 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Self-regulated Learning Sequences within a Generative AI-based Intelligent Tutoring System
Jan 13, 2026There has been a growing trend in employing generative artificial intelligence (GenAI) techniques to support learning. Moreover, scholars have reached a consensus on the critical role of self-regulated learning (SRL) in ensuring learning effectiveness within GenAI-assisted learning environments, making it essential to capture students' dynamic SRL patterns. In this study, we extracted students' interaction patterns with GenAI from trace data as they completed a problem-solving task within a GenAI-assisted intelligent tutoring system. Students' purpose of using GenAI was also analyzed from the perspective of information processing, i.e., information acquisition and information transformation. Using sequential and clustering analysis, this study classified participants into two groups based on their SRL sequences. These two groups differed in the frequency and temporal characteristics of GenAI use. In addition, most students used GenAI for information acquisition rather than information transformation, while the correlation between the purpose of using GenAI and learning performance was not statistically significant. Our findings inform both pedagogical design and the development of GenAI-assisted learning environments.
Frequency-based Matcher for Long-tailed Semantic Segmentation
Jun 06, 2024
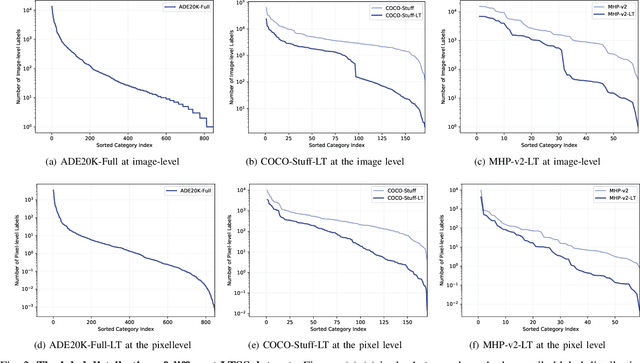
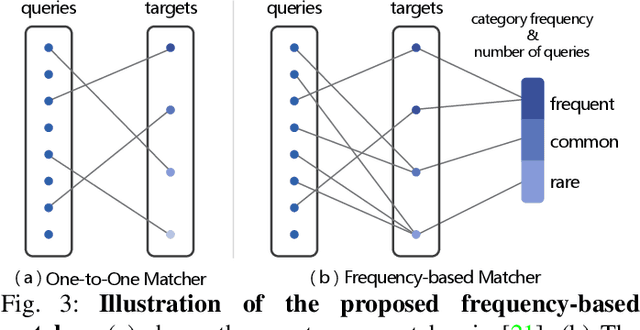
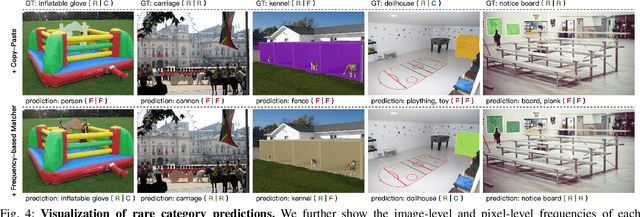
The successful application of semantic segmentation technology in the real world has been among the most exciting achievements in the computer vision community over the past decade. Although the long-tailed phenomenon has been investigated in many fields, e.g., classification and object detection, it has not received enough attention in semantic segmentation and has become a non-negligible obstacle to applying semantic segmentation technology in autonomous driving and virtual reality. Therefore, in this work, we focus on a relatively under-explored task setting, long-tailed semantic segmentation (LTSS). We first establish three representative datasets from different aspects, i.e., scene, object, and human. We further propose a dual-metric evaluation system and construct the LTSS benchmark to demonstrate the performance of semantic segmentation methods and long-tailed solutions. We also propose a transformer-based algorithm to improve LTSS, frequency-based matcher, which solves the oversuppression problem by one-to-many matching and automatically determines the number of matching queries for each class. Given the comprehensiveness of this work and the importance of the issues revealed, this work aims to promote the empirical study of semantic segmentation tasks. Our datasets, codes, and models will be publicly available.
