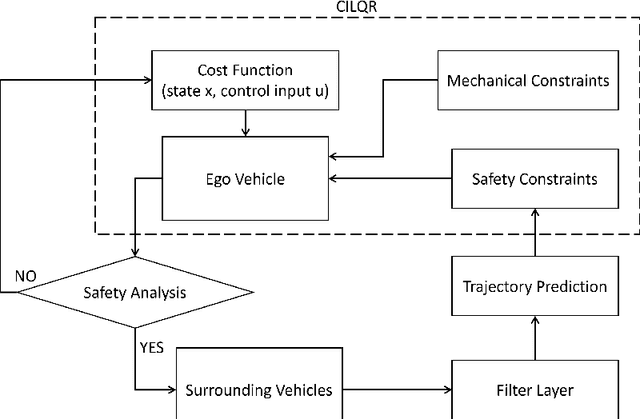
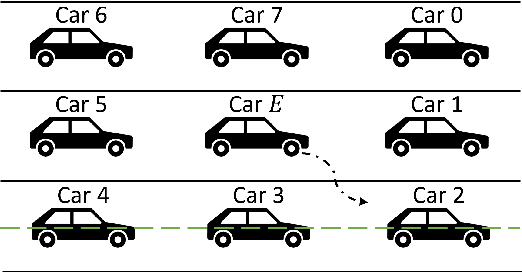
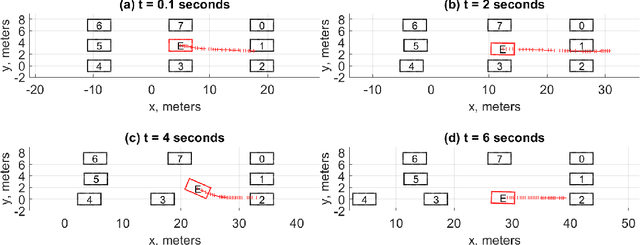
When the traffic stream is extremely congested and surrounding vehicles are not cooperative, the mandatory lane changing can be significantly difficult. In this work, we propose an interactive trajectory planner, which will firstly attempt to change lanes as long as safety is ensured. Based on receding horizon planning, the ego vehicle can abort or continue changing lanes according to surrounding vehicles' reactions. We demonstrate the performance of our planner in extensive simulations with eight surrounding vehicles, initial velocity ranging from 0.5 to 5 meters per second, and bumper to bumper gap ranging from 4 to 10 meters. The ego vehicle with our planner can change lanes safely and smoothly. The computation time of the planner at every step is within 10 milliseconds in most cases on a laptop with 1.8GHz Intel Core i7-10610U.
Combining Reinforcement Learning with Model Predictive Control for On-Ramp Merging
Nov 17, 2020
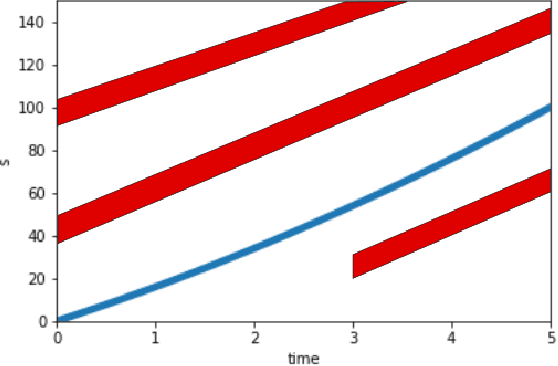
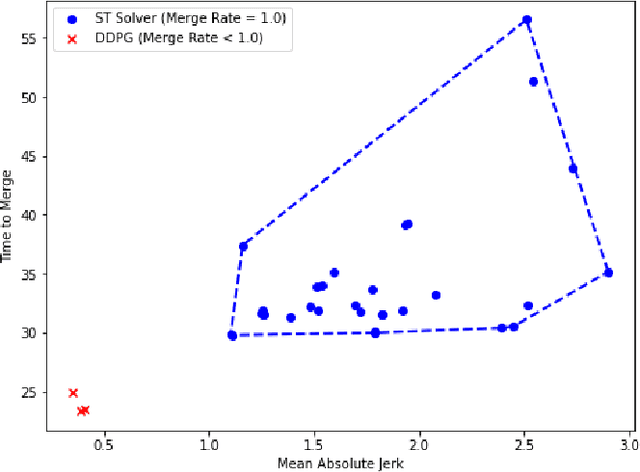
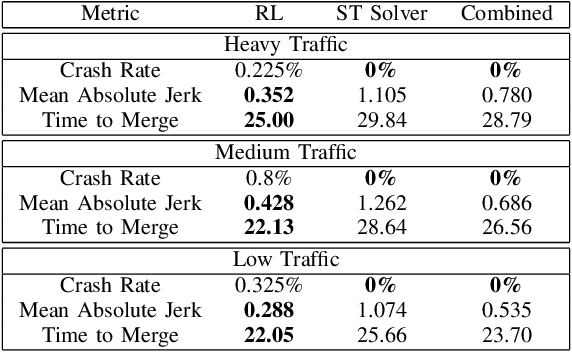
We consider the problem of designing an algorithm to allow a car to autonomously merge on to a highway from an on-ramp. Two broad classes of techniques have been proposed to solve motion planning problems in autonomous driving: Model Predictive Control (MPC) and Reinforcement Learning (RL). In this paper, we first establish the strengths and weaknesses of state-of-the-art MPC and RL-based techniques through simulations. We show that the performance of the RL agent is worse than that of the MPC solution from the perspective of safety and robustness to out-of-distribution traffic patterns, i.e., traffic patterns which were not seen by the RL agent during training. On the other hand, the performance of the RL agent is better than that of the MPC solution when it comes to efficiency and passenger comfort. We subsequently present an algorithm which blends the model-free RL agent with the MPC solution and show that it provides better trade-offs between all metrics -- passenger comfort, efficiency, crash rate and robustness.