CloudFort: Enhancing Robustness of 3D Point Cloud Classification Against Backdoor Attacks via Spatial Partitioning and Ensemble Prediction
Apr 22, 2024



The increasing adoption of 3D point cloud data in various applications, such as autonomous vehicles, robotics, and virtual reality, has brought about significant advancements in object recognition and scene understanding. However, this progress is accompanied by new security challenges, particularly in the form of backdoor attacks. These attacks involve inserting malicious information into the training data of machine learning models, potentially compromising the model's behavior. In this paper, we propose CloudFort, a novel defense mechanism designed to enhance the robustness of 3D point cloud classifiers against backdoor attacks. CloudFort leverages spatial partitioning and ensemble prediction techniques to effectively mitigate the impact of backdoor triggers while preserving the model's performance on clean data. We evaluate the effectiveness of CloudFort through extensive experiments, demonstrating its strong resilience against the Point Cloud Backdoor Attack (PCBA). Our results show that CloudFort significantly enhances the security of 3D point cloud classification models without compromising their accuracy on benign samples. Furthermore, we explore the limitations of CloudFort and discuss potential avenues for future research in the field of 3D point cloud security. The proposed defense mechanism represents a significant step towards ensuring the trustworthiness and reliability of point-cloud-based systems in real-world applications.
PikeLPN: Mitigating Overlooked Inefficiencies of Low-Precision Neural Networks
Mar 29, 2024Low-precision quantization is recognized for its efficacy in neural network optimization. Our analysis reveals that non-quantized elementwise operations which are prevalent in layers such as parameterized activation functions, batch normalization, and quantization scaling dominate the inference cost of low-precision models. These non-quantized elementwise operations are commonly overlooked in SOTA efficiency metrics such as Arithmetic Computation Effort (ACE). In this paper, we propose ACEv2 - an extended version of ACE which offers a better alignment with the inference cost of quantized models and their energy consumption on ML hardware. Moreover, we introduce PikeLPN, a model that addresses these efficiency issues by applying quantization to both elementwise operations and multiply-accumulate operations. In particular, we present a novel quantization technique for batch normalization layers named QuantNorm which allows for quantizing the batch normalization parameters without compromising the model performance. Additionally, we propose applying Double Quantization where the quantization scaling parameters are quantized. Furthermore, we recognize and resolve the issue of distribution mismatch in Separable Convolution layers by introducing Distribution-Heterogeneous Quantization which enables quantizing them to low-precision. PikeLPN achieves Pareto-optimality in efficiency-accuracy trade-off with up to 3X efficiency improvement compared to SOTA low-precision models.
FairSample: Training Fair and Accurate Graph Convolutional Neural Networks Efficiently
Jan 26, 2024



Fairness in Graph Convolutional Neural Networks (GCNs) becomes a more and more important concern as GCNs are adopted in many crucial applications. Societal biases against sensitive groups may exist in many real world graphs. GCNs trained on those graphs may be vulnerable to being affected by such biases. In this paper, we adopt the well-known fairness notion of demographic parity and tackle the challenge of training fair and accurate GCNs efficiently. We present an in-depth analysis on how graph structure bias, node attribute bias, and model parameters may affect the demographic parity of GCNs. Our insights lead to FairSample, a framework that jointly mitigates the three types of biases. We employ two intuitive strategies to rectify graph structures. First, we inject edges across nodes that are in different sensitive groups but similar in node features. Second, to enhance model fairness and retain model quality, we develop a learnable neighbor sampling policy using reinforcement learning. To address the bias in node features and model parameters, FairSample is complemented by a regularization objective to optimize fairness.
Optimal Vehicle Trajectory Planning for Static Obstacle Avoidance using Nonlinear Optimization
Jul 18, 2023
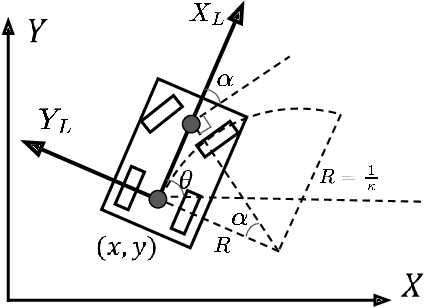
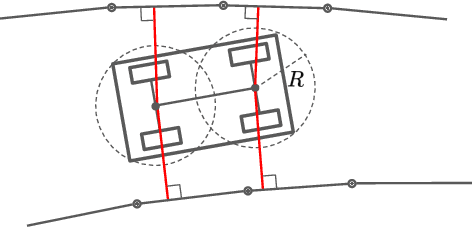
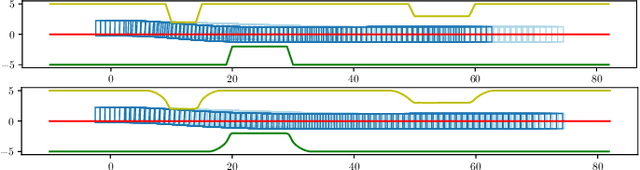
Vehicle trajectory planning is a key component for an autonomous driving system. A practical system not only requires the component to compute a feasible trajectory, but also a comfortable one given certain comfort metrics. Nevertheless, computation efficiency is critical for the system to be deployed as a commercial product. In this paper, we present a novel trajectory planning algorithm based on nonlinear optimization. The algorithm computes a kinematically feasible and comfort-optimal trajectory that achieves collision avoidance with static obstacles. Furthermore, the algorithm is time efficient. It generates an 6-second trajectory within 10 milliseconds on an Intel i7 machine or 20 milliseconds on an Nvidia Drive Orin platform.
Interactive Trajectory Planner for Mandatory Lane Changing in Dense Non-Cooperative Traffic
Mar 04, 2023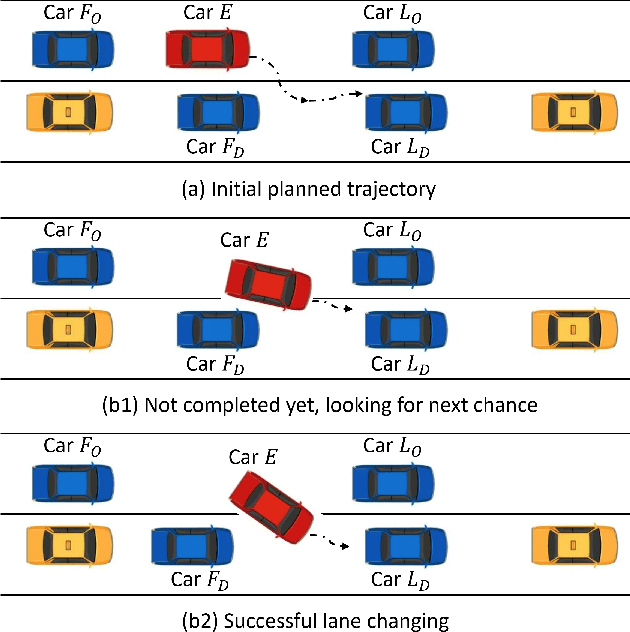
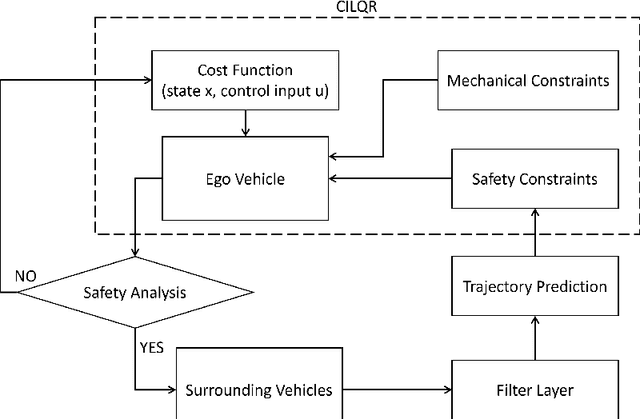
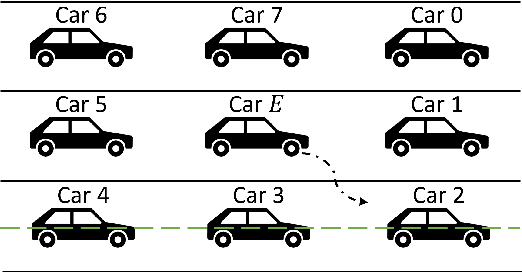
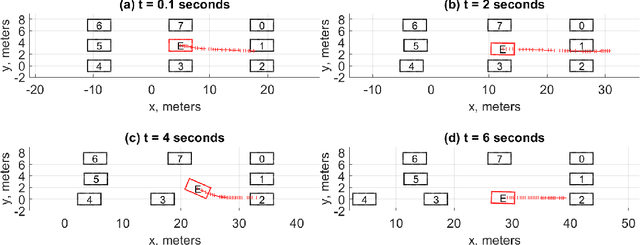
When the traffic stream is extremely congested and surrounding vehicles are not cooperative, the mandatory lane changing can be significantly difficult. In this work, we propose an interactive trajectory planner, which will firstly attempt to change lanes as long as safety is ensured. Based on receding horizon planning, the ego vehicle can abort or continue changing lanes according to surrounding vehicles' reactions. We demonstrate the performance of our planner in extensive simulations with eight surrounding vehicles, initial velocity ranging from 0.5 to 5 meters per second, and bumper to bumper gap ranging from 4 to 10 meters. The ego vehicle with our planner can change lanes safely and smoothly. The computation time of the planner at every step is within 10 milliseconds in most cases on a laptop with 1.8GHz Intel Core i7-10610U.
What Decreases Editing Capability? Domain-Specific Hybrid Refinement for Improved GAN Inversion
Jan 28, 2023Recently, inversion methods have focused on additional high-rate information in the generator (e.g., weights or intermediate features) to refine inversion and editing results from embedded latent codes. Although these techniques gain reasonable improvement in reconstruction, they decrease editing capability, especially on complex images (e.g., containing occlusions, detailed backgrounds, and artifacts). A vital crux is refining inversion results, avoiding editing capability degradation. To tackle this problem, we introduce Domain-Specific Hybrid Refinement (DHR), which draws on the advantages and disadvantages of two mainstream refinement techniques to maintain editing ability with fidelity improvement. Specifically, we first propose Domain-Specific Segmentation to segment images into two parts: in-domain and out-of-domain parts. The refinement process aims to maintain the editability for in-domain areas and improve two domains' fidelity. We refine these two parts by weight modulation and feature modulation, which we call Hybrid Modulation Refinement. Our proposed method is compatible with all latent code embedding methods. Extension experiments demonstrate that our approach achieves state-of-the-art in real image inversion and editing. Code is available at https://github.com/caopulan/Domain-Specific_Hybrid_Refinement_Inversion.
Deep Learning Technique for Human Parsing: A Survey and Outlook
Jan 01, 2023Human parsing aims to partition humans in image or video into multiple pixel-level semantic parts. In the last decade, it has gained significantly increased interest in the computer vision community and has been utilized in a broad range of practical applications, from security monitoring, to social media, to visual special effects, just to name a few. Although deep learning-based human parsing solutions have made remarkable achievements, many important concepts, existing challenges, and potential research directions are still confusing. In this survey, we comprehensively review three core sub-tasks: single human parsing, multiple human parsing, and video human parsing, by introducing their respective task settings, background concepts, relevant problems and applications, representative literature, and datasets. We also present quantitative performance comparisons of the reviewed methods on benchmark datasets. Additionally, to promote sustainable development of the community, we put forward a transformer-based human parsing framework, providing a high-performance baseline for follow-up research through universal, concise, and extensible solutions. Finally, we point out a set of under-investigated open issues in this field and suggest new directions for future study. We also provide a regularly updated project page, to continuously track recent developments in this fast-advancing field: https://github.com/soeaver/awesome-human-parsing.
LSAP: Rethinking Inversion Fidelity, Perception and Editability in GAN Latent Space
Sep 26, 2022



As the methods evolve, inversion is mainly divided into two steps. The first step is Image Embedding, in which an encoder or optimization process embeds images to get the corresponding latent codes. Afterward, the second step aims to refine the inversion and editing results, which we named Result Refinement. Although the second step significantly improves fidelity, perception and editability are almost unchanged, deeply dependent on inverse latent codes attained in the first step. Therefore, a crucial problem is gaining the latent codes with better perception and editability while retaining the reconstruction fidelity. In this work, we first point out that these two characteristics are related to the degree of alignment (or disalignment) of the inverse codes with the synthetic distribution. Then, we propose Latent Space Alignment Inversion Paradigm (LSAP), which consists of evaluation metric and solution for this problem. Specifically, we introduce Normalized Style Space ($\mathcal{S^N}$ space) and $\mathcal{S^N}$ Cosine Distance (SNCD) to measure disalignment of inversion methods. Since our proposed SNCD is differentiable, it can be optimized in both encoder-based and optimization-based embedding methods to conduct a uniform solution. Extensive experiments in various domains demonstrate that SNCD effectively reflects perception and editability, and our alignment paradigm archives the state-of-the-art in both two steps. Code is available on https://github.com/caopulan/GANInverter.